If we pause for a moment and analyze what is happening, you might see that we are probably not making full use of the 5-step long trajectory. With access to the information from the agent's 5-step long trajectory starting from state  , we only ended up learning one new piece of information, which is all about
, we only ended up learning one new piece of information, which is all about 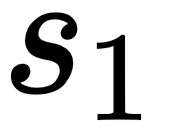 to update the actor and the critic (
to update the actor and the critic (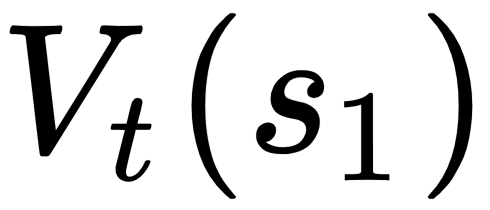 ). We can actually make the learning process more efficient ...
). We can actually make the learning process more efficient ...
Implementing the n-step return calculation
Get Hands-On Intelligent Agents with OpenAI Gym now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

