Chapter 4. Collections and Associations
No, this isn’t about taxes or politics. Now that we’ve seen how easy it is to get individual objects into and out of a database, it’s time to see how to work with groups and relationships between objects. Happily, it’s no more difficult.
Mapping Collections
In any real application you’ll be managing lists and groups of things. Java provides a healthy and useful set of library classes to help with this: the Collections utilities. Hibernate provides natural ways for mapping database relationships onto Collections, which are usually very convenient. You do need to be aware of a couple semantic mismatches, generally minor. The biggest is the fact that Collections don’t provide “bag” semantics, which might frustrate some experienced database designers. This gap isn’t Hibernate’s fault, and it even makes some effort to work around the issue.
Note
Bags are like sets, except that the same value can appear more than once.
Enough abstraction! The Hibernate reference manual does a good job
of discussing the whole bag issue, so let’s leave it and look at a working
example of mapping a collection where the relational and Java models fit
nicely. It might seem natural to build on the Track
examples from Chapter 2 and group them into albums, but that’s not
the simplest place to start, because organizing an album involves tracking
additional information, like the disc on which the track is found (for
multidisc albums), and other such finicky details. So let’s add artist
information to our database.
Note
As usual, the examples assume you followed the steps in the previous chapters. If you did not, download the example source as a starting point.
The information of which we need to keep track for artists is, at least initially, pretty simple. We’ll start with just the artist’s name. And each track can be assigned a set of artists, so we know who to thank or blame for the music, and you can look up all tracks by an artist you like. (It really is critical to allow more than one artist to be assigned to a track, yet so few music management programs get this right. The task of adding a separate link to keep track of composers is left as a useful exercise for the reader after understanding this example.)
How do I do that?
For now, our Artist class doesn’t need
anything other than a name property
(and its key, of course). Setting up a mapping document for it will be
easy. Create the file Artist.hbm.xml in the same directory as the
Track mapping document, with the contents shown
in Example 4-1.
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="com.oreilly.hh.data.Artist" table="ARTIST">
<meta attribute="class-description">
Represents an artist who is associated with a track or album.
@author Jim Elliott (with help from Hibernate)
</meta>
<id name="id" type="int" column="ARTIST_ID">
<meta attribute="scope-set">protected</meta>
<generator class="native"/>
</id>
<property name="name" type="string">  <meta attribute="use-in-tostring">true</meta>
<column name="NAME" not-null="true" unique="true" index="ARTIST_NAME"/>
</property>
<set name="tracks" table="TRACK_ARTISTS" inverse="true">
<meta attribute="use-in-tostring">true</meta>
<column name="NAME" not-null="true" unique="true" index="ARTIST_NAME"/>
</property>
<set name="tracks" table="TRACK_ARTISTS" inverse="true"> 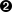 <meta attribute="field-description">Tracks by this artist</meta>
<meta attribute="field-description">Tracks by this artist</meta>  <key column="ARTIST_ID"/>
<many-to-many class="com.oreilly.hh.data.Track" column="TRACK_ID"/>
</set>
</class>
</hibernate-mapping>
<key column="ARTIST_ID"/>
<many-to-many class="com.oreilly.hh.data.Track" column="TRACK_ID"/>
</set>
</class>
</hibernate-mapping>-
Our mapping for the
nameproperty introduces a couple of refinements to both the code generation and schema generation phases. Theuse-in-tostringmetatag causes the generated class to include a customtoString()method that shows the artist’s name as well as the cryptic hash code when it is printed, as an aid for debugging (you can see the result near the bottom of Example 4-4). And expanding thecolumnattribute into a full-blown tag allows us finer-grained control over the nature of the column, which we use in this case to add an index for efficient lookup and sorting by name.-
Notice that we can represent the fact that an artist is associated with one or more tracks quite naturally in this file. This mapping tells Hibernate to add a property named
tracksto ourArtistclass, whose type is an implementation ofjava.util.Set. This will use a new table namedTRACK_ARTISTSto link to theTrackobjects for which thisArtistis responsible. The attributeinverse=trueis explained later in the discussion of Example 4-3, where the bidirectional nature of this association is examined.The
TRACK_ARTISTStable we just called into existence will contain two columns:TRACK_IDandARTIST_ID. Any rows appearing in this table will mean that the specifiedArtistobject has something to do with the specifiedTrackobject. The fact that this information lives in its own table means that there is no restriction on how many tracks can be linked to a particular artist, nor how many artists are associated with a track. That’s what is meant by a “many-to-many” association[2].On the flip side, since these links are in a separate table you have to perform a join query in order to retrieve any meaningful information about either the artists or the tracks. This is why such tables are often called “join tables.” Their whole purpose is to join other tables together.
Finally, notice that unlike the other tables we’ve set up in our schema,
TRACK_ARTISTSdoes not correspond to any mapped Java object. It is used only to implement the links betweenArtistandTrackobjects, as reflected byArtist’stracksproperty.-
The
field-descriptionmetatag can be used to provide JavaDoc descriptions for collections and associations as well as plain old value fields. This is handy in situations where the field name isn’t completely self-documenting.
