Hadoop comes with a set of primitives for data I/O. Some of these are techniques that are more general than Hadoop, such as data integrity and compression, but deserve special consideration when dealing with multiterabyte datasets. Others are Hadoop tools or APIs that form the building blocks for developing distributed systems, such as serialization frameworks and on-disk data structures.
Users of Hadoop rightly expect that no data will be lost or corrupted during storage or processing. However, because every I/O operation on the disk or network carries with it a small chance of introducing errors into the data that it is reading or writing, when the volumes of data flowing through the system are as large as the ones Hadoop is capable of handling, the chance of data corruption occurring is high.
The usual way of detecting corrupted data is by computing a checksum for the data when it first enters the system, and again whenever it is transmitted across a channel that is unreliable and hence capable of corrupting the data. The data is deemed to be corrupt if the newly generated checksum doesn’t exactly match the original. This technique doesn’t offer any way to fix the data—it is merely error detection. (And this is a reason for not using low-end hardware; in particular, be sure to use ECC memory.) Note that it is possible that it’s the checksum that is corrupt, not the data, but this is very unlikely, because the checksum is much smaller than the data.
A commonly used error-detecting code is CRC-32 (cyclic redundancy check), which computes a 32-bit integer checksum for input of any size.
HDFS transparently checksums all data written to it and by
default verifies checksums when reading data. A separate checksum is
created for every io.bytes.per.checksum
bytes of data. The default is 512 bytes, and because a CRC-32 checksum
is 4 bytes long, the storage overhead is less than 1%.
Datanodes are responsible for verifying the data they receive
before storing the data and its checksum. This applies to data that they
receive from clients and from other datanodes during replication. A
client writing data sends it to a pipeline of datanodes (as explained in
Chapter 3), and the last datanode in the pipeline verifies
the checksum. If it detects an error, the client receives a ChecksumException, a
subclass of IOException, which it
should handle in an application-specific manner; for example, by
retrying the operation.
When clients read data from datanodes, they verify checksums as well, comparing them with the ones stored at the datanode. Each datanode keeps a persistent log of checksum verifications, so it knows the last time each of its blocks was verified. When a client successfully verifies a block, it tells the datanode, which updates its log. Keeping statistics such as these is valuable in detecting bad disks.
Aside from block verification on client reads, each datanode runs
a DataBlockScanner in a
background thread that periodically verifies all the blocks stored on
the datanode. This is to guard against corruption due to “bit rot” in
the physical storage media. See Datanode block scanner for
details on how to access the scanner reports.
Because HDFS stores replicas of blocks, it can “heal” corrupted
blocks by copying one of the good replicas to produce a new, uncorrupt
replica. The way this works is that if a client detects an error when
reading a block, it reports the bad block and the datanode it was trying
to read from to the namenode before throwing a ChecksumException. The
namenode marks the block replica as corrupt so it doesn’t direct clients
to it or try to copy this replica to another datanode. It then schedules
a copy of the block to be replicated on another datanode, so its
replication factor is back at the expected level. Once this has
happened, the corrupt replica is deleted.
It is possible to disable verification of checksums by passing
false to the setVerifyChecksum()
method on FileSystem before using the
open() method to read a
file. The same effect is possible from the shell by using the -ignoreCrc option with
the -get or the equivalent -copyToLocal command.
This feature is useful if you have a corrupt file that you want to
inspect so you can decide what to do with it. For example, you might
want to see whether it can be salvaged before you delete it.
The Hadoop LocalFileSystem
performs client-side checksumming. This means that when you write a file
called filename, the filesystem
client transparently creates a hidden file, .filename.crc, in the same directory
containing the checksums for each chunk of the file. Like HDFS, the
chunk size is controlled by the io.bytes.per.checksum
property, which defaults to 512 bytes. The chunk size is stored as
metadata in the .crc file, so the
file can be read back correctly even if the setting for the chunk size
has changed. Checksums are verified when the file is read, and if an
error is detected, LocalFileSystem throws a ChecksumException.
