In hierarchical clustering, each data point starts off in its own self-defined cluster—for example, if you have 10 data points in your dataset, then there will initially be 10 clusters. The two nearest clusters, as defined by the Euclidean centroid distance, for example, are then combined. This process is then repeated for all distinct clusters until eventually all data points belong in the same cluster.
This process can be visualized using a dendrogram, as illustrated in Figure 5.2:
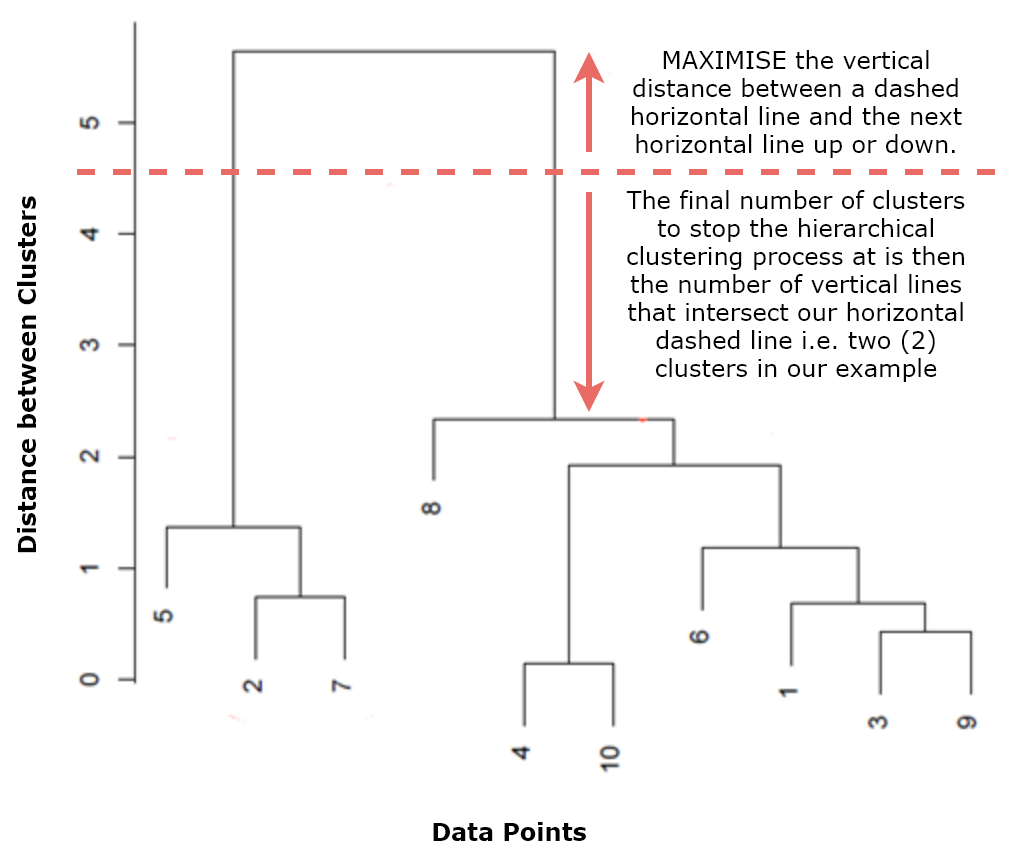
Figure 5.2: Hierarchical clustering dendrogram
A dendrogram helps us to decide when to stop the hierarchical clustering process. It is ...