The tweaks and configuration choices provided by the mapping
document, especially when aided by meta tags, give you a great deal of
flexibility over how the source code and database schema are built.
Nothing can quite compare to the control you can obtain by writing them
yourself, but most common needs and scenarios appear to be within reach
of the mapping-driven generation tools. This is great news, because they
can save you a lot of tedious typing!
Once we’ve created Artist.hbm.xml we need to add it to the list of mapping resources in our hibernate.cfg.xml. Open up the hibernate.cfg.xml file in src, and add the line shown in bold in Example 4-2.
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
...
<mapping resource="com/oreilly/hh/data/Track.hbm.xml"/>
<mapping resource="com/oreilly/hh/data/Artist.hbm.xml"/>
</session-factory>
</hibernate-configuration>
With that in place, let’s also add the collection of
Artists to our Track
class. Edit Track.hbm.xml to
include the new artists property as shown
in Example 4-3 (the
new content is shown in bold).
... <property name="playTime" type="time"> <meta attribute="field-description">Playing time</meta> </property><set name="artists" table="TRACK_ARTISTS"><key column="TRACK_ID"/><many-to-many class="com.oreilly.hh.data.Artist" column="ARTIST_ID"/></set><property name="added" type="date"> <meta attribute="field-description">When the track was created</meta> </property> ...
This adds a similar Setartists to the
Track class. It uses the same TRACK_ARTISTS join table introduced earlier in
Example 4-1 to link
to the Artist objects we mapped there. This sort
of bidirectional association is very useful. It’s important to let Hibernate know explicitly what’s
going on by marking one end of the association as
inverse. In the case of a many-to-many
association like this one, the choice of which side to call the inverse
mapping isn’t crucial, although it does affect when Hibernate will
decide to automatically update the join table. The fact that the join
table is named “track artists” makes the link from artists back to
tracks the best choice for the inverse end, if only from the perspective
of people trying to understand the database.
Hibernate itself doesn’t care which end we choose, as long as we
mark one of the directions as inverse. That’s why we did so in Example 4-1. With this
configuration, if we make changes to the artists set in a
Track object, Hibernate will know it needs to
update the TRACK_ARTISTS table. If we
make changes to the tracks set in an
Artist object, this will not
automatically happen.
While we’re enhancing the Track mapping
document we might as well flesh out the title property similar to
how we fleshed out name in
Artist:
... <property name="title" type="string"><meta attribute="use-in-tostring">true</meta><column name="TITLE"not-null="true"index="TRACK_TITLE"/></property>...
With the new and updated mapping files in place, we’re ready to
rerun ant codegen to update the
Track source code, and create the new
Artist source. If you do that and look at
Track.java, you’ll see the new
Set-valued property artists has been added, as has a new
toString() method. Example 4-4 shows the content
of the new Artist.java.
package com.oreilly.hh.data;
// Generated Sep 3, 2007 10:12:45 PM by Hibernate Tools 3.2.0.b9
import java.util.HashSet;
import java.util.Set;
/**
* Represents an artist who is associated with a track or album.
* @author Jim Elliott (with help from Hibernate)
*/
public class Artist implements java.io.Serializable {
private int id;
private String name;
/**
* Tracks by this artist
*/
private Set tracks = new HashSet(0);
public Artist() {
}
public Artist(String name) {
this.name = name;
}
public Artist(String name, Set tracks) {
this.name = name;
this.tracks = tracks;
}
public int getId() {
return this.id;
}
protected void setId(int id) {
this.id = id;
}
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
/**
* * Tracks by this artist
*/
public Set getTracks() {
return this.tracks;
}
public void setTracks(Set tracks) {
this.tracks = tracks;
}
/**
* toString
* @return String
*/
public String toString() {
StringBuffer buffer = new StringBuffer();
buffer.append(getClass().getName()).append("@").append(
Integer.toHexString(hashCode())).append(" [");
buffer.append("name").append("='").append(getName()).append("' ");
buffer.append("]");
return buffer.toString();
}
}Note
Anyone looking for a popcorn project to pitch in on Hibernate?
How about changing the tools’ code generation to use a
StringBuilder rather than a
StringBuffer in
toString()?
Why didn’t it work?
If you see Hibernate complaining about something along these lines, don’t despair:
[hibernatetool] An exception occurred while running exporter #2:hbm2java (Generates a set of .java files) [hibernatetool] To get the full stack trace run ant with -verbose [hibernatetool] org.hibernate.MappingNotFoundException: resource: com/oreilly/hh/data/Track.hbm.xml not found [hibernatetool] A resource located at com/oreilly/hh/data/Track.hbm.xml was not found. [hibernatetool] Check the following: [hibernatetool] [hibernatetool] 1) Is the spelling/casing correct ? [hibernatetool] 2) Is com/oreilly/hh/data/Track.hbm.xml available via the c lasspath ? [hibernatetool] 3) Does it actually exist ? BUILD FAILED
This just means you were starting from a fresh download of the sample directory, and you’ve run into the kind of Ant premature classpath calcification issues we mentioned in “Cooking Up a Schema” back in Chapter 2. If you try it a second time (or if you had manually run ant prepare once before trying it in the first place), it should work fine.
