The action-value actor-critic algorithm still has high variance. We can reduce the variance by subtracting a baseline function, B(s), from the policy gradient. A good baseline is the state value function, 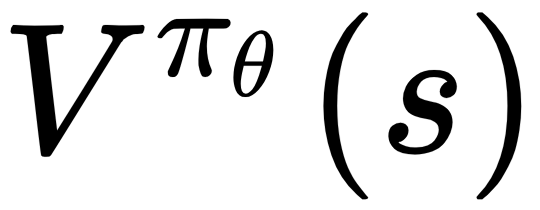 . With the state value function as the baseline, we can rewrite the result of the policy gradient theorem as the following:
. With the state value function as the baseline, we can rewrite the result of the policy gradient theorem as the following:

We can define the advantage function 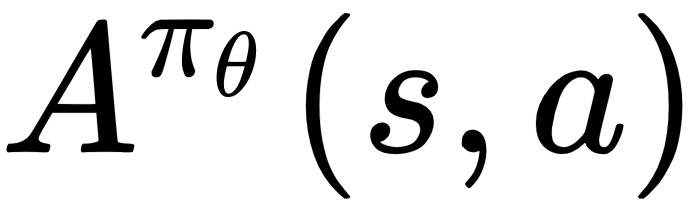 to be the following:
to be the following:
When used in the previous ...

