Chapter 1. Networking Fundamentals
The Network Information Service (NIS) and Network File System (NFS) are services that allow you to build distributed computing systems that are both consistent in their appearance and transparent in the way files and data are shared.
NIS provides a distributed database system for common configuration files. NIS servers manage copies of the database files, and NIS clients request information from the servers instead of using their own, local copies of these files. For example, the /etc/hosts file is managed by NIS. A few NIS servers manage copies of the information in the hosts file, and all NIS clients ask these servers for host address information instead of looking in their own /etc/hosts file. Once NIS is running, it is no longer necessary to manage every /etc/hosts file on every machine in the network — simply updating the NIS servers ensures that all machines will be able to retrieve the new configuraton file information.
NFS is a distributed filesystem. An NFS server has one or more filesystems that are mounted by NFS clients; to the NFS clients, the remote disks look like local disks. NFS filesystems are mounted using the standard Unix mount command, and all Unix utilities work just as well with NFS-mounted files as they do with files on local disks. NFS makes system administration easier because it eliminates the need to maintain multiple copies of files on several machines: all NFS clients share a single copy of the file on the NFS server. NFS also makes life easier for users: instead of logging on to many different systems and moving files from one system to another, a user can stay on one system and access all the files that he or she needs within one consistent file tree.
This book contains detailed descriptions of these services, including configuration information, network design and planning considerations, and debugging, tuning, and analysis tips. If you are going to be installing a new network, expanding or fixing an existing network, or looking for mechanisms to manage data in a distributed environment, you should find this book helpful.
Many people consider NFS to be the heart of a distributed computing environment, because it manages the resource users are most concerned about: their files. However, a distributed filesystem such as NFS will not function properly if hosts cannot agree on configuration information such as usernames and host addresses. The primary function of NIS is managing configuration information and making it consistent on all machines in the network. NIS provides the framework in which to use NFS. Once the framework is in place, you add users and their files into it, knowing that essential configuration information is available to every host. Therefore, we will look at directory services and NIS first (in Chapter 2 through Chapter 4); we’ll follow that with a discussion of NFS in Chapter 5 through Chapter 13.
Networking overview
Before discussing either NFS, or NIS, we’ll provide a brief overview of network services.
NFS and NIS are high-level networking protocols, built on several lower-level protocols. In order to understand the way the high-level protocols function, you need to know how the underlying services work. The lower-level network protocols are quite complex, and several books have been written about them without even touching on NFS and NIS services. Therefore, this chapter contains only a brief outline of the network services used by NFS and NIS.
Network protocols are typically described in terms of a layered model, in which the protocols are “stacked” on top of each other. Data coming into a machine is passed from the lowest-level protocol up to the highest, and data sent to other hosts moves down the protocol stack. The layered model is a useful description because it allows network services to be defined in terms of their functions, rather than their specific implementations. New protocols can be substituted at lower levels without affecting the higher-level protocols, as long as these new protocols behave in the same manner as those that were replaced.
The standard model for networking protocols and distributed applications is the International Organization for Standardization (ISO) seven-layer model shown in Table 1-1.
|
Layer |
Name |
Physical Layer |
|
7 |
Application |
NFS and NIS |
|
6 |
Presentation |
XDR |
|
5 |
Session |
RPC |
|
4 |
Transport |
TCP or UDP |
|
3 |
Network |
IP |
|
2 |
Data Link |
Ethernet |
|
1 |
Physical |
CAT-5 |
Purists will note that the TCP/IP protocols do not precisely fit the specifications for the services in the ISO model. The functions performed by each layer, however, correspond very closely to the functions of each part of the TCP/IP protocol suite, and provide a good framework for visualizing how the various protocols fit together.
The lower levels have a well-defined job to do, and the higher levels rely on them to perform it independently of the particular medium or implementation. While TCP/IP most frequently is run over Ethernet, it can also be used with a synchronous serial line or fiber optic network. Different implementations of the first two network layers are used, but the higher-level protocols are unchanged. Consider an NFS server that uses all six lower protocol layers: it has no knowledge of the physical cabling connecting it to its clients. The server just worries about its NFS protocols and counts on the lower layers to do their job as well.