What about…
…modern (Java 5) considerations of type-safety? These classes are using nongeneric versions of the Collections classes, and will cause compiler warnings like the following when code is compiled against them with current Java compilers:
[javac] Note: /Users/jim/svn/oreilly/hib_dev_2e/current/scratch/ch04/src/com
/oreilly/hh/CreateTest.java uses unchecked or unsafe operations.
[javac] Note: Recompile with -Xlint:unchecked for details.It’d
sure be nice if there was a way to generate code that used Java Generics, to tighten up the things we can put in the
tracks Set
and thereby avoid these warnings and all the tedious type casting that
used to mar the Collections experience. Well, we’re in luck, because
it’s actually pretty easy to do so, by modifying the way we invoke
hbm2java. Edit build.xml and change the hmb2java line so that it looks like
this:
<hbm2java jdk5="true"/>This tells the tool that we’re in a Java 5 (or later) environment, so we’d like to take advantage of its useful new capabilities. After this change, run ant codegen again, and notice the changes in the generated code, which are highlighted in Example 4-5.
...
private Set<Track> tracks = new HashSet<Track>(0);
...
public Artist(String name, Set<Track> tracks) {
this.name = name;
this.tracks = tracks;
}
...
public Set<Track> getTracks() {
return this.tracks;
}
public void setTracks(Set<Track> tracks) {
this.tracks = tracks;
}
...This is the code I was hoping to see—nice type-safe use of the Java Generics capabilities added to Collections in Java 5. Similar treatment was given to the artists property in Track.java. Let’s take a peek at the new “full” constructor as an example, and so we can see how to invoke it later in Example 4-9:
public Track(String title, String filePath, Date playTime,
Set<Artist> artists, Date added, short volume) {
...
}Note
Ah, much better. It’s amazing how much benefit you can get from one little configuration parameter.
Our schema change has created a new parameterized
Set argument for the artists property between playTime and Date added.
Now that the classes are created (or updated), we can use ant schema to build the new database schema that supports them.
Tip
Of course you should watch for error messages when generating your source code and building your schema, in case there are any syntax or conceptual errors in the mapping document. Not all exceptions that show up are signs of real problems you need to address, though. In experimenting with evolving this schema, I ran into some exception reports because Hibernate tried to drop foreign key constraints that hadn’t been set up by previous runs. The schema generation continued past them, scary as they looked, and worked correctly. This may improve in later versions (of Hibernate or HSQLDB, or perhaps just the SQL dialect implementation), but the behavior has been around for several years now.
The generated schema contains the tables we’d expect, along with indices and some clever foreign key constraints. As our object model gets more sophisticated, the amount of work (and expertise) being provided by Hibernate is growing nicely. The full output from the schema generation is rather long, but Example 4-6 shows the highlights.
[hibernatetool] drop table ARTIST if exists; [hibernatetool] drop table TRACK if exists; [hibernatetool] drop table TRACK_ARTISTS if exists; [hibernatetool] create table ARTIST (ARTIST_ID integer generated by default as identity (start with 1), NAME varchar(255) not null, primary key (ARTIST_ID), unique (NAME)); [hibernatetool] create table TRACK (TRACK_ID integer generated by default as identity (start with 1), TITLE varchar(255) not null, filePath varchar(255) not null, playTime time, added date, volume smallint not null, primary key (TRACK_ID)); [hibernatetool] create table TRACK_ARTISTS (ARTIST_ID integer not null, TRACK_ID integer not null, primary key (TRACK_ID, ARTIST_ID)); [hibernatetool] create index ARTIST_NAME on ARTIST (NAME); [hibernatetool] create index TRACK_TITLE on TRACK (TITLE); [hibernatetool] alter table TRACK_ARTISTS add constraint FK72EFDAD8620962DF foreign key (ARTIST_ID) references ARTIST; [hibernatetool] alter table TRACK_ARTISTS add constraint FK72EFDAD82DCBFAB5 foreign key (TRACK_ID) references TRACK;
Note
Cool! I didn’t even know how to do some of that stuff in HSQLDB!
Figure 4-1 shows HSQLDB’s tree view representation of the schema after these additions. I’m not sure why two separate indices are used to establish the uniqueness constraint on artist names, but that seems to be an implementation quirk in HSQLDB, and this approach will work just fine.
What just happened?
We’ve set up an object model that allows our
Track and Artist objects
to keep track of an arbitrary set of relationships to each other. Any
track can be associated with any number of artists, and any artist can
be responsible for any number of tracks. Getting this set up right can
be challenging, especially for people who are new to object-oriented
code or relational databases (or both!), so it’s nice to have the help
of Hibernate. But just wait until you see how easy it is to work with
data in this setup.
It’s worth emphasizing that the links between artists and tracks
are not stored in the ARTIST or
TRACK tables themselves. Because
they are in a many-to-many association, meaning that an artist
can be associated with many tracks, and many artists can be associated
with a track, these links are stored in a separate join table called
TRACK_ARTISTS. Rows in this table
pair an ARTIST_ID with a TRACK_ID, to indicate that the specified
artist is associated with the specified track. By creating and deleting
rows in this table, we can set up any pattern of associations we need.
