Chapter 4. Apache Spark as a Stream-Processing Engine
In Chapter 3, we pictured a general architectural diagram of a streaming data platform and identified where Spark, as a distributed processing engine, fits in a big data system.
This architecture informed us about what to expect in terms of interfaces and links to the rest of the ecosystem, especially as we focus on stream data processing with Apache Spark. Stream processing, whether in its Spark Streaming or Structured Streaming incarnation, is another execution mode for Apache Spark.
In this chapter, we take a tour of the main features that make Spark stand out as a stream-processing engine.
The Tale of Two APIs
As we mentioned in âIntroducing Apache Sparkâ, Spark offers two different stream-processing APIs, Spark Streaming and Structured Streaming:
- Spark Streaming
-
This is an API and a set of connectors, in which a Spark program is being served small batches of data collected from a stream in the form of microbatches spaced at fixed time intervals, performs a given computation, and eventually returns a result at every interval.
- Structured Streaming
-
This is an API and a set of connectors, built on the substrate of a SQL query optimizer, Catalyst. It offers an API based on
DataFrames and the notion of continuous queries over an unbounded table that is constantly updated with fresh records from the stream.
The interface that Spark offers on these fronts is particularly rich, to the point where this book devotes large parts explaining those two ways of processing streaming datasets. One important point to realize is that both APIs rely on the core capabilities of Spark and share many of the low-level features in terms of distributed computation, in-memory caching, and cluster interactions.
As a leap forward from its MapReduce predecessor, Spark offers a rich set of operators that allows the programmer to express complex processing, including machine learning or event-time manipulations. We examine more specifically the basic properties that allow Spark to perform this feat in a moment.
We would just like to outline that these interfaces are by design as simple as their batch counterpartsâoperating on a DStream feels like operating on an RDD, and operating on a streaming Dataframe looks eerily like operating on a batch one.
Apache Spark presents itself as a unified engine, offering developers a consistent environment whenever they want to develop a batch or a streaming application. In both cases, developers have all the power and speed of a distributed framework at hand.
This versatility empowers development agility. Before deploying a full-fledged stream-processing application, programmers and analysts first try to discover insights in interactive environments with a fast feedback loop. Spark offers a built-in shell, based on the Scala REPL (short for Read-Eval-Print-Loop) that can be used as prototyping grounds. There are several notebook implementations available, like Zeppelin, Jupyter, or the Spark Notebook, that take this interactive experience to a user-friendly web interface. This prototyping phase is essential in the early phases of development, and so is its velocity.
If you refer back to the diagram in Figure 3-1, you will notice that what we called results in the chart are actionable insightsâwhich often means revenue or cost-savingsâare generated every time a loop (starting and ending at the business or scientific problem) is traveled fully. In sum, this loop is a crude representation of the experimental method, going through observation, hypothesis, experiment, measure, interpretation, and conclusion.
Apache Spark, in its streaming modules, has always made the choice to carefully manage the cognitive load of switching to a streaming application. It also has other major design choices that have a bearing on its stream-processing capabilities, starting with its in-memory storage.
Sparkâs Memory Usage
Spark offers in-memory storage of slices of a dataset, which must be initially loaded from a data source. The data source can be a distributed filesystem or another storage medium. Sparkâs form of in-memory storage is analogous to the operation of caching data.
Hence, a value in Sparkâs in-memory storage has a base, which is its initial data source, and layers of successive operations applied to it.
Failure Recovery
What happens in case of a failure? Because Spark knows exactly which data source was used to ingest the data in the first place, and because it also knows all the operations that were performed on it thus far, it can reconstitute the segment of lost data that was on a crashed executor, from scratch. Obviously, this goes faster if that reconstitution (recovery, in Sparkâs parlance), does not need to be totally from scratch. So, Spark offers a replication mechanism, quite in a similar way to distributed filesystems.
However, because memory is such a valuable yet limited commodity, Spark makes (by default) the cache short lived.
Lazy Evaluation
As you will see in greater detail in later chapters, a good part of the operations that can be defined on values in Sparkâs storage have a lazy execution, and it is the execution of a final, eager output operation that will trigger the actual execution of computation in a Spark cluster. Itâs worth noting that if a program consists of a series of linear operations, with the previous one feeding into the next, the intermediate results disappear right after said next step has consumed its input.
