By now, you should be very familiar with DQN, as we went through the step-by-step implementation of a deep Q-learning agent in Chapter 6, Implementing an Intelligent Agent for Optimal Discrete Control Using Deep Q-Learning, where we discussed DQN in detail and how it extends standard Q-learning with a deep neural network function approximation, replay memory, and a target network. Let's recall the Q-learning loss that we used in the deep Q-learning agent in Chapter 6, Implementing an Intelligent Agent for Optimal Discrete Control Using Deep Q-Learning:
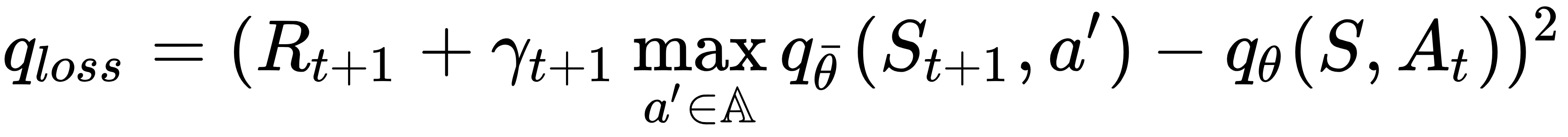
This is basically the mean squared error between the TD target and DQN's Q-estimate, ...