Checksums are fairly cheap to compute (in Java, they are
implemented in native code), typically adding a few percent overhead to
the time to read or write a file.For
most applications, this is an acceptable price to pay for data
integrity. It is, however, possible to disable checksums, typically when
the underlying filesystem supports checksums natively. This is
accomplished by using RawLocalFileSystem in
place of LocalFileSystem.
To do this globally in an application, it suffices to remap the
implementation for file URIs by
setting the property fs.file.impl to
the value org.apache.hadoop.fs.RawLocalFileSystem.
Alternatively, you can directly create a RawLocalFileSystem
instance, which may be useful if you want to disable checksum
verification for only some reads, for example:
Configuration conf = ... FileSystem fs = new RawLocalFileSystem(); fs.initialize(null, conf);
LocalFileSystem uses
ChecksumFileSystem to
do its work, and this class makes it easy to add checksumming to other
(nonchecksummed) filesystems, as ChecksumFileSystem
is just a wrapper around FileSystem.
The general idiom is as follows:
FileSystem rawFs = ... FileSystem checksummedFs = new ChecksumFileSystem(rawFs);
The underlying filesystem is called the raw
filesystem, and may be retrieved using the getRawFileSystem()
method on ChecksumFileSystem.
ChecksumFileSystem has
a few more useful methods for working with checksums, such as getChecksumFile() for
getting the path of a checksum file for any file. Check the
documentation for the others.
If an error is detected by ChecksumFileSystem when
reading a file, it will call its reportChecksumFailure() method. The
default implementation does nothing, but LocalFileSystem moves
the offending file and its checksum to a side directory on the same
device called bad_files.
Administrators should periodically check for these bad files and take
action on them.
File compression brings two major benefits: it reduces the space needed to store files, and it speeds up data transfer across the network or to or from disk. When dealing with large volumes of data, both of these savings can be significant, so it pays to carefully consider how to use compression in Hadoop.
There are many different compression formats, tools and algorithms, each with different characteristics. Table 4-1 lists some of the more common ones that can be used with Hadoop.
Table 4-1. A summary of compression formats
| Compression format | Tool | Algorithm | Filename extension | Splittable? |
|---|---|---|---|---|
| DEFLATE[a] | N/A | DEFLATE | .deflate | No |
| gzip | gzip | DEFLATE | .gz | No |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | No[b] |
| LZ4 | N/A | LZ4 | .lz4 | No |
| Snappy | N/A | Snappy | .snappy | No |
[a] DEFLATE is a compression algorithm whose standard implementation is zlib. There is no commonly available command-line tool for producing files in DEFLATE format, as gzip is normally used. (Note that the gzip file format is DEFLATE with extra headers and a footer.) The .deflate filename extension is a Hadoop convention. [b] However, LZO files are splittable if they have been indexed in a preprocessing step. See page in Compression and Input Splits. | ||||
All compression algorithms exhibit a space/time trade-off: faster
compression and decompression speeds usually come at the expense of
smaller space savings. The tools listed in Table 4-1 typically give some control over this
trade-off at compression time by offering nine different options: –1 means optimize for speed, and -9 means optimize for space. For example, the
following command creates a compressed file file.gz using the fastest compression
method:
gzip -1 file
The different tools have very different compression characteristics. Gzip is a general-purpose compressor and sits in the middle of the space/time trade-off. Bzip2 compresses more effectively than gzip, but is slower. Bzip2’s decompression speed is faster than its compression speed, but it is still slower than the other formats. LZO, LZ4. and Snappy, on the other hand, all optimize for speed and are around an order of magnitude faster than gzip, but compress less effectively. Snappy and LZ4 are also significantly faster than LZO for decompression.[34]
The “Splittable” column in Table 4-1 indicates whether the compression format supports splitting, that is, whether you can seek to any point in the stream and start reading from some point further on. Splittable compression formats are especially suitable for MapReduce; see Compression and Input Splits for further discussion.
A codec is the implementation of a
compression-decompression algorithm. In Hadoop, a codec is represented
by an implementation of the CompressionCodec
interface. So, for example, GzipCodec encapsulates
the compression and decompression algorithm for gzip. Table 4-2 lists the codecs that are available for
Hadoop.
