The policy represented by 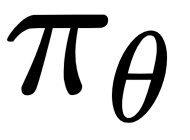 is assumed to be a differentiable function whenever it is non-zero, but computing the gradient of the policy with respect to theta,
is assumed to be a differentiable function whenever it is non-zero, but computing the gradient of the policy with respect to theta, 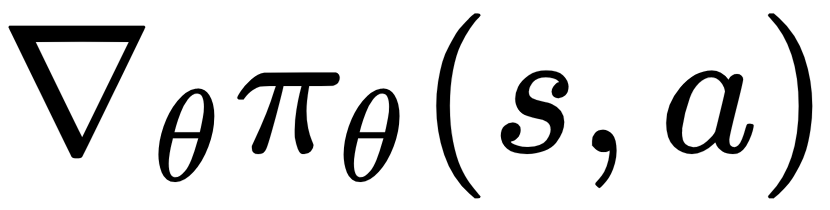 , may not be straightforward. We can multiply and divide by policy
, may not be straightforward. We can multiply and divide by policy 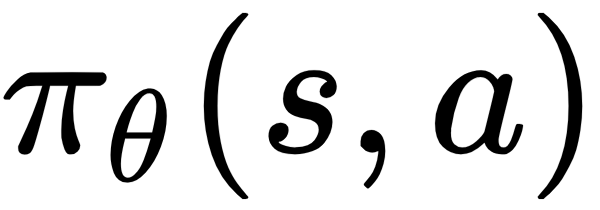 on both sides to get the following:
on both sides to get the following:

From calculus, we know that the gradient of the log of ...

