8 IBM Cognos Dynamic Cubes
A simple way to start thinking about memory that is required for your application is to apply
the 10:1 ratio from a data warehouse footprint to a data warehouse summary table footprint,
and then applying the same ratio to in-memory aggregate memory size. For example, a 100
GB warehouse translates to 10 GB of in-database summary tables, and 1 GB of in-memory
aggregates. This information translates to approximately 4 GB for your Java virtual machine
(JVM) heap to support this application. Although this is a good starting point, your specific
application might have different requirements.
For more information about hardware requirements, see Understanding Hardware
Requirements for Dynamic Cubes from the business analytics proven practices website:
http://www.ibm.com/developerworks/analytics/practices.html
1.5 Comparison to other IBM cube technologies
Different data requirements require different data solutions. One data path cannot be
proficient at solving widely different data problems. Therefore, IBM Cognos has technologies
that are built to suit specific application requirements. Table 1-1 is intended to help you better
understand the primary use case for each technology. However, carefully consider your
individual application requirements when you make a decision.
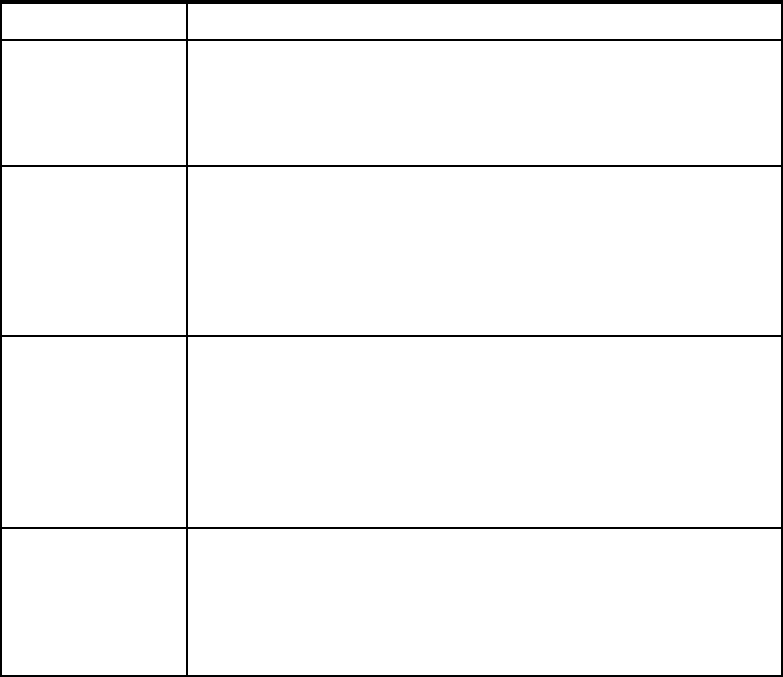
Table 1-1 Use cases for Cognos Dynamic Cubes
Cube technology Primary use cases
TM1
In-memory cube
technology with
write-back support
Is optimal for write-back, what-if analysis, planning and budgeting, or
other specialized applications.
Can handle medium data volumes. Cube is run 100% in memory.
Aggregation occurs on demand, which can affect performance with
high data and high user volumes.
Dynamic Cubes
In-memory
accelerator for
dimensional
analysis
Is optimal for read-only reporting and analytics over large data
volumes.
Provides extensive in-memory caching for performance, backed by
aggregate awareness to use the power and scalability of a relational
database.
Star or snowflake schema is required in underlying database (use to
maximize performance).
PowerCubes
File-based cube with
pre-aggregation
Is optimal to provide consistent interactive analysis experience to
large number of users when the data source is an operational or
transactional system, and a star or snowflake data structure cannot
be achieved.
Pre-aggregated cube architecture requires careful management
using cube groups to achieve scalability.
Data latency is inherent with a pre-aggregated cube technology,
where data movement into the cube is required.
OLAP Over
Relational (OOR)
Dimensional view of
a relational
database
Is optimal to easily create a dimensional data exploration experience
over low data volumes in an operational or transactional system, and
where latency must be carefully managed.
Caching on the Dynamic Query server helps performance.
Processing associated with operational or transactional system
affects performance.
Get IBM Cognos Dynamic Cubes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

