Chapter 7. International Considerations
Although the standard TeX macro packages and the Computer Modern fonts were designed to typeset documents written primarily in English, TeX enjoys widespread international use.
From a technical standpoint, languages can be divided into two categories: those that are “like English” (meaning that they use a relatively small number of characters and are typeset horizontally, left to right) and those that are not. German, French, and Russian are all “like English” in this sense. Hebrew, Chinese, and Japanese are not (Hebrew is typeset right to left, and Chinese and Japanese use thousands of characters).[85]
This chapter explores some of the issues that arise when TeX is used to typeset languages other than English. For simplicity, we'll look at languages like English first, and then describe some environments for typesetting much more complex languages.
Typesetting in Any Language
In order to typeset any language with TeX, three things have to happen:
- TeX has to read the input file and perform the correct mapping from the input file's character set to its internal representation of each character. The character set used in the input file will vary depending upon the language. For instance, if you're writing a document in French, it is as natural to use “é” in your input file as it is to use any other letter.
- TeX has to typeset the document according to the rules of the language being used. Naturally, this means that there must be some way of declaring what language is being used, and appropriate macros have to exist to embody the rules of that language. Users familiar only with English may not recognize the importance of language-specific rules because English has so few rules. Other languages have many. In German, for example, if the consonants “ck” in a word are broken by a hyphen, the “c” becomes a “k” (“k-k”). In French, small amounts of extra space are placed around various punctuation marks.
A good reference manual for internationalization is {Software Internationalization and Localization: An Introduction} [eu:international].
- The DVI file that results from typesetting the document must be printed correctly. In other words, all of the accented characters and symbols used by the language must be available (or constructed) for previewing and printing.
Early attempts to write documents in languages other than English were hampered by several limitations in the TeX program. In particular, fonts were limited to 128 characters, and only a single set of hyphenation patterns could be loaded (effectively preventing multilingual documents from being hyphenated correctly). These technical problems were corrected in TeX version 3.x (first released in 1990). The remaining difficulties---mostly a lack of standardization and the need to develop relevant language-specific macros---are being addressed by the TUG Technical Working Group on Multiple Language Coordination (TWGMLC).
Reading Input Files
The first point to consider when typesetting is that every input file is written in some character set. For example, because this book is written in English and I work in the United States, the source code for this book is written in 7-bit ASCII. If this book were written in another language, a different character set, perhaps ISO Latin1, would be more appropriate.
When TeX reads your input file, characters like “é” and “\guillemet” have to be translated into a form that TeX can use. For example, “é” should be translated into é and, if the DC fonts are in use, “\guillemet” should be translated into character 19; otherwise, if the DC fonts are not in use, “\guillemet” should be translated into $<<$ which will give the approximate result. The DC fonts are discussed in the section called “the section called “Typesetting in Any Language”,” later in this chapter.
It is always possible to access characters from another symbol set by using a control sequence. Table 7.1 shows the standard TeX control sequences for accessing accented characters and characters from other alphabets.[86]
Table 7.1. Standard Control Sequences for Symbols from Other Character Sets
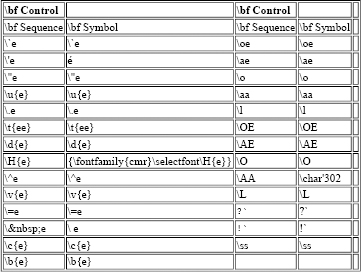
Table 7.2 shows new control sequences proposed by the TWGMLC for characters not available in standard TeX and LaTeX distributions.[87]
Table 7.2. New Control Sequences Proposed by TWGMLC


The only technical problem associated with using language-specific character sets in your input files is that you must have some way of telling TeX to perform the appropriate substitutions. One method is to use a special style file like isolatin1.[88] This style uses “active characters” to map the ISO Latin1 input character set to TeX's representation. It could be adapted to other character sets as well. Another possibility is to rely on system-dependent extensions to TeX. For example, emTeX provides extensive support for “code pages,” which address this problem.
