In general, standard autoencoders produce dense internal representations. This means that most of the values are different from zero. In some cases, however, it's more useful to have sparse codes that can better represent the atoms belonging to a dictionary. In this case, if zi = (0, 0, zin, ..., 0, zim, ...), we can consider each sample as the overlap of specific atoms weighted accordingly. To achieve this objective, we can simply apply an L1 penalty to the code layer, as explained in Chapter 1, Machine Learning Models Fundamentals. The loss function for a single sample therefore becomes the following:
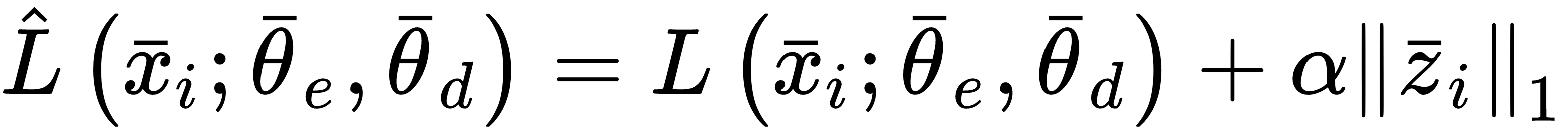
In this case, we ...

