As we know, in the case of off-policy learning, the agent follows a behavioral policy that is different from the policy that the agent is trying to optimize. Just to remind you, Q-learning, which we discussed in Chapter 6, Implementing an Intelligent Agent for Optimal Discrete Control Using Deep Q-Learning, along with several extensions, is also an off-policy algorithm. Let's denote the behavior policy using 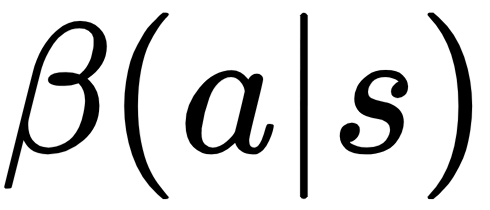 . Then, we can write the objective function of the agent to be the total advantage over the state-visitation distribution and actions given by the following:
. Then, we can write the objective function of the agent to be the total advantage over the state-visitation distribution and actions given by the following:
Here, is the policy parameters before the update and ...

