In this section, we will develop an end-to-end stream processing pipeline that is capable of streaming data from a source system that generates continuous data, and thereafter able to publish those streams to an Apache Kafka distributed cluster. Our stream processing pipeline will then use Apache Spark to both consume data from Apache Kafka, using its Structured Streaming engine, and apply trained machine learning models to these streams in order to derive insights in real time using MLlib. The end-to-end stream processing pipeline that we will develop is illustrated in Figure 8.4:
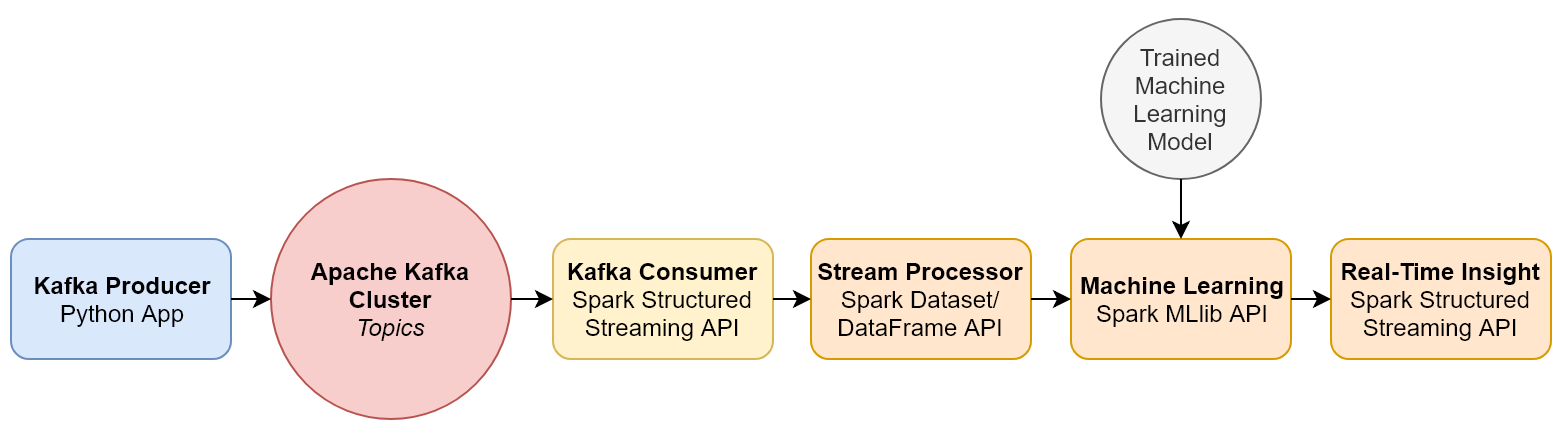
Figure 8.4: Our end-to-end stream ...