Cache Hints
On the other hand, what happens if we have several operations to do on a single intermediate result? Should we have to compute it several times? Thankfully, Spark lets users specify that an intermediate value is important and how its contents should be safeguarded for later.
Figure 4-1 presents the data flow of such an operation.
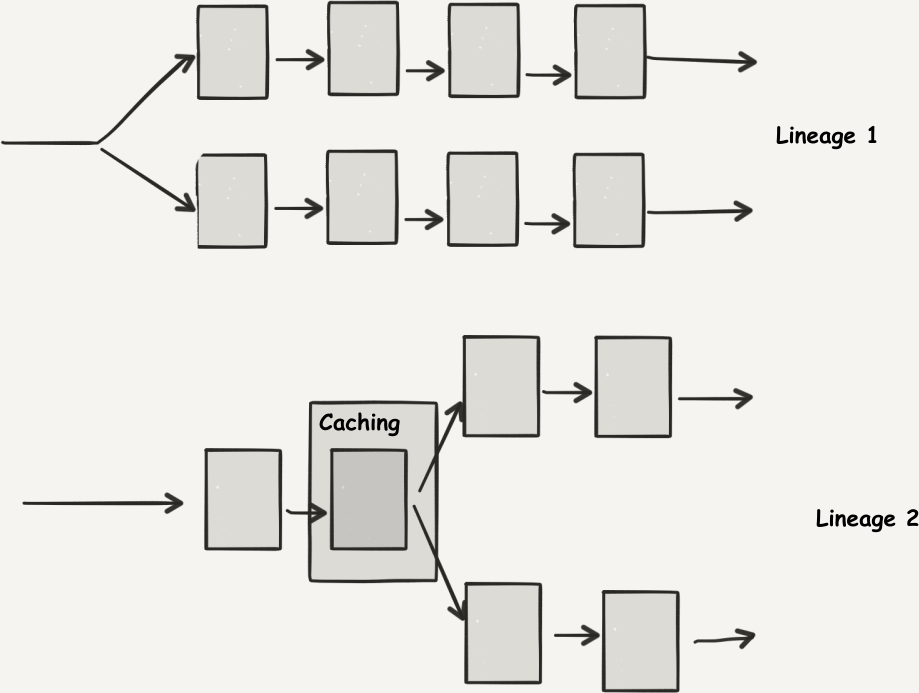
Figure 4-1. Operations on cached values
Finally, Spark offers the opportunity to spill the cache to secondary storage in case it runs out of memory on the cluster, extending the in-memory operation to secondaryâand significantly slowerâstorage to preserve the functional aspects of a data process when faced with temporary peak loads.
Now that we have an idea of the main characteristics of Apache Spark, letâs spend some time focusing on one design choice internal to Spark, namely, the latency versus throughput trade-off.
Understanding Latency
Spark Streaming, as we mentioned, makes the choice of microbatching. It generates a chunk of elements on a fixed interval, and when that interval âtickâ elapses, it begins processing the data collected over the last interval. Structured Streaming takes a slightly different approach in that it will make the interval in question as small as possible (the processing time of the last microbatch)âand proposing, in some cases, a continuous processing mode, as well. Yet, nowadays, microbatching is still the dominating internal execution mode of stream processing in Apache Spark.
A consequence of microbatching is that any microbatch delays the processing of any particular element of a batch by at least the time of the batch interval.
Firstly, microbatches create a baseline latency. The jury is still out on how small it is possible to make this latency, though approximately one second is a relatively common number for the lower bound. For many applications, a latency in the space of a few minutes is sufficient; for example:
-
Having a dashboard that refreshes you on key performance indicators of your website over the last few minutes
-
Extracting the most recent trending topics in a social network
-
Computing the energy consumption trends of a group of households
-
Introducing new media in a recommendation system
Whereas Spark is an equal-opportunity processor and delays all data elements for (at most) one batch before acting on them, some other streaming engines exist that can fast-track some elements that have priority, ensuring a faster responsivity for them. If your response time is essential for these specific elements, alternative stream processors like Apache Flink or Apache Storm might be a better fit. But if youâre just interested in fast processing on average, such as when monitoring a system, Spark makes an interesting proposition.
Throughput-Oriented Processing
All in all, where Spark truly excels at stream processing is with throughput-oriented data analytics.
We can compare the microbatch approach to a train: it arrives at the station, waits for passengers for a given period of time and then transports all passengers that boarded to their destination. Although taking a car or a taxi for the same trajectory might allow one passenger to travel faster door to door, the batch of passengers in the train ensures that far more travelers arrive at their destination. The train offers higher throughput for the same trajectory, at the expense that some passengers must wait until the train departs.