Table 4-2. Hadoop compression codecs
| Compression format | Hadoop CompressionCodec |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
The LZO libraries are GPL-licensed and may not be included in
Apache distributions, so for this reason the Hadoop codecs must be
downloaded separately from http://code.google.com/p/hadoop-gpl-compression/ (or
http://github.com/kevinweil/hadoop-lzo, which
includes bug fixes and more tools). The LzopCodec is compatible
with the lzop tool, which is
essentially the LZO format with extra headers, and is the one you
normally want. There is also a LzoCodec for the pure
LZO format, which uses the .lzo_deflate filename extension (by analogy
with DEFLATE, which is gzip without the headers).
CompressionCodec has
two methods that allow you to easily compress or decompress data. To
compress data being written to an output stream, use the createOutputStream(OutputStream out) method
to create a CompressionOutputStream to which you write
your uncompressed data to have it written in compressed form to the
underlying stream. Conversely, to decompress data being read from an
input stream, call createInputStream(InputStream in) to
obtain a CompressionInputStream, which allows you to
read uncompressed data from the underlying stream.
CompressionOutputStream and CompressionInputStream are similar to
java.util.zip.DeflaterOutputStream and java.util.zip.DeflaterInputStream,
except that both of the former provide the ability to reset their
underlying compressor or decompressor, which is important for
applications that compress sections of the data stream as separate
blocks, such as SequenceFile,
described in SequenceFile.
Example 4-1 illustrates how to use the API to compress data read from standard input and write it to standard output.
Example 4-1. A program to compress data read from standard input and write it to standard output
public class StreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)
ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
}
}The application expects the fully qualified name of the
CompressionCodec
implementation as the first command-line argument. We use ReflectionUtils to
construct a new instance of the codec, then obtain a compression
wrapper around System.out. Then we
call the utility method copyBytes() on
IOUtils to copy the
input to the output, which is compressed by the CompressionOutputStream. Finally, we call
finish() on CompressionOutputStream, which tells
the compressor to finish writing to the compressed stream, but doesn’t
close the stream. We can try it out with the following command line,
which compresses the string “Text” using the StreamCompressor
program with the GzipCodec, then
decompresses it from standard input using gunzip:
%echo "Text" | hadoop StreamCompressor org.apache.hadoop.io.compress.GzipCodec \| gunzip -Text
If you are reading a compressed file, normally you can
infer which codec to use by looking at its filename extension. A file
ending in .gz can be read with
GzipCodec, and so on.
The extension for each compression format is listed in Table 4-1.
CompressionCodecFactory provides a way of
mapping a filename extension to a CompressionCodec using its getCodec() method,
which takes a Path object for the
file in question. Example 4-2 shows an
application that uses this feature to decompress files.
Example 4-2. A program to decompress a compressed file using a codec inferred from the file’s extension
public class FileDecompressor {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputUri =
CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}Once the codec has been found, it is used to strip off the file
suffix to form the output filename (via the removeSuffix() static
method of CompressionCodecFactory).
In this way, a file named file.gz
is decompressed to file by
invoking the program as follows:
% hadoop FileDecompressor file.gzCompressionCodecFactory finds codecs from a
list defined by the io.compression.codecs configuration
property. By default, this lists all the codecs provided by Hadoop
(see Table 4-3), so you would need
to alter it only if you have a custom codec that you wish to register
(such as the externally hosted LZO codecs). Each codec knows its
default filename extension, thus permitting CompressionCodecFactory to search through
the registered codecs to find a match for a given extension (if
any).
Table 4-3. Compression codec properties
| Property name | Type | Default value | Description |
|---|---|---|---|
io.compression.codecs | Comma-separated
Class names | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec | A list of the CompressionCodec classes
for compression/decompression |
For performance, it is preferable to use a native library for compression and decompression. For example, in one test, using the native gzip libraries reduced decompression times by up to 50% and compression times by around 10% (compared to the built-in Java implementation). Table 4-4 shows the availability of Java and native implementations for each compression format. Not all formats have native implementations (bzip2, for example), whereas others are available only as a native implementation (LZO, for example).