(This is how many-to-many relationships are always represented in
relational databases; the chapter of George Reese’s Java
Database Best Practices cited earlier is a good introduction
to data models like this.)
Keeping this in mind, you will also notice that our generated
classes don’t contain any code to manage the TRACK_ARTISTS table. Nor will the upcoming
examples that create and link persistent Track
and Artist objects. They don’t have to, because
Hibernate’s special Collection classes take care
of all those details for us, based on the mapping information we added
to Examples 4-1 and 4-3.
Persisting Collections
Our first task is to enhance the
CreateTest class to take advantage of the new richness in our schema,
creating some artists and associating them with tracks.
How do I do that?
To begin with, add some helper methods to CreateTest.java to simplify the task, as shown in Example 4-7 (with changes and additions in bold).
package com.oreilly.hh; import org.hibernate.*; import org.hibernate.cfg.Configuration; import com.oreilly.hh.data.*; import java.sql.Time; import java.util.*;moresample data, letting Hibernate persist it for us. */ public class CreateTest {/*** Look up an artist record given a name.* @param name the name of the artist desired.* @param create controls whether a new record should be created if* the specified artist is not yet in the database.* @param session the Hibernate session that can retrieve data* @return the artist with the specified name, or <code>null</code> if no* such artist exists and <code>create</code> is <code>false</code>.* @throws HibernateException if there is a problem.*/public static Artist getArtist(String name, boolean create, Session session){Query query = session.getNamedQuery("com.oreilly.hh.artistByName");query.setString("name", name);Artist found = (Artist)query.uniqueResult();if (found == null && create) {
found = new Artist(name, new HashSet<Track>());session.save(found);}return found;}/*** Utility method to associate an artist with a track*/private static void addTrackArtist(Track track, Artist artist) {
track.getArtists().add(artist);}
As is so often the case when working with Hibernate, this code is pretty simple and self-explanatory:
-
We used to import
java.util.Date, but we’re now importing the wholeutilpackage to work withCollections. The “*” is bold to highlight this, but it’s easy to miss when scanning the example.-
We’ll want to reuse the same artists if we create multiple tracks for them—that’s the whole point of using an
Artistobject rather than just storing strings—so ourgetArtist()method does the work of looking them up by name.-
The
uniqueResult()method is a convenience feature of theQueryinterface, perfect in situations like this, where we know we’ll either get one result or none. It saves us the trouble of getting back a list of results, checking the length and extracting the first result if it’s there. We’ll either get back the single result ornullif there were none. (We’ll be thrown an exception if there is more than one result—you might think ouruniqueconstraint on the column would prevent that, but SQL is case-sensitive, and our query is matching insensitively, so it’s up to us to be sure we always callgetArtist()to see if an artist exists before creating a new record.)-
So all we need to do is check for
nulland create a newArtistif we didn’t find one and the create flag indicates we’re supposed to.Tip
If we left out the
session.save()call, our artists would remain transient. (Itinerant painters? Sorry.) Hibernate is helpful enough to throw an exception if we try to commit our transaction in this state, by detecting references from persistentTrackinstances to transientArtistinstances. You may want to review the lifecycle discussion in Chapter 3, and “Lifecycle Associations” in Chapter 5, which explores this in more depth.-
The
addTrackArtist()method is almost embarrassingly simple. It’s just ordinary JavaCollectionscode that grabs theSetof artists belonging to aTrackand adds the specifiedArtistto it. Can that really do everything we need? Where’s all the database manipulation code we normally have to write? Welcome to the wonderful world of object/relational mapping tools!
You might have noticed that
getArtist() uses a named query to retrieve
the Artist record. In Example 4-8, we will add that
at the end of Artist.hbm.xml.
(Actually, we could put it in any mapping file, but this is the most
sensible place, since it relates to Artist
records.)
<query name="com.oreilly.hh.artistByName">
<![CDATA[
from Artist as artist
where upper(artist.name) = upper(:name)
]]>
</query>We use the upper() function to
perform a case-insensitive comparison of artists’ names, so that we
retrieve the artist even if the capitalization is different during
lookup than what’s stored in the database. This sort of case-insensitive
but preserving architecture, a user-friendly concession to the way
humans like to work, is worth implementing whenever possible. Databases
other than HSQLDB may have a different name for the function that
converts strings to uppercase, but there should be one available. And
we’ll see a nice Java-oriented, database-independent way of doing this
sort of thing in Chapter 8.
Now we can use this infrastructure to actually create some tracks
with linked artists. Example 4-9 shows the remainder of the
CreateTest class with the additions marked in
bold. Edit your copy to match (or download it to save the
typing).
public static void main(String args[]) throws Exception {
// Create a configuration based on the XML file we've put
// in the standard place.
