This algorithm has been proposed by Duchi, Hazan, and Singer (in Adaptive Subgradient Methods for Online Learning and Stochastic Optimizatioln, Duchi J., Hazan E., Singer Y., Journal of Machine Learning Research 12/2011). The idea is very similar to RMSProp, but, in this case, the whole history of the squared gradients is taken into account:
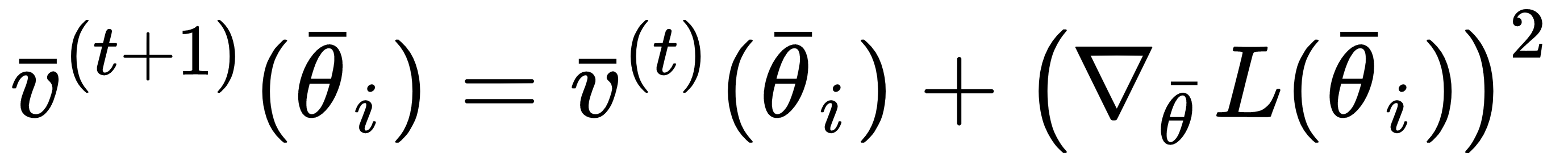
The weights are updated exactly like in RMSProp:
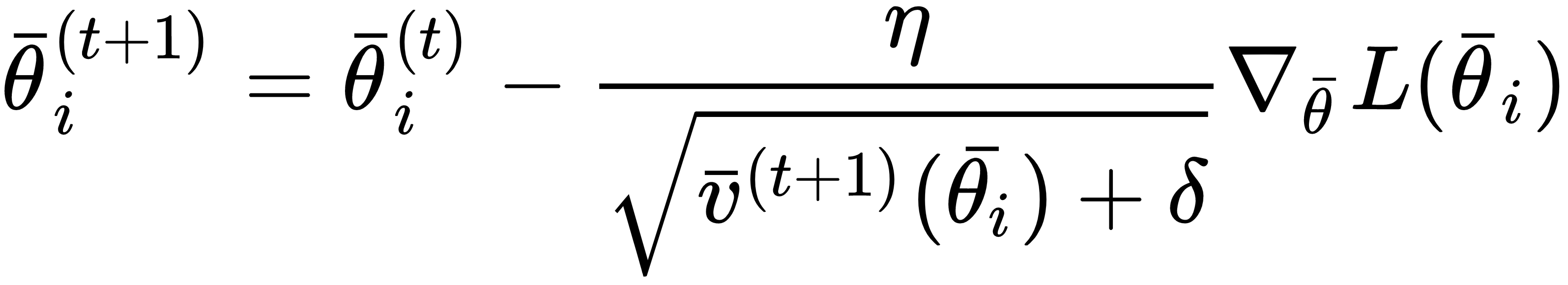
However, as the squared gradients are non-negative, the implicit sum v(t)(•) → ∞ when t → ∞. As the growth continues until the gradients are non-null, ...