Throughout this book, the network stack or protocol stack refers to this layering of services. Layer or level will refer to one specific part of the stack and its relationship to its upper and lower neighbors. Understanding the basic structure of the network services on which NFS and NIS are built is essential for designing and configuring large networks, as well as debugging problems. A failure or overly tight constraint in a lower-level protocol affects the operation of all protocols above it. If the physical network cannot handle the load placed on it by all of the desktop workstations and servers, then NFS and NIS will not function properly. Even though NFS or NIS will appear “broken,” the real issue is with a lower level in the network stack.
The following sections briefly describe the function of each layer and the mapping of NFS and NIS into them. Many books have been written about the ISO seven-layer model, TCP/IP, and Ethernet, so their treatment here is intentionally light. If you find this discussion of networking fundamentals too basic, feel free to skip over this chapter.
Physical and data link layers
The physical and data link layers of the network protocol stack together define a machine’s network interface. From a software perspective, the network interface defines how the Ethernet device driver gets packets from or to the network. The physical layer describes the way data is actually transmitted on the network medium. The data link layer defines how these streams of bits are put together into manageable chunks of data.
Ethernet is the best known implementation of the physical and data link layers. The Ethernet specification describes how bits are encoded on the cable and also how stations on the network detect the beginning and end of a transmission. We’ll stick to Ethernet topics throughout this discussion, since it is the most popular network medium in networks using NFS and NIS.
Ethernet can be run over a variety of media, including thinnet, thicknet, unshielded twisted-pair (UTP) cables, and fiber optics. All Ethernet media are functionally equivalent — they differ only in terms of their convenience, cost of installation, and maintenance. Converters from one media to another operate at the physical layer, making a clean electrical connection between two different kinds of cable. Unless you have access to high-speed test equipment, the physical and data link layers are not that interesting when they are functioning normally. However, failures in them can have strange, intermittent effects on NFS and NIS operation. Some examples of these spectacular failures are given in Chapter 15.
Frames and network interfaces
The data link layer defines the format of data on the network. A series of bits, with a definite beginning and end, constitutes a network frame, commonly called a packet. A proper data link layer packet has checksum and network-specific addressing information in it so that each host on the network can recognize it as a valid (or invalid) frame and determine if the packet is addressed to it. The largest packet that can be sent through the data link layer defines the Maximum Transmission Unit, or MTU, of the network.
All hosts have at least one network interface, although any host connected to an Ethernet has at least two: the Ethernet interface and the loopback interface. The Ethernet interface handles the physical and logical connection to the outside world, while the loopback interface allows a host to send packets to itself. If a packet’s destination is the local host, the data link layer chooses to “send” it via the loopback, rather than Ethernet, interface. The loopback device simply turns the packet around and queues it at the bottom of the protocol stack as if it were just received from the Ethernet.
You may find it helpful to think of the protocol layers as passing packets upstream and downstream in envelopes, where the packet envelope contains some protocol-specific header information but hides the remainder of the packet contents. As data messages are passed from the top most protocol layer down to the physical layer, the messages are put into envelopes of increasing size. Each layer takes the entire message and envelope from the layer above and adds its own information, creating a new message that is slightly larger than the original. When a packet is received, the data link layer strips off its envelope and passes the result up to the network layer, which similarly removes its header information from the packet and passes it up the stack again.
Ethernet addresses
Associated with the data link layer is a method for addressing hosts on the network. Every machine on an Ethernet has a unique, 48-bit address called its Ethernet or Media Access Control (MAC) address. Vendors making network-ready equipment ensure that every machine in the world has a unique MAC address. 24-bit prefixes for MAC addresses are assigned to hardware vendors, and each vendor is responsible for the uniqueness of the lower 24 bits. MAC addresses are usually represented as colon-separated pairs of hex digits:
8:0:20:ae:6:1f
Note that MAC addresses identify a host, and a host with multiple network interfaces may use the same MAC address on each.
Part of the data link layer’s protocol-specific header are the packet’s source and destination MAC addresses. Each protocol layer supports the notion of a broadcast, which is a packet or set of packets that must be sent to all hosts on the network. The broadcast MAC address is:
ff:ff:ff:ff:ff:ff
All network interfaces recognize this wildcard MAC address as a broadcast address, and pass the packet up to a higher-level protocol handler.
Network layer
At the data link layer, things are fairly simple. Machines agree on the format of packets and a standard 48-bit host addressing scheme. However, the packet format and encoding vary with different physical layers: Ethernet has one set of characteristics, while an X.25-based satellite network has another. Because there are many physical networks, there should ideally be a standard interface scheme so that it isn’t necessary to re-implement protocols on top of each physical network and its peculiar interfaces. This is where the network layer fits in. The higher-level protocols, such as TCP (at the transport layer), don’t need to know any details about the physical network that is in use. As mentioned before, TCP runs over Ethernet, fiber optic network, or other media; the TCP protocols don’t care about the physical connection because it is represented by a well-defined network layer interface.
