Before going to the solution, what are the first thoughts which come up when you see the following screenshot for a Cassandra cluster which is running in the cloud and balanced across three Available Zones (AZs) with three replication factor? Is it that a few nodes are being hit hard? More compactions? Smaller nodes than the rest? Repairs? Bulk loading? Bad network layer?
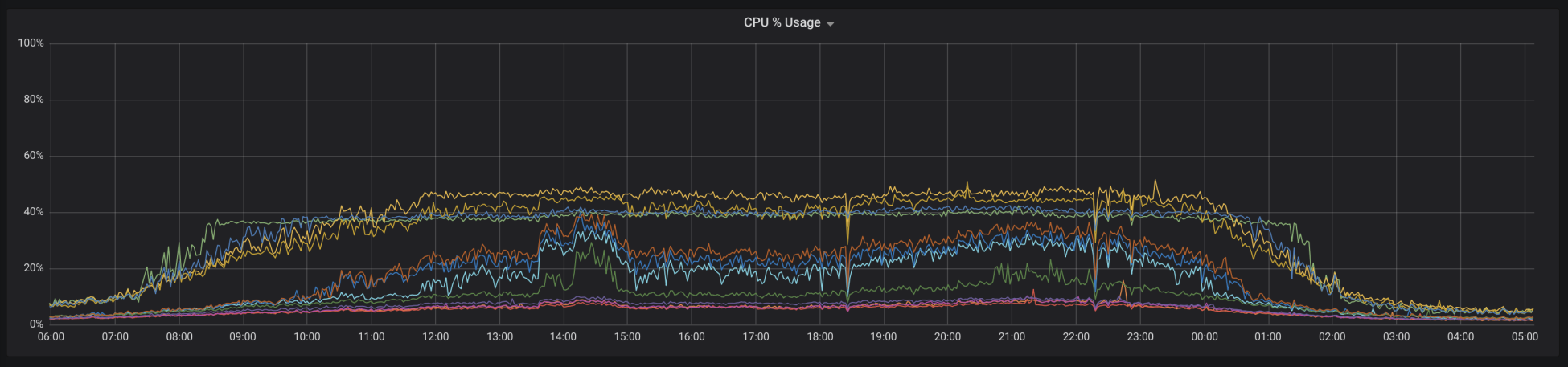
Figure 7.35: High CPU usage on a few nodes
In order to compare apples to apples, let's first make sure all the nodes are the same size, including the CPU architecture, because different CPU architectures in the same cluster might perform differently. There ...

