Let's suppose we have a data generating process pdata, used to draw a dataset X:
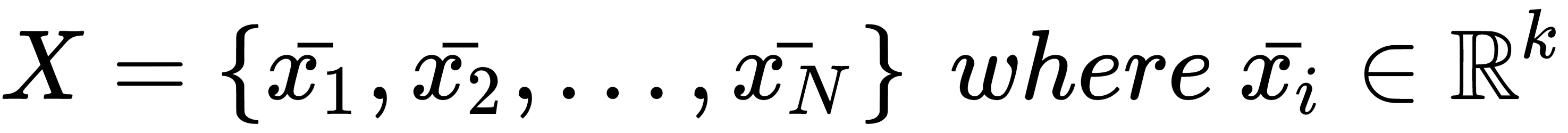
In many statistical learning tasks, our goal is to find the optimal parameter set θ according to a maximization criterion. The most common approach is based on the likelihood and is called MLE. In this case, the optimal set θ is found as follows:
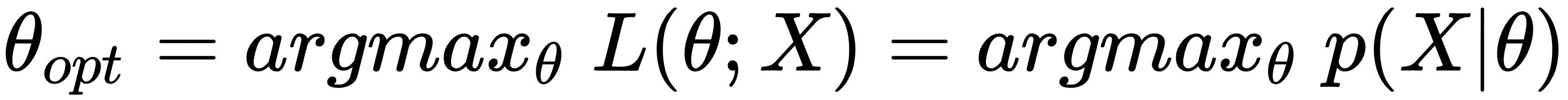
This approach has the advantage of being unbiased by wrong preconditions, but, at the same time, it excludes any possibility of incorporating prior knowledge into the model. It simply looks for the ...

