Chapter 1. The Machine Learning Pipeline
Before diving into feature engineering, let’s take a moment to take a look at the overall machine learning pipeline. This will help us get situated in the larger picture of the application. To that end, we’ll begin with a little musing on the basic concepts like data and models.
Data
What we call data are observations of real-world phenomena. For instance, stock market data might involve observations of daily stock prices, announcements of earnings by individual companies, and even opinion articles from pundits. Personal biometric data can include measurements of our minute-by-minute heart rate, blood sugar level, blood pressure, etc. Customer intelligence data includes observations such as “Alice bought two books on Sunday,” “Bob browsed these pages on the website,” and “Charlie clicked on the special offer link from last week.” We can come up with endless examples of data across different domains.
Each piece of data provides a small window into a limited aspect of reality. The collection of all of these observations gives us a picture of the whole. But the picture is messy because it is composed of a thousand little pieces, and there’s always measurement noise and missing pieces.
Tasks
Why do we collect data? There are questions that data can help us answer—questions like “Which stocks I should invest in?” or “How can I live a healthier lifestyle?” or “How can I understand my customers’ changing tastes, so that my business can serve them better?”
The path from data to answers is full of false starts and dead ends (see Figure 1-1). What starts out as a promising approach may not pan out. What was originally just a hunch may end up leading to the best solution. Workflows with data are frequently multistage, iterative processes. For instance, stock prices are observed at the exchange, aggregated by an intermediary like Thomson Reuters, stored in a database, bought by a company, converted into a Hive store on a Hadoop cluster, pulled out of the store by a script, subsampled, massaged, and cleaned by another script, dumped to a file, and converted to a format that you can try out in your favorite modeling library in R, Python, or Scala. The predictions are then dumped back out to a CSV file and parsed by an evaluator, and the model is iterated multiple times, rewritten in C++ or Java by your production team, and run on all of the data before the final predictions are pumped out to another database.

Figure 1-1. The garden of bifurcating paths between data and answers
However, if we disregard the mess of tools and systems for a moment, we might see that the process involves two mathematical entities that are the bread and butter of machine learning: models and features.
Models
Trying to understand the world through data is like trying to piece together reality using a noisy, incomplete jigsaw puzzle with a bunch of extra pieces. This is where mathematical modeling—in particular statistical modeling—comes in. The language of statistics contains concepts for many frequent characteristics of data, such as wrong, redundant, or missing. Wrong data is the result of a mistake in measurement. Redundant data contains multiple aspects that convey exactly the same information. For instance, the day of week may be present as a categorical variable with values of “Monday,” “Tuesday,” ... “Sunday,” and again included as an integer value between 0 and 6. If this day-of-week information is not present for some data points, then you’ve got missing data on your hands.
A mathematical model of data describes the relationships between different aspects of the data. For instance, a model that predicts stock prices might be a formula that maps a company’s earning history, past stock prices, and industry to the predicted stock price. A model that recommends music might measure the similarity between users (based on their listening habits), and recommend the same artists to users who have listened to a lot of the same songs.
Mathematical formulas relate numeric quantities to each other. But raw data is often not numeric. (The action “Alice bought The Lord of the Rings trilogy on Wednesday” is not numeric, and neither is the review that she subsequently writes about the book.) There must be a piece that connects the two together. This is where features come in.
Features
A feature is a numeric representation of raw data. There are many ways to turn raw data into numeric measurements, which is why features can end up looking like a lot of things. Naturally, features must derive from the type of data that is available. Perhaps less obvious is the fact that they are also tied to the model; some models are more appropriate for some types of features, and vice versa. The right features are relevant to the task at hand and should be easy for the model to ingest. Feature engineering is the process of formulating the most appropriate features given the data, the model, and the task.
The number of features is also important. If there are not enough informative features, then the model will be unable to perform the ultimate task. If there are too many features, or if most of them are irrelevant, then the model will be more expensive and tricky to train. Something might go awry in the training process that impacts the model’s performance.
Model Evaluation
Features and models sit between raw data and the desired insights (see Figure 1-2). In a machine learning workflow, we pick not only the model, but also the features. This is a double-jointed lever, and the choice of one affects the other. Good features make the subsequent modeling step easy and the resulting model more capable of completing the desired task. Bad features may require a much more complicated model to achieve the same level of performance. In the rest of this book, we will cover different kinds of features and discuss their pros and cons for different types of data and models. Without further ado, let’s get started!
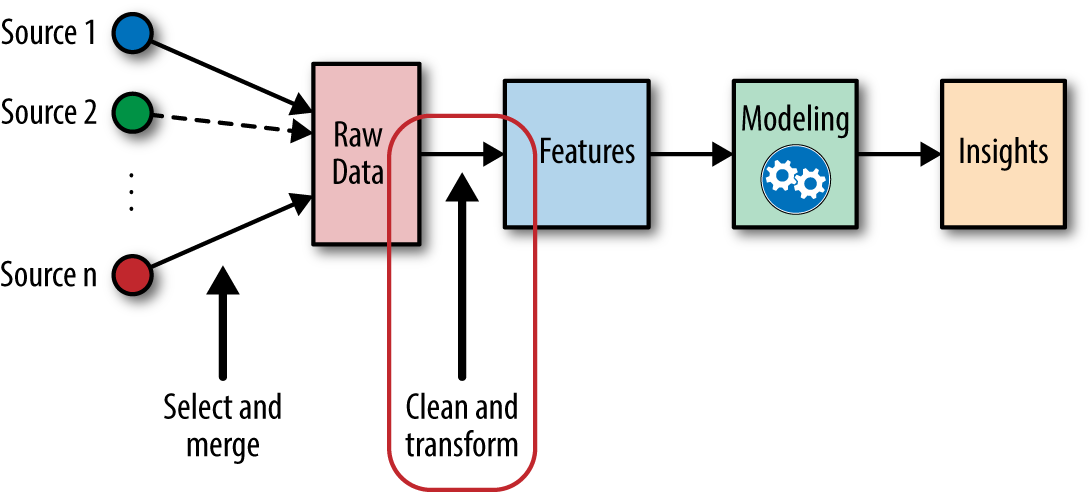
Figure 1-2. The place of feature engineering in the machine learning workflow
Get Feature Engineering for Machine Learning now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