The network layer protocol of primary interest to NFS and NIS is the Internet Protocol, or IP. As its name implies, IP is responsible for getting packets between hosts on one or more networks. Its job is to make a best effort to get the data from point A to point B. IP makes no guarantees about getting all of the data to the destination, or the order in which the data arrives — these details are left for higher-level protocols to worry about.
On a local area network, IP has a fairly simple job, since it just moves packets from a higher-level protocol down to the data link layer. In a set of connected networks, however, IP is responsible for determining how to get data from its source to the correct destination network. The process of directing datagrams to another network is called routing; it is one of the primary functions of the IP protocol. Appendix A contains a detailed description of how IP performs routing.
Datagrams and packets
IP deals with data in chunks called datagrams. The terms packet and datagram are often used interchangeably, although a packet is a data link-layer object and a datagram is network layer object. In many cases, particularly when using IP on Ethernet, a datagram and packet refer to the same chunk of data. There’s no guarantee that the physical link layer can handle a packet of the network layer’s size. As previously mentioned, the largest packet that can be handled by the physical link layer is called the Maximum Transmission Unit, or MTU, of the network media. If the medium’s MTU is smaller than the network’s packet size, then the network layer has to break large datagrams down into packet-sized chunks that the data link and physical layers can digest. This process is called fragmentation. The host receiving a fragmented datagram reassembles the pieces in the correct order. For example, an X.25 network may have an MTU as small as 128 bytes, so a 1518-byte IP datagram would have to be fragmented into many smaller network packets to be sent over the X.25 link. For the scope of this book, we’ll use packet to describe both the IP and the data link-layer objects, since NFS is most commonly run on Ethernet rather than over wide-area networks with smaller MTUs. However, the distinction will be made when necessary, such as when discussing NFS traffic over a wide area point-to-point link.
IP host addresses
The internet protocol identifies hosts with a number called an IP address or a host address. To avoid confusion with MAC addresses (which are machine or station addresses), the term IP address will be used to designate this kind of address. IP addresses come in two flavors: 32-bit IP Version 4 (IPv4) or 128 bit IPv6 address. We will talk about IPv6 addresses later in this chapter. For now, we will focus on IPv4 addresses. IPv4 addresses are written as four dot-separated decimal numbers between 0-255 (a dotted quad):
192.9.200.1
IP addresses must be unique among all connected machines. Connected machines in this case are any hosts that you can get to over a network or connected set of networks, including your local area network, remote offices joined by the company’s wide-area network, or even the entire Internet community. For a standalone system or a small office that is not connected (via an IP network) to the outside world, you can use the standard, private network addresses assigned such purposes. See Section 1.3.3 later in this chapter. If your network is connected to the Internet, you have to get a range of IP addresses assigned to your machines through a central network administration authority, via your Internet Service Provider. If you are planning on joining the Internet in the future, you will need to obtain an address from your network service provider. This may be either an actual provider of Internet service, or your own organization, if it has addresses to hand out. We won’t go into this further in this book.
The IP address uniqueness requirement differs from that for MAC addresses. IP addresses are unique only on connected networks, but machine MAC addresses are unique in the world, independent of any connectivity. Part of the reason for the difference in the uniqueness requirement is that IPv4 addresses are 32 bits, while MAC addresses are 48 bits, so mapping every possible MAC address into an IPv4 address requires some overlap. There are a variety of reasons why the IPv4 address is only 32 bits, while the MAC address is 48 bits, most of which are historical.
Since the network and data link layers use different addressing schemes, some system is needed to convert or map the IP addresses to MAC addresses. Transport-layer services and user processes use IP addresses to identify hosts, but packets that go out on the network need MAC addresses. The Address Resolution Protocol (ARP) is used to convert the 32-bit IPv4 address of a host into its 48-bit MAC address. When a host wants to map an IP address to a MAC address, it broadcasts an ARP request on the network, asking for the host using the IP address to respond. The host that sees its own IP address in the request returns its MAC address to the sender. With a MAC address, the sending host can transmit a packet on the Ethernet and know that the receiving host will recognize it.
