In the last chapter, we revisited the Q-learning algorithm and implemented the Q_Learner class. For the Mountain car environment, we used a multi-dimensional array of shape 51x51x3 to represent the action-value function,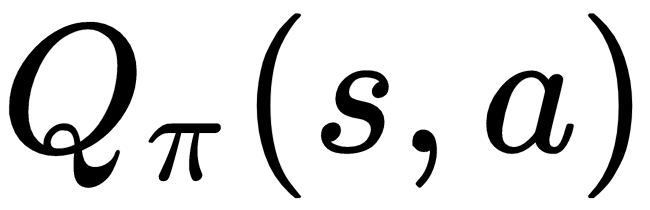 . Note that we had discretized the state space to a fixed number of bins given by the NUM_DISCRETE_BINS configuration parameter (we used 50) . We essentially quantized or approximated the observation with a low-dimensional, discrete representation to reduce the number of possible elements in the n-dimensional array. With such a discretization of the observation/state space, we restricted the possible ...
. Note that we had discretized the state space to a fixed number of bins given by the NUM_DISCRETE_BINS configuration parameter (we used 50) . We essentially quantized or approximated the observation with a low-dimensional, discrete representation to reduce the number of possible elements in the n-dimensional array. With such a discretization of the observation/state space, we restricted the possible ...
Improving the Q-learning agent
Get Hands-On Intelligent Agents with OpenAI Gym now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