The only other problem created by using different input character sets is one of compatibility. If you write files using the ISO Latin1 character set and send them to someone who uses a different character set, the file will appear to be incorrect.[89]
Appearances can be deceiving
A document stored on disk is really just a file containing a series of characters, each represented by a unique numerical value. For an editor to display a document, each numerical value must be translated into a visual representation of the character. Frequently this translation is performed by the operating system or computer hardware. In an analogous way, each numeric value must be translated into a printable character when the document is typeset.
Figure 7.1 shows how this translation is performed for display by the operating system and for printing by TeX (using the isolatin1 style, for example). This figure shows the disparity that occurs if the two translation tables are not the same.
Figure 7.1. Character mapping example
FIXME:
How can this arise? Well, suppose, for example, that a colleague is writing a document in French. He has a TeXnical problem that he would like me to investigate. I agree to take a look, and he sends the file to me. My colleage is using the ISO Latin1 character set in his input file because it contains many symbols that are convenient for writing French (including the guillemets). I receive the file and edit it on my PC. The file that I see displayed looks like gibberish. That's because I'm using the IBM OEM encoding on my PC, which is sufficient for English. All of the special characters in the ISO Latin1 character set appear incorrect. Bewildered, I TeX and preview the document to see what it's supposed to look like. To my surprise, the previewed document looks fine.
In this case, I can correct the problem by changing the “code page” used on my PC or by translating the input file with a program like GNU recode.[90]
Changing the Rules
In order to select languages, the TWGMLC has proposed a set of language switching macros. These are shown in Table 7.3.[91]
Selecting a language has three effects:
- It establishes the correct hyphenation environment.
Language-specific hyphenation patterns are loaded, if necessary, and correct values for the minimum length of a hyphenated word fragment are set.
At the time of this writing, hyphenation patterns are already available, or under development, for Armenian, Bulgarian, Cambodian, Catalan, Croation, Czech, Danish, Dutch, English (U.K. and U.S.), Esperanto, Estonian, Finnish, French, German, Greek (both modern and ancient), Hungarian, Icelandic, Italian, Kirundi, Latin, Lithuanian, Norwegian, Polish, Portuguese, Russian, Slovak, Swahili, Swedish, Yiddish, and Yoruba.
- It loads the correct fonts and special characters.
Even languages which use the same alphabet may have different fonts in order to provide specific features of the language. For example, the “fi” ligature makes sense only when typesetting English, and the \th and \TH macros make sense only when typesetting languages that need “{\dcr\char254}” and “{\dcr\char222}.”
Table 7.3. Language Switch Macros Proposed by TUG
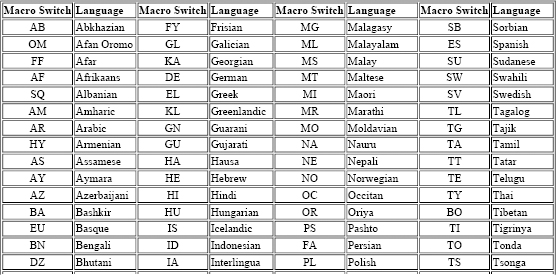
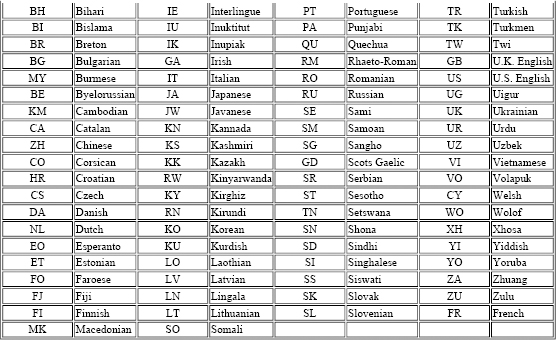
- It defines special primitive operations, if appropriate.
For example, right-to-left typesetting primitives are necessary only for languages like Hebrew which are typeset right-to-left.
Printing the Result
The Computer Modern Fonts are insufficient for typesetting languages other than English. In order to overcome this difficulty, the TeX User's Group has extended the Computer Modern encoding vector and established a new standard.
The new standard fonts are known variously as the Cork fonts, the DC fonts, and the EC fonts. These are all synonymous. The new standard was created following discussions at the TeX User's Group meeting in Cork, Ireland in 1990, hence the name Cork. The MetaFont fonts, which embody this encoding, will eventually become the EC fonts. The current versions, available now, are still being refined (in the sense that some of the letter forms are being refined; the encoding will not change). These are called the DC fonts.