A host can have more than one IP address. Usually this is because the host is connected to multiple physical network segments (requiring one network interface, such as an Ethernet controller, per segment), or because the host has multiple interfaces to the same physical network segment.
IPv4 address classes
Each IPv4 address has a network number and a host number. The host number identifies a particular machine on an organization’s network. IP addresses are divided into classes that determine which parts of the address make up the network and host numbers, as demonstrated in Table 1-2.
|
Address Class and First Octet Value |
Network Number Octets |
Host Number Octets |
Address Form |
Number of Networks |
Number of Hosts per Network |
Maximum Number of Hosts per Class |
|
Class A: 1-126 |
1 |
3 |
N.H.H.H |
126 |
2563 - 2 |
2,113,928,964 |
|
Class B: 128-191 |
2 |
2 |
N.N.H.H |
16,384 |
2562 - 2 |
1,073,709,056 |
|
Class C: 192-223 |
3 |
1 |
N.N.N.H |
2,097,152 |
254 |
532,676,608 |
|
Class D: 224-239 |
N/A |
N/A |
M.M.M.M |
N/A |
N/A |
N/A |
|
Class E: 240-255 |
N/A |
N/A |
R.R.R.R |
N/A |
N/A |
N/A |
Each N represents part of the network number and each H is part of the address’s host number. The 8-bit octet has 256 possible values, but 0 and 255 in the last host octet are reserved for forming broadcast addresses.
Network numbers with first octet values of 240-254 are reserved for future use. The network numbers 0, 127, 255, 10, 172.16-172.31, and 192.168.0-192.168.255 are also reserved:
0 is used as a place holder in forming a network number, and in some cases, for IP broadcast addresses.
10, 172.16-172.31, and 192.168.0-192.168.255 are used for private networks that will never be connected to the global Internet.
Note that there are only 126 class A network numbers, but well over two million class C network numbers. When the Internet was founded, it was almost impossible to get a class A network number, and few organizations (aside from entire networks or countries) had enough hosts to justify a class A address. Most companies and universities requested class B or class C addresses. A medium-sized company, with several hundred machines, could request several class C network numbers, putting up to 254 hosts on each network. Now that the Internet is much bigger, the rules for class A, B, and C network number assignment have changed, as explained in Section 1.3.4.
Class D addresses look similar to the other classes in that each address consists of 4 octets with a value no higher than 255 per octet. Unlike classes A, B, and C, a class D address does not have a network number and host number. Class D addresses are multicast addresses, which are used to send messages to more than one recipient host, whereas IP addresses in classes A, B, and C are unicast addresses destined for one recipient. Multicast on the Internet offers plenty of potential for efficient broadcast of information, such as bulk file transfers, audio and video, and stock pricing information, but has achieved limited deployment. There is an ongoing experiment known as the “MBONE” (Multicast backBONE) on the Internet to exploit this technology.
Class E addresses are reserved for future assignment.
Classless IP addressing
In the early 1990s, due to the advent of the World Wide Web, the Internet’s growth exploded. In theory, if you sum the maximum number of hosts per classes A, B, and C (refer back to Table 1-2), the Internet can have a potential for over 3.7 billion hosts. In reality, the Internet was running out of address capacity for two reasons.
The first had to do with the inefficiencies built into the class partitioning. About 3.2 billion of the theoretical number of hosts were class A and class B, leaving about 500 million class C addresses. Most organizations did not need class A or class B addresses, and of those that did, a significant fraction of their assigned address space was not needed. Most users could get by with a class C network number, but the typical small business or home user did not need 254 hosts. Thus, the number of class C addresses was bounded by the maximum number of class C networks, about two million, which is far less than the number of users on the Internet.
The problem of only two million class C networks was mitigated by the introduction of dynamically assigned IP addresses, and by the introduction of policies that tended to assign IP network numbers only to Internet Service Providers (ISPs), or to organizations that effectively acted as their own ISP, which would then use the free market to efficiently reallocate the IP addresses dynamically or statically to their customers. Thus most Intenet users get assigned a single IP address, and the ISP is assigned the corresponding network number.
The second reason was routing scalability. When the Internet was orders of magnitude smaller then it is today, most address assignments were for class A or B and so routing between networks was straightforward. The routers simply looked at the network number, and sent it to a router responsible for that route. With the explosion of the Internet, and with most of that growth in class C network numbers, each network’s router might have to maintain tables of hundreds of thousands of routes. As the Internet grew rapidly, keeping these tables up to date was difficult.