Configuration config = new Configuration();
config.configure();
// Get the session factory we can use for persistence
SessionFactory sessionFactory = config.buildSessionFactory();
// Ask for a session using the JDBC information we've configured
Session session = sessionFactory.openSession();
Transaction tx = null;
try {
// Create some data and persist it
tx = session.beginTransaction();
Track track = new Track("Russian Trance",
"vol2/album610/track02.mp3",
Time.valueOf("00:03:30"),
new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("PPK", true, session));
session.save(track);
track = new Track("Video Killed the Radio Star",
"vol2/album611/track12.mp3",
Time.valueOf("00:03:49"), new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("The Buggles", true, session));
session.save(track);
track = new Track("Gravity's Angel",
"vol2/album175/track03.mp3",
Time.valueOf("00:06:06"), new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("Laurie Anderson", true, session));
session.save(track);
track = new Track("Adagio for Strings (Ferry Corsten Remix)",
"vol2/album972/track01.mp3",
Time.valueOf("00:06:35"), new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("William Orbit", true, session));
addTrackArtist(track, getArtist("Ferry Corsten", true, session));
addTrackArtist(track, getArtist("Samuel Barber", true, session));
session.save(track);
track = new Track("Adagio for Strings (ATB Remix)",
"vol2/album972/track02.mp3",
Time.valueOf("00:07:39"), new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("William Orbit", true, session));
addTrackArtist(track, getArtist("ATB", true, session));
addTrackArtist(track, getArtist("Samuel Barber", true, session));
session.save(track);
track = new Track("The World '99",
"vol2/singles/pvw99.mp3",
Time.valueOf("00:07:05"), new HashSet<Artist>(),
new Date(), (short)0);
addTrackArtist(track, getArtist("Pulp Victim", true, session));
addTrackArtist(track, getArtist("Ferry Corsten", true, session));
session.save(track);
track = new Track("Test Tone 1",
"vol2/singles/test01.mp3",
Time.valueOf("00:00:10"), new HashSet<Artist>(),
new Date(), (short)0);
session.save(track);
// We're done; make our changes permanent
tx.commit();
} catch (Exception e) {
if (tx != null) {
// Something went wrong; discard all partial changes
tx.rollback();
}
throw new Exception("Transaction failed", e);
} finally {
// No matter what, close the session
session.close();
}
// Clean up after ourselves
sessionFactory.close();
}
}The changes to the existing code are pretty minimal:
-
The lines that created the three tracks from Chapter 3 need only a single new parameter each to supply an initially empty set of
Artistassociations. Each also gets a new follow-up line establishing an association to the artist for that track. We could have structured this code differently, by writing a helper method to create the initialHashSetcontaining the artist, so we could do this all in one line. The approach we actually used scales better to multiartist tracks, as the next section illustrates.-
The largest chunk of new code simply adds three new tracks to show how multiple artists per track are handled. If you like electronica and dance remixes (or classical for that matter), you know how important an issue that can be. Because we set the links up as collections, it’s simply a matter of adding each artist link to the tracks.
-
Finally, we add a track with no artist associations to see how that behaves. Now you can run ant ctest to create the new sample data containing tracks, artists, and associations between them.
Tip
If you’re making changes to your test data creation program and
you want to try it again starting from an empty database, issue the
command ant schema ctest. This
useful trick tells Ant to run the schema and ctest targets one after the other. Running
schema blows away any existing
data; then ctest gets to create it
anew.
Note
Of course, in real life you’d be getting this data into the database in some other way—through a user interface, or as part of the process of importing the actual music. But your unit tests might look like this.
What just happened?
There’s no visible output from running ctest beyond the SQL statements Hibernate is
using (if you still have show_sql
set to true in hibernate.cfg.xml) and those aren’t very
informative; look at data/music.script to see what got
created or fire up ant db to look at
it via the graphical interface. Take a look at the contents of the three
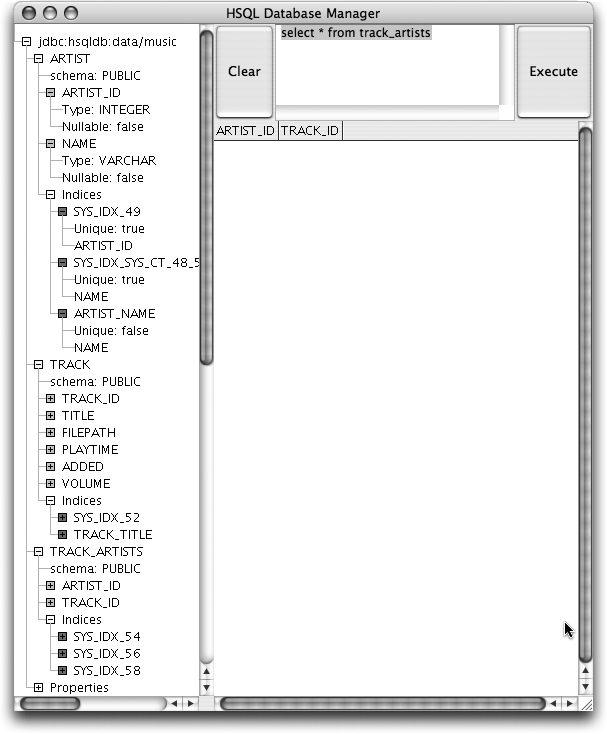
tables. Figure 4-2 shows what ended up in the join table that
represents associations between artists and tracks. The raw data is
becoming cryptic. If you’re used to relational modeling, this query
shows you everything worked. If you’re mortal like me, the next section
is more convincing; it’s certainly more fun.
