Let's consider a mini-batch of k samples:
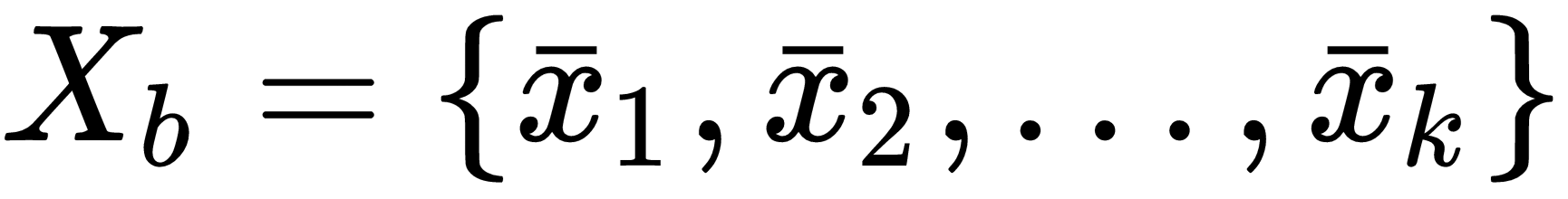
Before traversing the network, we can measure a mean and a variance:
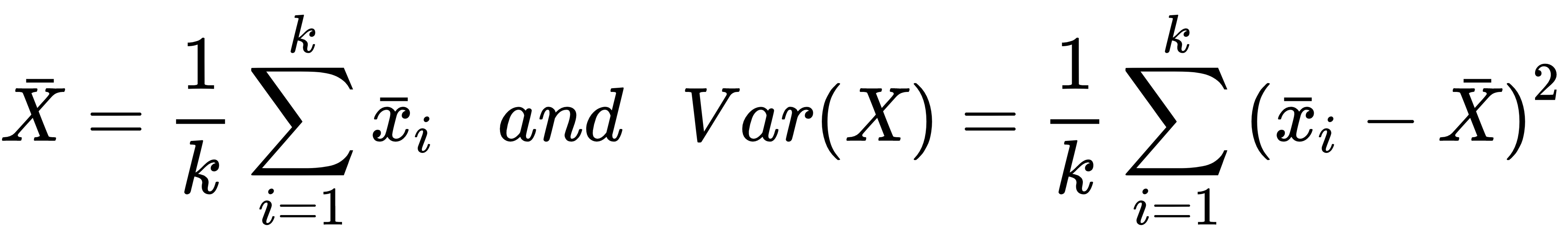
After the first layer (for simplicity, let's suppose that the activation function, f(•), is the always the same), the batch is transformed into the following:
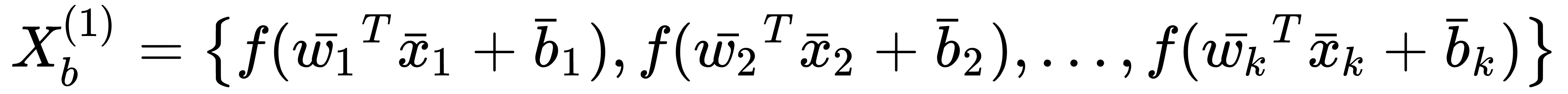
In general, there's no guarantee that the new mean and variance are the same. On the contrary, it's easy to observe a modification that increases throughout ...