This situation was not sustainable, and so the concept of “classless addressing” was introduced. With the exception of grandfathered address assignments, each IP address, regardless of whether it’s class A, B, or C, would not have an implicit network number part and host number part. Instead the network part would be designated explicitly via a suffix of the form: “/XX”, where XX is the number of bits of the IP address that refer to the network. Those organizations that needed more than the 254 hosts that a class C address would provide, would instead be assigned consecutive class C addresses. For example, an ISP that was assigned 192.1.2 and 192.1.3 could have a classless network number of 192.1.3.0/23. Any router on a network other than 192.1.2 or 192.1.3 that wanted to send to either network number would instead route to a single router associated with the classless network number 192.1.3.0/23 (i.e., any IP address that had its first 23 bits equal to 1100 0000 0000 0001 0000 001).
With this new scheme, larger organizations get more consecutive class C network numbers. Within their local networks (“Intranets”), they can either use traditional class-based routing or classless routing that further subdivides the local network address space that can be used. The largest organizations may find that class-based routing doesn’t scale, and so classless routing is the best approach.
Virtual interfaces
In Section 1.3.2, we noted that a host could have multiple IP addresses assigned to it if it had multiple physical network interfaces. It is possible for a physical network segment to support more than one IP network number. For example, a segment might have 128.0.0.0/16 and 192.4.5.6/24. Some hosts on that segment might want to directly address hosts with either network number. Some operating systems, such as Solaris, will let you define multiple virtual or logical interfaces for a physical network interface. On most Unix systems, the ifconfig command is used to set up interfaces. See your vendor’s ifconfig manual page for more details.
IP Version 6
Until now we have been discussing IPv4 addresses that are four octets long. The discussion in Section 1.3.4 showed a clever way to extend the life of the 32 bit IPv4 address space. However, it was recognized long ago, even before the introduction of the World Wide Web, that the IPv4 address space was under pressure. IP Version 6 (IPv6) has been defined to solve the address space limitations by increasing the address length to 128 bit addresses. At the time of this writing, while most installed systems either do not support it or do not use it, most marketed systems support IPv6. Since it seems inevitable that you’ll encounter some IPv6 networks in the next few years, we will explain some of the basics of IPv6. Note that IPv6 is sometimes referred to as IPng: IP Next Generation.
Instead of dotted quads, IPv6 addresses are usually expressed as:
x:x:x:x:x:x:x:x
where each x is a 16 bit hexadecimal value. In environments where a network is transitioning from IP Version 4 to Version 6, you might want to use a form like:
x:x:x:x:x:x:d.d.d.d
where d.d.d.d represents an IP Version 4 dotted quad.
When there are one or more consecutive sequences of x’s such that each x is all zeroes, the sequence can be replaced with “::”, but there can be only one such “::” abbreviation in an IPv6 address. Thus:
1234:0000:5678:9ABC:DEF0:1234:5678:9ABC 3:0:0:0:0:0:3333:4444
can be abbreviated as:
1234::5678:9ABC:DEF0:1234:5678:9ABC 3::3333:4444
As you might expect, IPv6 dispenses with address classes for unicast addresses. You specify classless network numbers (address prefixes), using the same classless addressing notation that IP Version 4 uses.
IP Version 6 address pools
While the designation of the network number in IPv6 is classless, the 128-bit address is still carved up into various pools. Portions of the address space are allocated for:
Reserved or unassigned for future purposes
Open Systems Interconnection (OSI) network protocols
Novell IPX protocols
Unicast addresses, including:
global unicast addresses that can be used to send packets to hosts outside the local site
site local unicast addresses than can be used to send packets only to hosts within a site
link local unicast addresses that can used to send packets only to hosts within a physical network segment
Addresses of nodes that support IPv6, but want to use existing IP Version 4 infrastructure to encapsulate IPv6 packets within IPv4 packets for transport between networks. The last 32 bits of these addresses correspond to IPv4 addresses. These addresses are denoted as:
::d.d.d.d
While this scheme does not let you benefit from IPv6’s extended addressing, it does let you take advantage of IPv6’s other features (such as a richer set of protocol options) while transitioning from IPv4.
IP Version 6 loopback address
Instead of dedicating about 16 million addresses for loopback interfaces as IPv4 does, IPv6 uses just one address for that purpose:
::1
IP Version 6 unspecified address
IPv6 introduces the concept of an “unspecified” address, which is all zeroes:
::0
This address can be used by hosts that don’t know their own address, but need to generate queries to determine their address assignment. Such hosts would use “::0” as the source address in an IPv6 packet.