There is a distinction between the standard encoding vector and the MetaFont fonts that replace Computer Modern. Therefore, I will refer to the standard encoding as the “Cork Encoding” and to the MetaFont fonts as the “DC fonts”.[92]
At the time of this writing, the DC fonts are not a complete superset of Computer Modern because the DC Math fonts have not yet been released. (The DC fonts will contain the upper-case Greek alphabet, which is currently missing from the DC fonts.) When the DC Math fonts are released, the DC fonts will be a complete superset of Computer Modern. The only apparent difference will be that the accents on the DC fonts are not at exactly the same height as the accented characters constructed with the \accent primitive using Computer Modern.[93]
The Cork Encoding is shown in Table B.3 in Appendix B, Appendix B. There are 255 symbols in this vector with one blank for special purposes. Unlike the Computer Modern fonts, which have different encoding vectors in some typefaces (Computer Modern Roman is not the same as Computer Modern Typewriter, for example), all of the DC fonts have the same encoding vector.
Several people have commented that the Cork Encoding suffers from a “design error” because it places characters in positions 0-31, which are frequently inaccessible in other applications, and because it places a nonstandard character at position 32, where a space usually occurs. This is not a design error. Bear in mind that the DC fonts are designed to be TeX output fonts. Font creators, working in other environments (for example, TrueType or PostScript) are free to divide the Cork Encoding into two separate font files and provide a virtual font for TeX that establishes the correct encoding. The motivation for putting as many symbols as possible in a single font is that TeX cannot kern across fonts.
This is not meant to imply that the DC fonts should always be virtual. In fact, the DC fonts should be the “real” fonts upon which virtual fonts are based. A virtual Computer Modern font based upon the real DC fonts is infinitely preferable to a virtual DC font built on Computer Modern because:
- You need a “real” font to make virtual fonts, and the Computer Modern fonts don't contain enough real characters.
- Expressing accented characters in MetaFont is much better than building accents inside a virtual font. The virtual font has less information to work with (it has only boxes).
- Different languages use accents at different heights. A simple “patch” to the MetaFont code for a real font with accents is far superior to introducing another set of virtual fonts for every language.
From a purely practical point of view, the correct way to deal with these and related problems is to use the babel style files.
The Babel Styles
The babel styles are a collection of style files for LaTeX that provide features for typesetting in many languages. The babel styles are compatible with Plain TeX and all versions of LaTeX. (In particular, they are being adopted as the standard multilingual styles in LaTeX2e and will be the standard in LaTeX3 when it is released.)
To date, babel styles exist for Catalan, Croatian, Cyrillic, Czech, Danish, Dutch, English, Esperanto, Finnish, French, Galician, German, Italian, Hungarian, Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, and Turkish, as well as several dialects (American as a dialect of English, for example).
Example 7.1 shows the skeletal structure of a document using the English and French styles. Within the document, the \selectlanguage control sequence is used to switch between languages.[94] The language that is in effect by default is determined when the format file is created.
Example 7.1. {A Sample Multilingual Document Using English and French}
\documentstyle[english,francais]{article}
\begin{document}
This is a document which uses both English and French. \selectlanguage{french} Mais, je ne parle plus fran\c{c}ais. \selectlanguage{english} So I won't try to make this example very long.
\end{document}
Selecting a language automatically has the following effects:
- It selects hyphenation patterns for the language. This means that paragraphs of text will be hyphenated according to the conventions of the language in use.[95] Switching hyphenation patterns is possible only if the format file being used by TeX contains hyphenation rules for language.
- It automatically translates the names of all the document elements into the selected language. For example, if you insert the \tableofcontents when French is the selected language, the table of contents will be called the “Table des mati\`eres” instead of “Table of Contents.”
- It alters the format of the date produced by the \today macro to fit the conventions of the selected language. In American, \today is “January 30, 1994”; in English it is “30th January 1994”; and in French it is “30 janvier 1994.”
- It defines particular typing shortcuts to make writing the selected language more convenient for the typist. For example, the French style makes several punctuation characters into macros so that extra space is automatically inserted before them according to French typographic conventions.
