If we consider an image X ∈ ℜw × h (single channel) and a kernel k ∈ ℜn × m, the number of operations is nmwh. When the kernel is not very small and the image is large, the cost of this computation can be quite high, even with GPU support. An improvement can be achieved by taking into account the associated property of convolutions. In particular, if the original kernel can be split into the dot product of two vectorial kernels, k(1) with dimensions (n × 1) and k(2) with dimensions (1 × m), the convolution is said to be separable. This means that we can perform a (n × m) convolution with two subsequent operations:
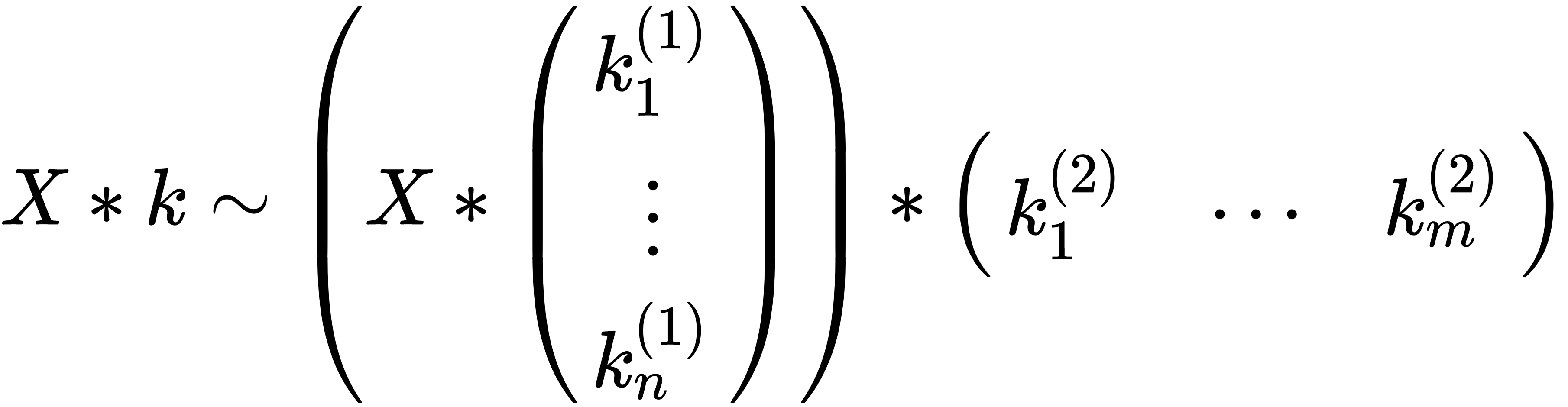
The ...

