Now, imagine that we want to train an MLP using our entire letter recognition dataset, as illustrated in Figure 7.6:
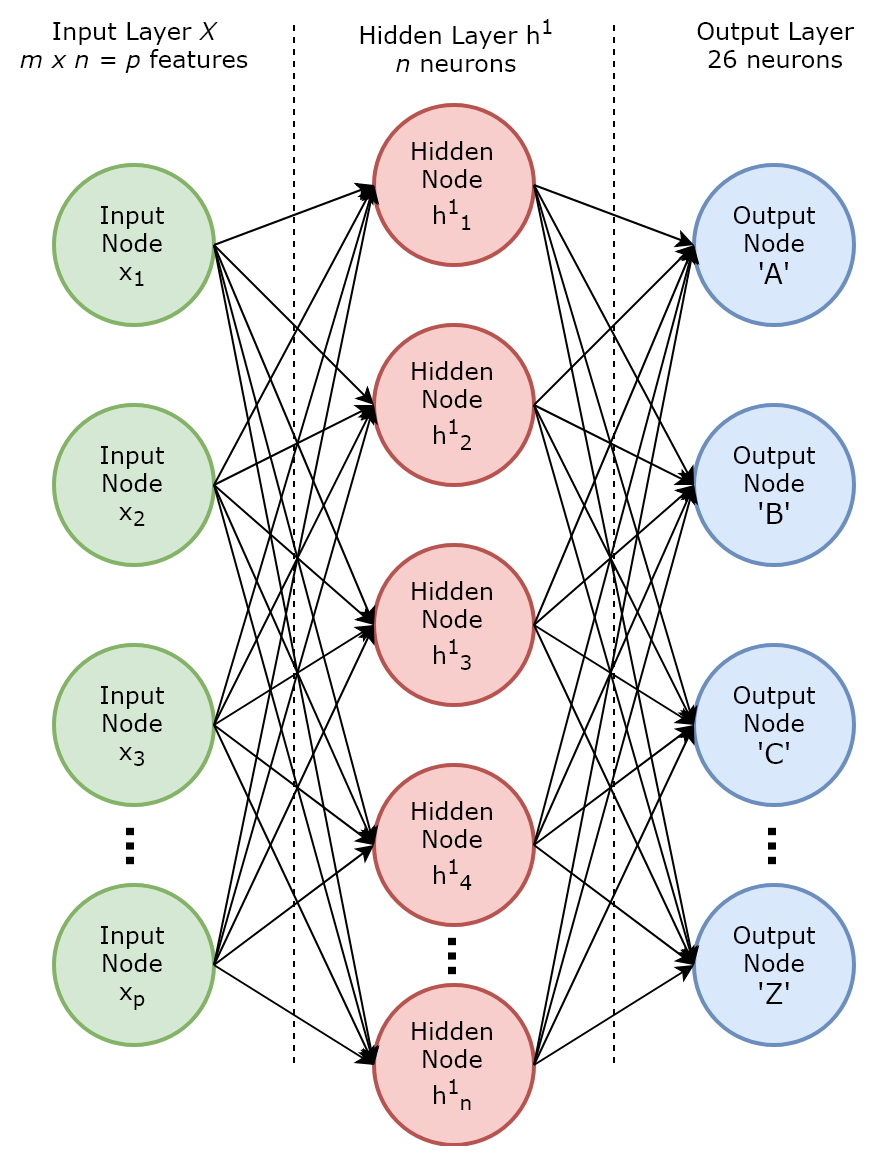
Figure 7.6: Multilayer perceptron for letter recognition
In our MLP, we have p (= m x n) neurons in our input layer that represent the p pixel-intensity values from our image. A single hidden layer has n neurons, and the output layer has 26 neurons that represent the 26 possible classes or letters in the English alphabet. When training this neural network, since we do not know initially what weights should be assigned to each layer, we initialize the weights randomly and perform a first iteration of forward ...