Table 4-4. Compression library implementations
| Compression format | Java implementation? | Native implementation? |
|---|---|---|
| DEFLATE | Yes | Yes |
| gzip | Yes | Yes |
| bzip2 | Yes | No |
| LZO | No | Yes |
| LZ4 | No | Yes |
| Snappy | No | Yes |
Hadoop comes with prebuilt native compression libraries for 32- and 64-bit Linux, which you can find in the lib/native directory. For other platforms, you will need to compile the libraries yourself, following the instructions on the Hadoop wiki at http://wiki.apache.org/hadoop/NativeHadoop.
The native libraries are picked up using the Java system
property java.library.path.
The hadoop script in the
bin directory sets this property
for you, but if you don’t use this script, you will need to set the
property in your application.
By default, Hadoop looks for native libraries for the platform
it is running on, and loads them automatically if they are found. This
means you don’t have to change any configuration settings to use the
native libraries. In some circumstances, however, you may wish to
disable use of native libraries, such as when you are debugging a
compression-related problem. You can achieve this by setting the
property hadoop.native.lib to
false, which ensures that the
built-in Java equivalents will be used (if they are available).
If you are using a native library and you are doing a
lot of compression or decompression in your application, consider
using CodecPool, which
allows you to reuse compressors and decompressors, thereby
amortizing the cost of creating these objects.
The code in Example 4-3 shows
the API, although in this program, which creates only a single
Compressor, there is really no
need to use a pool.
Example 4-3. A program to compress data read from standard input and write it to standard output using a pooled compressor
public class PooledStreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)
ReflectionUtils.newInstance(codecClass, conf);
Compressor compressor = null;
try {
compressor = CodecPool.getCompressor(codec);
CompressionOutputStream out =
codec.createOutputStream(System.out, compressor);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
} finally {
CodecPool.returnCompressor(compressor);
}
}
}We retrieve a Compressor
instance from the pool for a given CompressionCodec,
which we use in the codec’s overloaded createOutputStream() method.
By using a finally block, we
ensure that the compressor is returned to the pool even if there is
an IOException while copying the bytes
between the streams.
When considering how to compress data that will be processed by MapReduce, it is important to understand whether the compression format supports splitting. Consider an uncompressed file stored in HDFS whose size is 1 GB. With an HDFS block size of 64 MB, the file will be stored as 16 blocks, and a MapReduce job using this file as input will create 16 input splits, each processed independently as input to a separate map task.
Imagine now that the file is a gzip-compressed file whose compressed size is 1 GB. As before, HDFS will store the file as 16 blocks. However, creating a split for each block won’t work, because it is impossible to start reading at an arbitrary point in the gzip stream and therefore impossible for a map task to read its split independently of the others. The gzip format uses DEFLATE to store the compressed data, and DEFLATE stores data as a series of compressed blocks. The problem is that the start of each block is not distinguished in any way that would allow a reader positioned at an arbitrary point in the stream to advance to the beginning of the next block, thereby synchronizing itself with the stream. For this reason, gzip does not support splitting.
In this case, MapReduce will do the right thing and not try to split the gzipped file, since it knows that the input is gzip-compressed (by looking at the filename extension) and that gzip does not support splitting. This will work, but at the expense of locality: a single map will process the 16 HDFS blocks, most of which will not be local to the map. Also, with fewer maps, the job is less granular and so may take longer to run.
If the file in our hypothetical example were an LZO file, we would have the same problem because the underlying compression format does not provide a way for a reader to synchronize itself with the stream. However, it is possible to preprocess LZO files using an indexer tool that comes with the Hadoop LZO libraries, which you can obtain from the sites listed in Codecs. The tool builds an index of split points, effectively making them splittable when the appropriate MapReduce input format is used.
A bzip2 file, on the other hand, does provide a synchronization marker between blocks (a 48-bit approximation of pi), so it does support splitting. (Table 4-1 lists whether each compression format supports splitting.)
As described in Inferring CompressionCodecs using CompressionCodecFactory, if your input files are compressed, they will be decompressed automatically as they are read by MapReduce, using the filename extension to determine which codec to use.
