It is also very useful for an agent to learn the action value function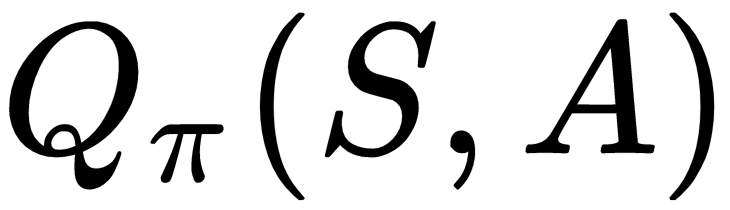 , which informs the agent about the long-term value of taking action
, which informs the agent about the long-term value of taking action  in state
in state 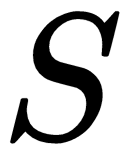 so that the agent can take those actions that will maximize its expected, discounted future reward. The SARSA and Q-learning algorithms enable an agent to learn that! The following table summarizes the update equation for the SARSA algorithm and the Q-learning algorithm:
so that the agent can take those actions that will maximize its expected, discounted future reward. The SARSA and Q-learning algorithms enable an agent to learn that! The following table summarizes the update equation for the SARSA algorithm and the Q-learning algorithm:
SARSA and Q-learning
Get Hands-On Intelligent Agents with OpenAI Gym now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