Retrieving Collections
You might expect that getting the collection information back out
of the database is similarly easy. You’d be right! Let’s
enhance our QueryTest class so it shows us the
artists associated with the tracks it displays. Example 4-10 shows the
appropriate changes and additions in bold. Little new code is
needed.
package com.oreilly.hh;
import org.hibernate.*;
import org.hibernate.cfg.Configuration;
import com.oreilly.hh.data.*;
import java.sql.Time;
import java.util.*;
/**
* Retrieve data as objects
*/
public class QueryTest {
/**
* Retrieve any tracks that fit in the specified amount of time.
*
* @param length the maximum playing time for tracks to be returned.
* @param session the Hibernate session that can retrieve data.
* @return a list of {@link Track}s meeting the length restriction.
*/
public static List tracksNoLongerThan(Time length, Session session) {
Query query = session.getNamedQuery(
"com.oreilly.hh.tracksNoLongerThan");
query.setTime("length", length);
return query.list();
}
/**
* Build a parenthetical, comma-separated list of artist names.
* @param artists the artists whose names are to be displayed.
* @return the formatted list, or an empty string if the set was empty.
*/
public static String listArtistNames(Set<Artist> artists) {
StringBuilder result = new StringBuilder();
for (Artist artist : artists) {
result.append((result.length() == 0) ? "(" : ", ");
result.append(artist.getName());
}
if (result.length() > 0) {
result.append(") ");
}
return result.toString();
}
/**
* Look up and print some tracks when invoked from the command line.
*/
public static void main(String args[]) throws Exception {
// Create a configuration based on the XML file we've put
// in the standard place.
Configuration config = new Configuration();
config.configure();
// Get the session factory we can use for persistence
SessionFactory sessionFactory = config.buildSessionFactory();
// Ask for a session using the JDBC information we've configured
Session session = sessionFactory.openSession();
try {
// Print the tracks that will fit in seven minutes
List tracks = tracksNoLongerThan(Time.valueOf("00:07:00"),
session);
for (ListIterator iter = tracks.listIterator() ;
iter.hasNext() ; ) {
Track aTrack = (Track)iter.next();
System.out.println("Track: \"" + aTrack.getTitle() + "\" " +
listArtistNames(aTrack.getArtists()) +
aTrack.getPlayTime());
}
} finally {
// No matter what, close the session
session.close();
}
// Clean up after ourselves
sessionFactory.close();
}
}-
The first thing we add is a little utility method to format the set of artist names nicely, as a comma-delimited list inside parentheses, with proper spacing, or as nothing at all if the set of artists is empty.
-
Since all the interesting new multiartist tracks are longer than five minutes, we increase the cutoff in our query to seven minutes so we can see some results.
-
Finally, we call
listArtistNames()at the proper position in theprintln()statement describing the tracks found.
At this point, it’s time to get rid of Hibernate’s query debugging
output, because it will prevent us from seeing what we want to see. Edit
hibernate.cfg.xml in the src directory, and change the
show_sql property value to false:
...
<!-- Echo all executed SQL to stdout -->
<property name="show_sql">false</property>
...With this done, Example 4-11 shows the new output from ant qtest.
% ant qtest
Buildfile: build.xml
prepare:
compile:
[javac] Compiling 1 source file to /Users/jim/svn/oreilly/hib_dev_2e/current
/scratch/ch04/classes
qtest:
[java] Track: "Russian Trance" (PPK) 00:03:30
[java] Track: "Video Killed the Radio Star" (The Buggles) 00:03:49
[java] Track: "Gravity's Angel" (Laurie Anderson) 00:06:06
[java] Track: "Adagio for Strings (Ferry Corsten Remix)" (Ferry Corsten, Wi
lliam Orbit, Samuel Barber) 00:06:35
[java] Track: "Test Tone 1" 00:00:10
BUILD SUCCESSFUL
Total time: 2 secondsYou’ll notice two things. First, you’ll see that this is much easier
to interpret than the columns of numbers in Figure 4-2, and second,
it worked! Even in the “tricky” case of the test tone track without any
artist mappings, Hibernate takes the friendly approach of creating an
empty artists Set, sparing us from peppering our
code with the null checks we’d
otherwise need to avoid crashing with
NullPointerExceptions.
Note
But wait, there’s more! No additional code needed….
Using Bidirectional Associations
In our creation code, we established links from tracks to artists, simply by adding Java objects to appropriate
collections. Hibernate did the work of translating these associations and
groupings into the necessary cryptic entries in a join table it created
for that purpose. It allowed us with easy, readable code to establish and
probe these relationships. But, remember that we made this association
bidirectional—the Artist class has a collection of
Track associations, too. We didn’t bother to store
anything in there.