Transport layer
The transport layer has two major jobs: it must subdivide user-sized data buffers into network layer-sized datagrams, and it must enforce any desired transmission control such as reliable delivery. Two transport protocols that sit on top of IP are the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP), which offer different delivery guarantees.
TCP and UDP
TCP is best known as the first half of TCP/IP; as discussed in this and the preceding sections, the acronyms refer to two distinct services. TCP provides reliable, sequenced delivery of packets. It is ideally suited for connection-oriented communication, such as a remote login or a file transfer. Missing packets during a login session is both frustrating and dangerous — what happens if rm *.o gets truncated to rm * ? TCP-based services are generally geared toward long-lived network connections, and TCP is used in any case when ordered datagram delivery is a requirement. There is overhead in TCP for keeping track of packet delivery order and the parts of the data stream that must be resent. This is state information. It’s not part of the data stream, but rather describes the state of the connection and the data transfer. Maintaining this information for each connection makes TCP an inherently stateful protocol. Because there is state, TCP can adapt its data flow rate when the network is congested.
UDP is a no-frills transport protocol: it sends large datagrams to a remote host, but it makes no assurances about their delivery or the order in which they are delivered. UDP is best for connectionless communication on local area networks in which no context is needed to send packets to a remote host and there is no concern about congestion. Broadcast-oriented services use UDP, as do those in which repeated, out of sequence, or missed requests have no harmful side effects.
Reliable and unreliable delivery is the primary distinction between TCP and UDP. TCP will always try to replace a packet that gets lost on the network, but UDP does not. UDP packets can arrive in any order. If there is a network bottleneck that drops packets, UDP packets may not arrive at all. It’s up to the application built on UDP to determine that a packet was lost, and to resend it if necessary. The state maintained by TCP has a fixed cost associated with it, making UDP a faster protocol on low-latency, high-bandwidth links. The price paid for speed (in UDP) is unreliability and added complexity to the higher level applications that must handle lost packets.
Port numbers
A host may have many TCP and UDP connections at any time. Connections to a host are distinguished by a port number, which serves as a sort of mailbox number for incoming datagrams. There may be many processes using TCP and UDP on a single machine, and the port numbers distinguish these processes for incoming packets. When a user program opens a TCP or UDP socket, it gets connected to a port on the local host. The application may specify the port, usually when trying to reach some service with a well-defined port number, or it may allow the operating system to fill in the port number with the next available free port number.
When a packet is received and passed to the TCP or UDP handler, it gets directed to the interested user process on the basis of the destination port number in the packet. The quadruple of:
source IP address, source port, destination IP address, destination port
uniquely identifies every interhost connection in the network. While many processes may be talking to the process that handles remote login requests (therefore their packets have the same destination IP addresses and port numbers), they will have unique pairs of source IP addresses and port numbers. The destination port number determines which of the many processes using TCP or UDP gets the data.
On most Unix systems port numbers below 1024 are reserved for the processes executing with superuser privileges, while ports 1024 and above may be used by any user. This enforces some measure of security by preventing random user applications from accessing ports used by servers. However, given that most nodes on the network don’t run Unix, this measure of security is very questionable.
The session and presentation layers
The session and presentation layers define the creation and lifetime of network connections and the format of data sent over these connections. Sessions may be built on top of any supported transport protocol — login sessions use TCP, while services that broadcast information about the local host use UDP. The session protocol used by NFS and NIS is the Remote Procedure Call (RPC).
The client-server model
RPC provides a mechanism for one host to make a procedure call that appears to be part of the local process but is really executed on another machine on the network. Typically, the host on which the procedure call is executed has resources that are not available on the calling host. This distribution of computing services imposes a client/server relationship on the two hosts: the host owning the resource is a server for that resource, and the calling host becomes a client of the server when it needs access to the resource. The resource might be a centralized configuration file (NIS) or a shared filesystem (NFS).
Instead of executing the procedure on the local host, the RPC system bundles up the arguments passed to the procedure into a network datagram. The exact bundling method is determined by the presentation layer, described in the next section. The RPC client creates a session by locating the appropriate server and sending the datagram to a process on the server that can execute the RPC; see Figure 1-1. On the server, the arguments are unpacked, the server executes the result, packages the result (if any), and sends it back to the client. Back on the client side, the reply is converted into a return value for the procedure call, and the user application is re-entered as if a local procedure call had completed. This is the end of the “session,” as defined in the ISO model.
