Building the training and testing datasets for the baseline model
In this section, we will be generating the training dataset as well as the testing dataset. We will iterate over the files of our dataset and consider all files whose names start with the digit 12 as our test dataset. So, roughly 90% of our dataset is considered the training dataset and 10 % of our dataset is considered the testing dataset. You can refer to the code for this in the following figure:
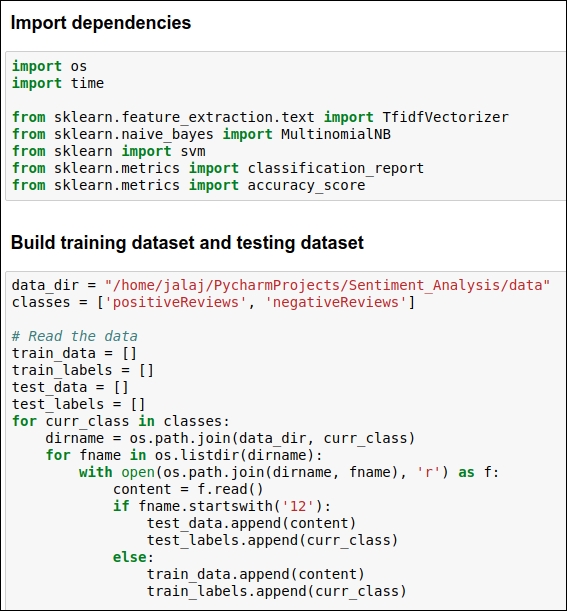
Figure 5.6: Code snippet for building the training and testing dataset
As you can see, if the filename starts with 12 then we consider the content of those files as the testing dataset. ...
Get Machine Learning Solutions now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