Building Multilingual Babel Formats
Building a multilingual format file is very much like building a format for a single language. The only difference is that instead of loading a single set of hyphenation patterns (generally from a file called hyphen.tex), you will need hyphenation patterns for each language that you want to use. These can be obtained from the CTAN archives in the directory tex-archive/language/hyphenation.
If you have a file called hyphen.tex on your system, rename it. This file is distributed as part of the standard TeX distribution and contains American English hyphenation patterns, so ushyphen.tex is an appropriate name.
Next, create a file called language.dat that contains one line for each language you want to use. Each line should list the language name and the file containing hyphenation patterns for that language. For example, an appropriate language.dat file for the format used to typeset Example 7.1 might contain these lines:
english ehyphen.tex francais fr8hyph.tex
Now, proceed to construct the format file using iniTeX according to the instructions distributed with the format or by following the suggestions in Chapter 4, Chapter 4. When iniTeX complains that it cannot find hyphen.tex, provide the alternate name babel.hyphen. This will use language.dat to load the appropriate hyphenation patterns and associate them with the languages you specified.
Note
The first language that you list in language.dat will be the default language for the format file that you create.
TeX Pitfalls
TeX 3.x, the Cork Encoding, and language-specific macro files are not “magic bullets” that can solve all of the problems that arise in typesetting multilingual documents or writing macros that are useful in all language contexts. Some of the deficiencies are really insoluble without changing the TeX program in ways that are not allowed by Knuth. Two such problems are mentioned here:
- The \uppercase and \lowercase primitives are problematic.
There is a strict one-to-one mapping between lowercase and uppercase letters in TeX. Unfortunately, accented letters may require different mappings. Consider these examples:
<para> \begin{tabular}{lll} <literal>\"I with two dots</literal> & \"I with two dots & What you typed \\ <literal>\"i with two dots</literal> & \"i with two dots & Result of \lowercase \\ <literal>\"\i with two dots</literal> & \"\i with two dots & Correct lowercase \end{tabular}Because no information about the accent is known, the result of passing your text to the \lowercase primitive is not correct.
This problem can be minimized by using an input character set which contains the accented letters that you need. This allows you to establish the appropriate one-to-one relationships.
Some of the characters chosen for the Cork encoding were driven by this weakness as well. The only reason that “{\dcr\char"DF}” is a glyph is so that it can be the \uppercase character for “{\dcr\char"FF}.”
TeX doesn't distinguish between a dash used in a compound word (for example, “wish-fulfillment”) and a dash used for hyphenation.
This distinction isn't necessary in English because English doesn't have any end-of-word ligatures. Imagine a language where “sh” should become “x” at the end of a word.[96] A compound word like “push-ready” should be typeset “pux-ready” whereas a word like “pushover” should remain “push-over” if it is hyphenated across a line break.
Very Complex Languages
The following sections describe TeX packages (collections of macros, fonts, and other files) that allow you to typeset languages very different from English.
Japanese
Typesetting Japanese involves solving several problems. The first is the task of entering Japanese text with an editor. There are many editors on many platforms that can handle Japanese input. Although there are also established ways to romanize Japanese text so that it can be displayed on terminals that do not provide support for Japanese input, these are bound to be inconvenient for anyone seriously writing in Japanese. If you are in a position to edit Japanese text, you are probably already aware of several good editors.
The second problem is that typesetting Japanese with TeX requires many, many fonts. The fact that a single font can hold no more than 256 symbols means that dozens (perhaps hundreds) of fonts are required to represent all of the myriad symbols used in everyday Japanese writing. There are some hard-coded limits on the number of fonts that a single TeX document can use, and it is possible to bump into them pretty quickly when typesetting a language like Japanese.
Another problem is printing the output. Assembling a collection of fonts that contain high-quality glyphs for all of the necessary characters is a time consuming and potentially expensive task. At present, the freely-available fonts are of relatively low quality.
A complete discussion of these issues, and many others can be found in Understanding Japanese Information Processing [kl:japinfoproc].