The Spark core engine is optimized for distributed batch processing. Its application in a streaming context ensures that large amounts of data can be processed per unit of time. Spark amortizes the overhead of distributed task scheduling by having many elements to process at once and, as we saw earlier in this chapter, it utilizes in-memory techniques, query optimizations, caching, and even code generation to speed up the transformational process of a dataset.
When using Spark in an end-to-end application, an important constraint is that downstream systems receiving the processed data must also be able to accept the full output provided by the streaming process. Otherwise, we risk creating application bottlenecks that might cause cascading failures when faced with sudden load peaks.
Sparkâs Polyglot API
We have now outlined the main design foundations of Apache Spark as they affect stream processing, namely a rich API and an in-memory processing model, defined within the model of an execution engine. We have explored the specific streaming modes of Apache Spark, and still at a high level, we have determined that the predominance of microbatching makes us think of Spark as more adapted to throughput-oriented tasks, for which more data yields more quality. We now want to bring our attention to one additional aspect where Spark shines: its programming ecosystem.
Spark was first coded as a Scala-only project. As its interest and adoption widened, so did the need to support different user profiles, with different backgrounds and programming language skills. In the world of scientific data analysis, Python and R are arguably the predominant languages of choice, whereas in the enterprise environment, Java has a dominant position.
Spark, far from being just a library for distributing computation, has become a polyglot framework that the user can interface with using Scala, Java, Python, or the R language. The development language is still Scala, and this is where the main innovations come in.
Caution
The coverage of the Java API has for a long time been fairly synchronized with Scala, owing to the excellent Java compatibility offered by the Scala language. And although in Spark 1.3 and earlier versions Python was lagging behind in terms of functionalities, it is now mostly caught up. The newest addition is R, for which feature-completeness is an enthusiastic work in progress.
This versatile interface has let programmers of various levels and backgrounds flock to Spark for implementing their own data analytics needs. The amazing and growing richness of the contributions to the Spark open source project are a testimony to the strength of Spark as a federating framework.
Nevertheless, Sparkâs approach to best catering to its usersâ computing goes beyond letting them use their favorite programming language.
Fast Implementation of Data Analysis
Sparkâs advantages in developing a streaming data analytics pipeline go beyond offering a concise, high-level API in Scala and compatible APIs in Java and Python. It also offers the simple model of Spark as a practical shortcut throughout the development process.
Component reuse with Spark is a valuable asset, as is access to the Java ecosystem of libraries for machine learning and many other fields. As an example, Spark lets users benefit from, for instance, the Stanford CoreNLP library with ease, letting you avoid the painful task of writing a tokenizer. All in all, this lets you quickly prototype your streaming data pipeline solution, getting first results quickly enough to choose the right components at every step of the pipeline development.
Finally, stream processing with Spark lets you benefit from its model of fault tolerance, leaving you with the confidence that faulty machines are not going to bring the streaming application to its knees. If you have enjoyed the automatic restart of failed Spark jobs, you will doubly appreciate that resiliency when running a 24/7 streaming operation.
In conclusion, Spark is a framework that, while making trade-offs in latency, optimizes for building a data analytics pipeline with agility: fast prototyping in a rich environment and stable runtime performance under adverse conditions are problems it recognizes and tackles head-on, offering users significant advantages.
To Learn More About Spark
This book is focused on streaming. As such, we move quickly through the Spark-centric concepts, in particular about batch processing. The most detailed references are [Karau2015] and [Chambers2018].
On a more low-level approach, the official documentation in the Spark Programming guide is another accessible must-read.
Summary
In this chapter, you learned about Spark and where it came from.
-
You saw how Spark extends that model with key performance improvements, notably in-memory computing, as well as how it expands on the API with new higher-order functions.
-
We also considered how Spark integrates into the modern ecosystem of big data solutions, including the smaller footprint it focuses on, when compared to its older brother, Hadoop.
-
We focused on the streaming APIs and, in particular, on the meaning of their microbatching approach, what uses they are appropriate for, as well as the applications they would not serve well.
-
Finally, we considered stream processing in the context of Spark, and how building a pipeline with agility, along with a reliable, fault-tolerant deployment is its best use case.
Get Stream Processing with Apache Spark now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