To compress the output of a MapReduce job, in the job
configuration, set the mapred.output.compress
property to true and the mapred.output.compression.codec property to
the classname of the compression codec you want to use. Alternatively,
you can use the static convenience methods on FileOutputFormat to set
these properties as shown in Example 4-4.
Example 4-4. Application to run the maximum temperature job producing compressed output
public class MaxTemperatureWithCompression {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCompression <input path> " +
"<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}We run the program over compressed input (which doesn’t have to use the same compression format as the output, although it does in this example) as follows:
% hadoop MaxTemperatureWithCompression input/ncdc/sample.txt.gz outputEach part of the final output is compressed; in this case, there is a single part:
% gunzip -c output/part-r-00000.gz
1949 111
1950 22If you are emitting sequence files for your output, you can set
the mapred.output.compression.type
property to control the type of compression to use. The default is
RECORD, which compresses individual
records. Changing this to BLOCK,
which compresses groups of
records, is recommended because it compresses better (see The SequenceFile format).
There is also a static convenience method on SequenceFileOutputFormat called setOutputCompressionType() to set this
property.
The configuration properties to set compression for MapReduce job
outputs are summarized in Table 4-5. If your MapReduce driver
uses the Tool interface (described in
GenericOptionsParser, Tool, and ToolRunner), you can pass
any of these properties to the program on the command line, which may be
more convenient than modifying your program to hardcode the compression
properties.
Table 4-5. MapReduce compression properties
| Property name | Type | Default value | Description |
|---|---|---|---|
mapred.output.compress | boolean | false | Compress outputs |
mapred.output.compression.codec | Class name | org.apache.hadoop.io.compress.DefaultCodec | The compression codec to use for outputs |
mapred.output.compression.type | String | RECORD | The type of compression to use for SequenceFile outputs:
NONE, RECORD, or BLOCK |
Even if your MapReduce application reads and writes uncompressed data, it may benefit from compressing the intermediate output of the map phase. Since the map output is written to disk and transferred across the network to the reducer nodes, by using a fast compressor such as LZO, LZ4, or Snappy, you can get performance gains simply because the volume of data to transfer is reduced. The configuration properties to enable compression for map outputs and to set the compression format are shown in Table 4-6.
Table 4-6. Map output compression properties
| Property name | Type | Default value | Description |
|---|---|---|---|
mapred.compress.map.
output | boolean | false | Compress map outputs |
mapred.map.output.compression.codec | Class | org.apache.hadoop.io.compress.DefaultCodec | The compression codec to use for map outputs |
Here are the lines to add to enable gzip map output compression in your job (using the new API):
Configuration conf = new Configuration();
conf.setBoolean("mapred.compress.map.output", true);
conf.setClass("mapred.map.output.compression.codec", GzipCodec.class,
CompressionCodec.class);
Job job = new Job(conf);In the old API, there are convenience methods on the JobConf object for
doing the same thing:
conf.setCompressMapOutput(true);
conf.setMapOutputCompressorClass(GzipCodec.class);Serialization is the process of turning structured objects into a byte stream for transmission over a network or for writing to persistent storage. Deserialization is the reverse process of turning a byte stream back into a series of structured objects.
Serialization appears in two quite distinct areas of distributed data processing: for interprocess communication and for persistent storage.
In Hadoop, interprocess communication between nodes in the system is implemented using remote procedure calls (RPCs). The RPC protocol uses serialization to render the message into a binary stream to be sent to the remote node, which then deserializes the binary stream into the original message. In general, it is desirable that an RPC serialization format is:
- Compact
A compact format makes the best use of network bandwidth, which is the most scarce resource in a data center.
- Fast
Interprocess communication forms the backbone for a distributed system, so it is essential that there is as little performance overhead as possible for the serialization and deserialization process.
- Extensible
Protocols change over time to meet new requirements, so it should be straightforward to evolve the protocol in a controlled manner for clients and servers. For example, it should be possible to add a new argument to a method call and have the new servers accept messages in the old format (without the new argument) from old clients.