The great news is that we don’t have to. Because we marked this as
an inverse mapping in the Artist mapping document,
Hibernate understands that when we add an Artist
association to a Track, we’re implicitly adding
that Track as an association to the
Artist at the same time.
Warning
This convenience works only when you make changes to the “primary”
mapping, in which case they propagate to the inverse mapping. If
you make changes only to the inverse mapping—in our case, the
Set of tracks in the
Artist object—they will not be persisted. This
unfortunately means your code must be sensitive to which mapping is the
inverse.
Let’s build a simple interactive graphical application that can help us check whether the artist-to-track links really show up. When you type in an artist’s name, it will show you all the tracks associated with that artist. A lot of the code is very similar to our first query test. Create the file QueryTest2.java and enter the code shown in Example 4-12.
package com.oreilly.hh;
import org.hibernate.*;
import org.hibernate.cfg.Configuration;
import com.oreilly.hh.data.*;
import java.sql.Time;
import java.util.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
/**
* Provide a user interface to enter artist names and see their tracks.
*/
public class QueryTest2 extends JPanel {
JList list; // Will contain tracks associated with current artist
DefaultListModel model; // Lets us manipulate the list contents
/**
* Build the panel containing UI elements
*/
public QueryTest2() {
setLayout(new BorderLayout());
model = new DefaultListModel();
list = new JList(model);
add(new JScrollPane(list), BorderLayout.SOUTH);
final JTextField artistField = new JTextField(28);
artistField.addKeyListener(new KeyAdapter() {
public void keyTyped(KeyEvent e) {
SwingUtilities.invokeLater(new Runnable() {
public void run() {
updateTracks(artistField.getText());
}
});
}
});
add(artistField, BorderLayout.EAST);
add(new JLabel("Artist: "), BorderLayout.WEST);
}
/**
* Update the list to contain the tracks associated with an artist
*/
private void updateTracks(String name) {
model.removeAllElements(); // Clear out previous tracks
if (name.length() < 1) return; // Nothing to do
try {
// Ask for a session using the JDBC information we've configured
Session session = sessionFactory.openSession();
try {
Artist artist = CreateTest.getArtist(name, false, session);
if (artist == null) { // Unknown artist
model.addElement("Artist not found");
return;
}
// List the tracks associated with the artist
for (Track aTrack : artist.getTracks()) {  model.addElement("Track: \"" + aTrack.getTitle() +
"\", " + aTrack.getPlayTime());
}
} finally {
model.addElement("Track: \"" + aTrack.getTitle() +
"\", " + aTrack.getPlayTime());
}
} finally {  // No matter what, close the session
session.close();
}
} catch (Exception e) {
System.err.println("Problem updating tracks:" + e);
e.printStackTrace();
}
}
private static SessionFactory sessionFactory; // Used to talk to Hibernate
/**
* Set up Hibernate, then build and display the user interface.
*/
public static void main(String args[]) throws Exception {
// Load configuration properties, read mappings for persistent classes
Configuration config = new Configuration();
// No matter what, close the session
session.close();
}
} catch (Exception e) {
System.err.println("Problem updating tracks:" + e);
e.printStackTrace();
}
}
private static SessionFactory sessionFactory; // Used to talk to Hibernate
/**
* Set up Hibernate, then build and display the user interface.
*/
public static void main(String args[]) throws Exception {
// Load configuration properties, read mappings for persistent classes
Configuration config = new Configuration();  config.configure();
// Get the session factory we can use for persistence
sessionFactory = config.buildSessionFactory();
// Set up the UI
JFrame frame = new JFrame("Artist Track Lookup");
config.configure();
// Get the session factory we can use for persistence
sessionFactory = config.buildSessionFactory();
// Set up the UI
JFrame frame = new JFrame("Artist Track Lookup");  frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setContentPane(new QueryTest2());
frame.setSize(400, 180);
frame.setVisible(true);
}
}
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setContentPane(new QueryTest2());
frame.setSize(400, 180);
frame.setVisible(true);
}
}Note
Yes, this is a shameless plug.
The bulk of the novel code in this example deals with setting up a Swing user interface. It’s actually a rather primitive interface, and won’t resize nicely, but dealing with such details would make the code larger, and really falls outside the scope of this book. If you want examples of how to build rich, quality, Swing interfaces, check out our Java Swing, Second Edition (O’Reilly). It’s much thicker so it has room for all that good stuff.
-
The only item I want to highlight in the constructor is the
KeyListenerthat gets added toartistField. This rather tricky bit of code creates an anonymous class whosekeyTyped()method is invoked whenever the user types in the artist text field.-
That method tries to update the track display by checking whether the field now contains a recognized artist name.
