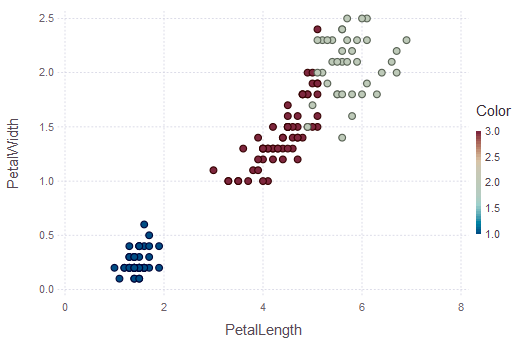
The first example uses the familiar dataset called iris again. Using the kmeans() function, the program tries to group these plants:
using Gadfly
using RDatasets
using Clustering
iris = dataset("datasets", "iris")
head(iris)
features=permutedims(convert(Array, iris[:,1:4]),[2, 1])
result=kmeans(features,3)
nameX="PetalLength"
nameY="PetalWidth"
assignments=result.assignments
plot(iris, x=nameX,y=nameY,color=assignments,Geom.point)
The related output is shown here:
For the next example, we try to sort a set of random numbers into 20 clusters. The code is shown here:
using Clustering srand(1234) nRow=5 nCol=1000 x = ...