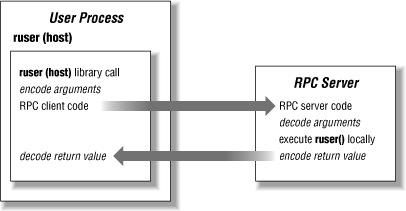
RPC services may be built on either TCP or UDP transports, although most are UDP-oriented because they are centered around short-lived requests. Using UDP also forces the RPC call to contain enough context information for its execution independent of any other RPC requests, since UDP packets may arrive in any order, if at all.
When an RPC call is made, the client may specify a timeout period in which the call must complete. If the server is overloaded or has crashed, or if the request is lost in transit to the server, the remote call may not be executed before the timeout period expires. The action taken upon an RPC timeout varies by application; some resend the RPC call, while others may look for another server. Detailed mechanics of making an RPC call can be found in Chapter 13.
External data representation
At first look, the data presentation layer seems like overkill. Data is data, and if the client and server processes were written to the same specification, they should agree on the format of the data — so why bother with a presentation protocol? While a presentation layer may not be needed in a purely homogeneous network, it is required in a heterogeneous network to unify differences in data representation. These differences are outlined in the following list:
Again, a presentation protocol would not be necessary if datagrams consisted only of byte-oriented data. However, applications that use RPC expect a system call-like interface, including support for structures and data types more complex than byte streams. The presentation layer provides services for encoding and decoding argument buffers that may then be passed down to RPC for transmission to the client or server.
The External Data Representation (XDR) protocol was developed by Sun Microsystems and is used by NIS and NFS at the presentation layer. XDR is built on the notion of an immutable network byte ordering, called the canonical form. It isn’t really important what the canonical form is — your system may or may not use the same byte ordering and structure packing conventions. The canonical form simply allows network hosts to exchange structured data (as opposed to streams of bytes) independently of any peculiarities of a particular machine. All data structures are converted into the network byte ordering and padded appropriately.
The rule of XDR is “sender makes local canonical; receiver makes canonical local.” Any data that goes over the network is in canonical form.[1] A host sending data on the network converts it to canonical form, and the host that receives the data converts it back into its local representation. A different way to implement the presentation layer might be “receiver makes local.” In this case, the sender does nothing to the local data, and the receiver must deduce the packing and encoding technique and convert it into the local equivalent. While this scheme may send less data over the network — since it is not subject to additional padding — it places the burden of incorporating a new hardware architecture on the receiving side, rather than on the new machine. This doesn’t seem like a major distinction, but consider having to change all existing, fielded software to handle the new machine’s structure-packing conventions. It’s usually worth the overhead of converting to and from canonical form to ensure that all new machines will be able to “plug in” to the network without any software changes.
The XDR and RPC layers complete the foundation necessary for a client/server distributed computing relationship. NFS and NIS are client/server applications, which means they sit at the top layer of the protocol stack and use the XDR and RPC services. To complete this introduction to network services, we’ll take a look at the two mechanisms used to start and maintain servers for various network services.
Internet and RPC server configuration
The XDR and RPC services are useful for applications that need to exchange data structures over the network. Each new RPC request contains all required information in its XDR-encoded arguments, just as a local procedure call gets its inputs from passed-in arguments. RPC services are usually connectionless services because RPC requests do not require the creation of a long-lived network connection between the client and server. The client communicates with the server to send its request and receive a reply, but there is no connection or environment for the communication.
There are many other network services, such as telnet and ftp, that are commonly referred to as the Internet or ARPA services. They are part of the original suite of utilities designed for use on the Internet. Internet services are generally based on the TCP protocol and are connection-oriented — the service client establishes a connection to a server, and data is then exchanged in the form of a well-ordered byte stream. There is no need for RPC or XDR services, since the data is byte-oriented, and the service defines its own protocols for handling the data stream. The telnet service, for example, has its own protocol for querying the server about end-of-line, terminal type, and flow control conventions.
Note that RPC services are not required to be connectionless. RPC can be run over TCP, in a connection-oriented fashion. The TCP transport protocol may be used with RPC services whenever a large amount of data needs to be transferred. NIS, for example, uses UDP (in connectionless mode) for most of its operations, but switches to TCP whenever it needs to transfer an entire database from one machine to another. NFS supports either TCP or UDP for all its operations.
