This function characterized the output layer of almost all classification networks, as it can immediately represent a discrete probability distribution. If there are k outputs yi, the softmax is computed as follows:
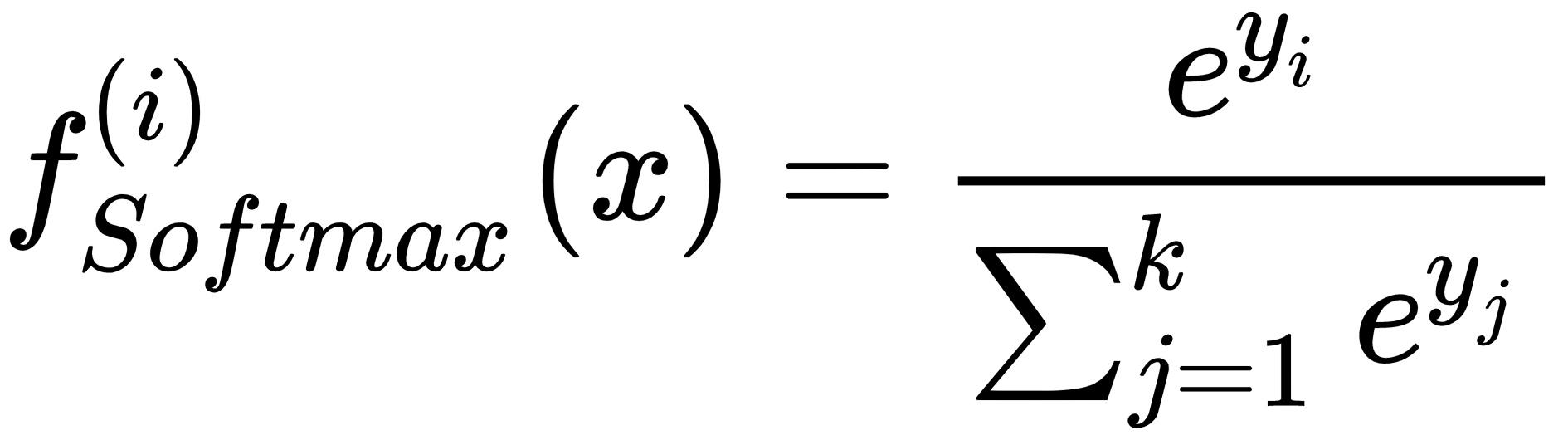
In this way, the output of a layer containing k neurons is normalized so that the sum is always 1. It goes without saying that, in this case, the best cost function is the cross-entropy. In fact, if all true labels are represented with a one-hot encoding, they implicitly become probability vectors with 1 corresponding to the true class. The goal of the classifier is hence to reduce the discrepancy between the training distribution ...