-
Unfortunately, at the time the method gets invoked, the text field has not yet been updated to reflect the latest keystroke, so we’re forced to defer the actual display update to a second anonymous class (this
Runnableinstance) via theinvokeLater()method ofSwingUtilities. This technique causes the update to happen when Swing “gets around to it,” which in our case means the text field will have finished updating itself.-
The
updateTracks()method that gets called at that point is where the interesting Hibernate stuff happens. It starts by clearing the list, discarding any tracks it might have previously been displaying. If the artist name is empty, that’s all it does.-
Otherwise, it opens a Hibernate session and tries to look up the artist using the
getArtist()method we wrote inCreateTest. This time we tell it not to create an artist if it can’t find the one for which we asked, so we’ll get back anullif the user hasn’t typed the name of a known artist. If that’s the case, we just display a message to that effect.-
If we do find an
Artistrecord, on the other hand,we iterate over anyTrackrecords found in the artist’s set of associated tracks, and display information about each one. All this will test whether the inverse association has worked the way we’d like it to.-
Finally (no pun intended), we make sure to close the session when we’re leaving the method, even through an exception. You don’t want to leak sessions—that’s a good way to bog down and crash your whole database environment.
-
The
main()method starts out with the same Hibernate configuration steps we’ve seen before.-
It then creates and displays the user interface frame, and sets the interface up to end the program when it’s closed. After displaying the frame,
main()returns. From that point on, the Swing event loop is in control.
Once you’ve created (or downloaded) this source file, you also need to add a new target, shown in Example 4-13, to the end of build.xml (the Ant build file) to invoke this new class.
Note
This is very similar to the existing qtest target; copy and tweak that.
<target name="qtest2" description="Run a simple Artist exploration GUI"
depends="compile">
<java classname="com.oreilly.hh.QueryTest2" fork="true">
<classpath refid="project.class.path"/>
</java>
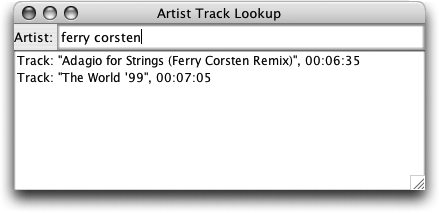
</target>Now you can fire it up by typing ant qtest2 and playing with it yourself. Figure 4-3 shows the program in action, displaying tracks for one of the artists in our sample data.
Working with Simpler Collections
The collections we’ve been looking at so far have all contained associations to other objects, which is appropriate for a chapter titled “Collections and Associations,” but these aren’t the only kind you can use with Hibernate. You can also define mappings for collections of simple values, like strings, numbers, and nonpersistent value classes.
How do I do that?
Suppose we want to be able to record some number of comments about
each track in the database. We want a new property called comments to contain the
String values of each associated comment. The new
mapping in Track.hbm.xml looks a
lot like what we did for artists, only a bit simpler[3]:
<set name="comments" table="TRACK_COMMENTS"> <key column="TRACK_ID"/> <element column="COMMENT" type="string"/> </set>
(You can put this right before the closing </class> tag in the mapping file—and you
need to if you want the Track constructor to work
with the rest of this example.)
Since we’re able to store an arbitrary number of comments for each
Track, we’re going to need a new table in which
to put them. Each comment will be linked to the proper
Track through the track’s id property.
Rebuilding the databases with ant schema shows how this gets built in the database:
[hibernatetool] create table TRACK_COMMENTS (TRACK_ID integer not null, COMMENT varchar(255)); ... [hibernatetool] 16:16:55,876 DEBUG SchemaExport:303 - alter table TRACK_COMMENTS add constraint FK105B26882DCBFAB5 foreign key (TRACK_ID) references TRACK;
Note
Data modeling junkies will recognize this as a “one-to-many” relationship.
After updating the Track class via ant codegen, we need to add another
Set at the end of each constructor invocation in
CreateTest.java, for the comments.
For example:
track = new Track("Test Tone 1",
"vol2/singles/test01.mp3",
Time.valueOf("00:00:10"), new HashSet<Artist>(),
new Date(), (short)0, new HashSet<String>());Then we can assign a comment on the following line:
track.getComments().add("Pink noise to test equalization");A quick ant ctest will compile
and run this (making sure you’ve not forgotten to add the second
HashSet of strings to any tracks), and you can
check data/music.script to see how
it’s stored in the database. Or, add another loop after the track
println() in QueryTest.java to print the comments for the
track that was just displayed:
for (String comment : aTrack.getComments()) {
System.out.println(" Comment: " + comment);
}Then ant qtest will give you output like this:
... [java] Track: "Test Tone 1" 00:00:10 [java] Comment: Pink noise to test equalization
It’s nice when tools make simple things easier. In the next chapter we’ll see that more complex things are possible, too.
[2] If concepts like join tables and many-to-many associations aren’t familiar, spending some time with a good data modeling introduction would be worthwhile. It will help a lot when it comes to designing, understanding, and talking about data-driven projects. George Reese’s Java Database Best Practices (O’Reilly) has such an introduction, and you can even view the chapter online at http://www.oreilly.com/catalog/javadtabp/chapter/ch02.pdf.
[3] If you’re porting these examples to Oracle, you’ll have to
change the name of the COMMENT column,
which turns out to be a reserved word in the world of Oracle
SQL. Standards—gotta love them—there are so many to
choose from!
Get Harnessing Hibernate now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