ASCII Nihongo TeX
ASCII Nihongo TeX (also known as \jtex) is a complete, Japanized version of TeX. Instead of trying to shoehorn Japanese into traditional TeX programs, all of the programs have been modified to accept files containing standard Japanese text (two bytes per character). This section describes the ASCII Corporation's version of \jtex. See the section called “the section called “NTT \jtex”” for information about NTT's version of \jtex. You can get the ASCII version of \jtex from ftp.ascii.co.jp (133.152.1.1).
ASCII Nihongo TeX is based on TeX 2.9 and can read input files coded with JIS, Shift-JIS, EUC, and KUTEN. The DVI files produced by ASCII \jtex are not standard DVI files. In order to support the large character set for Japanese writing, the DVI files use commands that are not output by standard TeX, so many drivers do not support them. You cannot process DVI files produced by ASCII \jtex with most standard DVI drivers.
Release notes with version 1.7 of \jtex indicate that it will be the last public release of \jtex. Another product, called pTeX (for Publishing TeX) may be released at some time in the future. One advantage of pTeX will be the ability to typeset vertically.
The primary disadvantage of the \jtex system is that there are no freely-available fonts for it. The authors assume that you will be using fonts resident in your printer. You may be able to purchase Japanese fonts from some font vendors, although I've seen no detailed instructions for using them with \jtex. Other, albeit more minor, disadvantages are the need to build and maintain an entire parallel TeX distribution and the fact that standard DVI drivers cannot process \jtex DVI files.
NTT \jtex
\jtex\index{NTT jtex@NTT \jtex} is a complete, Japanized version of TeX. Instead of trying to shoehorn Japanese into traditional TeX programs, all of the programs have been modified to accept files containing standard Japanese text (two bytes per character). This section describes NTT's version of \jtex. See the section called “the section called “TeX Pitfalls”” for information about ASCII Corporation's version of \jtex. You can get the NTT version of \jtex from ftp.math.metro-u.ac.jp (133.86.76.25)
NTT \jtex is based on TeX 3.14 and can read input files coded with JIS, Shift-JIS, and EUC. In addition to support for commercial Japanese fonts, NTT \jtex includes a set of fonts generated from 24x24 dot bitmaps (JIS C-6234). Unlike ASCII \jtex, NTT produces standard DVI files.
Poor Man's Japanese TeX
Poor Man's Japanese TeX (\, \pmj) is a freely-available Japanese typesetting system that sits on top of standard TeX. The Japanese sections of the input file must use the Shift-JIS encoding; a conversion program is supplied to convert JIS encoded input files into Shift-JIS. If you use another encoding, such as EUC, you will have to find some way to convert it into Shift-JIS before you can use \pmj.
\pmj solves the font problem in a clever way: MetaFont outlines for Japanese characters are mechanically produced from freely-available bitmaps. This results in relatively low quality characters, but at least they're free!
The Paulownia Court, the opening passage from the 800-year-old novel The Tale of the Genji, is shown in Figure 7.2. This sample was typeset by \pmj.
Figure 7.2. Poor Man's Japanese
The \pmj documentation lists the following advantages and disadvantages:
\pmj Advantages
- It is available now.
- It is free.
- It works with standard TeX.
- It is device independent, but has relatively poor quality fonts. The relative lack of quality is magnified by higher resolution output devices, unfortunately.
- It uses a set of free fonts mechanically produced from bitmaps.
\pmj Disadvantages
- It is somewhat crude and unlikely to be improved upon to any great extent.
- It uses low quality fonts.
- It requires a large number of fonts and as a result, lots of disk space.
- It provides no access to slanted, bold, or other Japanese type-styles.
- It cannot typeset vertically.
- It may take days to build the required fonts.
\jemtex
\jemtex is a lot like \pmj; it uses fonts constructed from a collection of 24x24 dot bitmaps. The \jemtex font maker includes a number of options for tailoring the appearance of the characters.
A sample of Japanese typeset with \jemtex is shown in Figure 7.3.
\jemtex takes a very different approach to processing Japanese text. Instead of providing TeX macros to interpret two-byte Japanese symbols in the input file, \jemtex provides a preprocessor which translates the Japanese input into equivalent TeX input. The preprocessor understands EUC and Shift-JIS input files.
Using a preprocessor has several advantages:
- TeX can process the files very quickly. Because the input files are not edited by hand, they are designed to be processed quickly by TeX rather than by human eyes.