Most Internet services are managed by a super-daemon called inetd that accepts requests for connections to servers and starts instances of those servers on an as-needed basis. Rather than having many server processes, or daemons, running on each host, inetd starts them as requests arrive. Clients contact the inetd daemon on well-known port numbers for each service. These port numbers are published in the /etc/services file.
inetd sets up a one-to-one relationship between service clients and server-side daemons. Every rlogin shell, for example, has a client side rlogin process (that calls inetd upon invocation) and a server-side in.rlogind daemon that was started by inetd. In this regard, inetd and the services it supports are multi-threaded: they can service multiple clients at the same time, creating a new separate connection (and state information) for each client. A new server instance, or thread, is initiated by each request for that service, but a single daemon handles all incoming requests at once.
Only traffic specific to a single session moves over the connection between a client and its server. When the client is done with the service, it asks the server to terminate its connection, and the server daemon cleans up and exits. If the server prematurely ends the connection due to a crash, for example, the client drops its end of the connection as well.
Some RPC services can’t afford the overhead of using inetd. The standard inetdbased services, like telnet, tend to be used for a long time, so the cost of talking to inetd and having it start a new server process is spread out over the lifetime of the connection. Many RPC calls are short in duration, lasting at most the time required to perform a disk operation.
RPC servers are generally started during the boot process and run as long as the machine is up. While the time required to start a new server process may be small compared to the time a remote login or rsh session exists, this overhead is simply too large for efficient RPC operation. As a result, RPC servers typically have one server process for the RPC service, and it executes remote requests for all clients in the same process. Some RPC servers are single-threaded: they execute requests one at a time. To achieve better performance, some RPC servers are multi-threaded: they have multiple threads of execution within the same process, sharing the same address space. There may be many clients of the RPC server, but their requests intermingle in the RPC server queue and are processed in the order in which server threads are dispatched to deal with the requests.
Instead of using pre-assigned ports and a super-server, RPC servers are designated by service number. The file /etc/rpc contains a list of RPC servers and their program numbers. Each program may contain many procedures. The NFS program, for example, contains more than a dozen procedures, one for each filesystem operation such as “read block,” “write block,” “create file,” “make symbolic link,” and so on. RPC services still must use TCP/UDP port numbers to fit the underlying protocols, so the mapping of RPC program numbers to port numbers is handled by the portmapper daemon (portmap on some systems, rpcbind on others).
When an RPC server initializes, it usually registers its service with the portmapper. The RPC server tells the portmapper which ports it will listen on for incoming requests, rather than having the portmapper listen for it, in inetd fashion. An RPC client contacts the portmapper daemon on the server to determine the port number used by the RPC server, or it may ask the portmapper to call the server indirectly on its behalf. In either case, the first RPC call from a client to a server must be made with the portmapper running. If the portmapper dies, clients will be unable to locate RPC daemons services on the server. A server without a running portmapper effectively stops serving NIS, NFS, and other RPC-based applications.
We’ll come back to RPC mechanics and debugging techniques in later chapters. For now, this introduction to the configuration and use of RPC services suffices as a foundation for explaining the NFS and NIS applications built on top of them.
Socket RPC and Transport Independent RPC
RPC was originally designed to work over sockets, a programing interface for network communication introduced in the 1980s by the University of California in its 4.1c BSD version of Unix. Solaris 2.0 introduced Transport Independent RPC (TI-RPC). The motivation for TI-RPC was that it appeared that OSI networking would eventually supplant TCP/IP-based networking, and so a transport independent interface would make it easier to transition RPC applications was needed. While OSI networking did not take over, TI-RPC is still used in Solaris. TI-RPC introduces an additional configuration file, /etc/netconfig, which defines each transport that RPC services can listen for requests over. In addition to TCP and UDP, the /etc/netconfig file lists connectionless and connection-oriented loopback transports for RPC services that don’t need to provide service outside the host. In Solaris 8, the /etc/netconfig file will also let you specify services over TCP and UDP on IPv6 network interfaces.
[1] The canonical form matches the byte ordering of the Motorola and SPARC family of microprocessors, so these processors do not have to perform any byte swapping to translate to or from canonical form. This byte ordering is called Big Endian. Big Endian ordering is used for many Internet protocols.
Get Managing NFS and NIS, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

