Many algorithms show better performances (above all, in terms of training speed) when the dataset is symmetric (with a zero-mean). Therefore, one of the most important preprocessing steps is so-called zero-centering, which consists in subtracting the feature-wise mean Ex[X] from all samples:
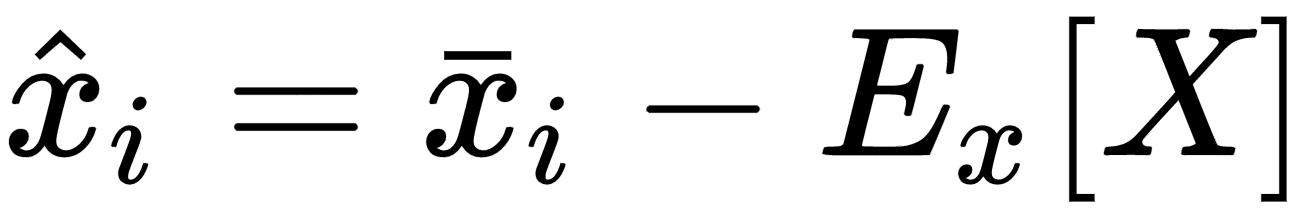
This operation, if necessary, is normally reversible, and doesn't alter relationships both among samples and among components of the same sample. In deep learning scenarios, a zero-centered dataset allows exploiting the symmetry of some activation function, driving to a faster convergence (we're going to discuss these details ...