- Only the fonts that are actually used must be loaded. A system like \pmj must load all of the Japanese fonts because it does not know which ones will actually be used. \jemtex knows exactly which fonts are required for each document.
- The preprocessor can handle subtle spacing issues automatically.
- The preprocessor can provide discretionary hyphens for TeX, thereby allowing TeX to hyphenate Japanese correctly.
Chinese
The general problems that apply to Japanese typesetting also apply to Chinese.
Poor Man's Chinese TeX
Poor Man's Chinese TeX (\pmc) is closely related to \pmj. The Chinese input files should be encoded with 8-bit GB encoding (GB 2312-80). If you use another encoding, you will have to convert it into the 8-bit GB encoding before you can use \pmc.
The \pmc package uses the same technique as \pmj to construct Chinese fonts. The relative advantages and disadvantages of \pmj apply equally to \pmc.
Two sets of Chinese characters are available: traditional and simplified.
Arabic
Typesetting in Arabic can be accomplished with the \arabTeX package. \arabTeX includes a complete set of fonts and macros for producing documents in Persian, Arabic, and related scripts. An example of Arabic is shown in Figure 7.4 on page Figure 7.4.
Figure 7.4. Arabic text typeset with ArabTeX
Hebrew
Typesetting left-to-right Hebrew (or occasional Hebrew words in an English document) is relatively easy. The required fonts and TeX macros are available from \path|noa.huji.ac.il| and on the CTAN archives in language/hebrew.[97]
Typesetting right-to-left Hebrew is more complicated. First, you will need an editor that handles right-to-left text entry, preferably one that displays Hebrew text.
After you have constructed a document that uses right-to-left Hebrew, you will need a special version of TeX, called \XeT, to process it. \XeT is a version of TeX that understands right-to-left typesetting.
Early versions of \XeT, called TeX-\XeT, produced nonstandard DVI files called IVD files. If you use TeX-\XeT, a special program called ivd2dvi must be used to translate the IVD files into DVI files before they can be printed. More recently, \XeT has been reimplemented to produce standard DVI files. The new version is called TeX\hbox{-{}-}\XeT.[98] They are functionally identical. You can get unix and PC versions of \XeT from \path|noa.huji.ac.il|. An example of Hebrew is shown in Figure 7.5 on page Figure 7.5.
[85] {Chinese and Japanese are also typeset vertically. At present, TeX does not support vertical typesetting, although there is at least one effort underway to provide that feature. See the section called “the section called “TeX Pitfalls”” for more information on vertical typesetting.}
[86] {The accent macros are shown with a lower case e; naturally, any letter that needs to be accented can be used in place of the e.}
[87] {These characters are available in the DC fonts and were not previously available in standard TeX.}
[88] {isolatin1.sty is available from the CTAN archives in macros/latex/contrib/misc/.}
[89] {If you use electronic mail to send files that use any characters other than the printable subset of 7-bit ASCII (space through tilde), you are bound to run into problems. You can combat this problem by using a wrapper (like uuencoding or MIME messages) when you send the mail, but those tools are outside the scope of this book. Ask your system administrator for more assistance with sending binary mail.}
[90] {recode is available from prep.ai.mit.edu and other places where GNU software is archived.}
[91] {These are “low-level” macros. A higher-level interface will be provided for each language. See the section called “the section called “The Babel Styles”” later in this chapter for more information.}
[92] {Because the “EC fonts” don't exist yet, I won't mention them again.}
[93] {Actually, the issue of accents is a difficult one. Different languages which have the same letters do not always place accents at the same height. This is yet another problem that will have to be resolved.}
[94] {Another control sequence, \ iflanguage, is provided so that you can write macros which are sensitive to the language in use when they are expanded.}
[95] {Paragraphs that contain multiple languages will be hyphenated according to the rules of the language in effect when the paragraph ends.}
[96] {This is a concocted example; to my knowledge, it doesn't actually appear in any language.}
[97] {At the time of this writing, the material at \path|noa.huji.ac.il| is more up-to-date than the material in the CTAN archives.}
[98] {Yes, the only difference between the names really is the number of hyphens!}
Get Making TeX Work now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

