One of the main challenges in text mining is transforming unstructured written natural language into structured attribute-based instances. The process involves many steps, as shown here:
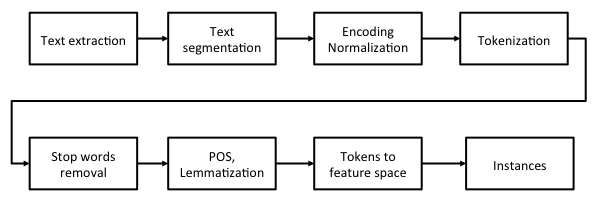
First, we extract some text from the internet, existing documents, or databases. At the end of the first step, the text could still be present in the XML format or some other proprietary format. The next step is to extract the actual text and segment it into parts of the document, for example, title, headline, abstract, and body. The third step is involved with normalizing text encoding to ensure the characters are presented in the same ...