- Interoperable
For some systems, it is desirable to be able to support clients that are written in different languages to the server, so the format needs to be designed to make this possible.
On the face of it, the data format chosen for persistent storage would have different requirements from a serialization framework. After all, the lifespan of an RPC is less than a second, whereas persistent data may be read years after it was written. As it turns out, the four desirable properties of an RPC’s serialization format are also crucial for a persistent storage format. We want the storage format to be compact (to make efficient use of storage space), fast (so the overhead in reading or writing terabytes of data is minimal), extensible (so we can transparently read data written in an older format), and interoperable (so we can read or write persistent data using different languages).
Hadoop uses its own serialization format, Writables, which is certainly compact and fast, but not so easy to extend or use from languages other than Java. Because Writables are central to Hadoop (most MapReduce programs use them for their key and value types), we look at them in some depth in the next three sections, before looking at serialization frameworks in general and then Avro (a serialization system that was designed to overcome some of the limitations of Writables) in more detail.
The Writable interface defines two methods: one for
writing its state to a DataOutput binary
stream and one for reading its state from a DataInput binary
stream.
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}Let’s look at a particular Writable to see what we can do with it. We
will use IntWritable, a wrapper for a Java
int. We can create one and set its
value using the set() method:
IntWritable writable = new IntWritable();
writable.set(163);Equivalently, we can use the constructor that takes the integer value:
IntWritable writable = new IntWritable(163);
To examine the serialized form of the IntWritable, we write a
small helper method that wraps a java.io.ByteArrayOutputStream in a java.io.DataOutputStream (an implementation of
java.io.DataOutput) to capture the
bytes in the serialized stream:
public static byte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}An integer is written using four bytes (as we see using JUnit 4 assertions):
byte[] bytes = serialize(writable);
assertThat(bytes.length, is(4));The bytes are written in big-endian order (so the most significant
byte is written to the stream first, which is dictated by the java.io.DataOutput
interface), and we can see their hexadecimal representation by using a
method on Hadoop’s StringUtils:
assertThat(StringUtils.byteToHexString(bytes), is("000000a3"));Let’s try deserialization. Again, we create a helper method to
read a Writable object from a
byte array:
public static byte[] deserialize(Writable writable, byte[] bytes)
throws IOException {
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
DataInputStream dataIn = new DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return bytes;
}We construct a new, value-less IntWritable, and then
call deserialize() to read
from the output data that we just wrote. Then we check that its value,
retrieved using the get() method, is the
original value, 163:
IntWritable newWritable = new IntWritable();
deserialize(newWritable, bytes);
assertThat(newWritable.get(), is(163));IntWritable
implements the WritableComparable
interface, which is just a subinterface of the Writable and java.lang.Comparable
interfaces:
package org.apache.hadoop.io;
public interface WritableComparable<T> extends Writable, Comparable<T> {
}Comparison of types is crucial for MapReduce, where there is a
sorting phase during which keys are compared with one another. One
optimization that Hadoop provides is the RawComparator
extension of Java’s Comparator:
package org.apache.hadoop.io;
import java.util.Comparator;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}This interface permits implementors to compare records read from
a stream without deserializing them into objects, thereby avoiding any
overhead of object creation. For example, the comparator for IntWritables implements the raw compare() method by
reading an integer from each of the byte arrays b1 and b2
and comparing them directly from the given start positions (s1 and s2) and lengths (l1 and l2).
WritableComparator is
a general-purpose implementation of RawComparator for
WritableComparable classes. It provides
two main functions. First, it provides a default implementation of the
raw compare() method that
deserializes the objects to be compared from the stream and invokes
the object compare() method.
Second, it acts as a factory for RawComparator
instances (that Writable
implementations have registered). For example, to obtain a comparator
for IntWritable, we just
use:
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
The comparator can be used to compare two IntWritable
objects:
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67);
assertThat(comparator.compare(w1, w2), greaterThan(0));or their serialized representations:
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1, 0, b1.length, b2, 0, b2.length),
greaterThan(0));Hadoop comes with a large selection of Writable classes in the org.apache.hadoop.io
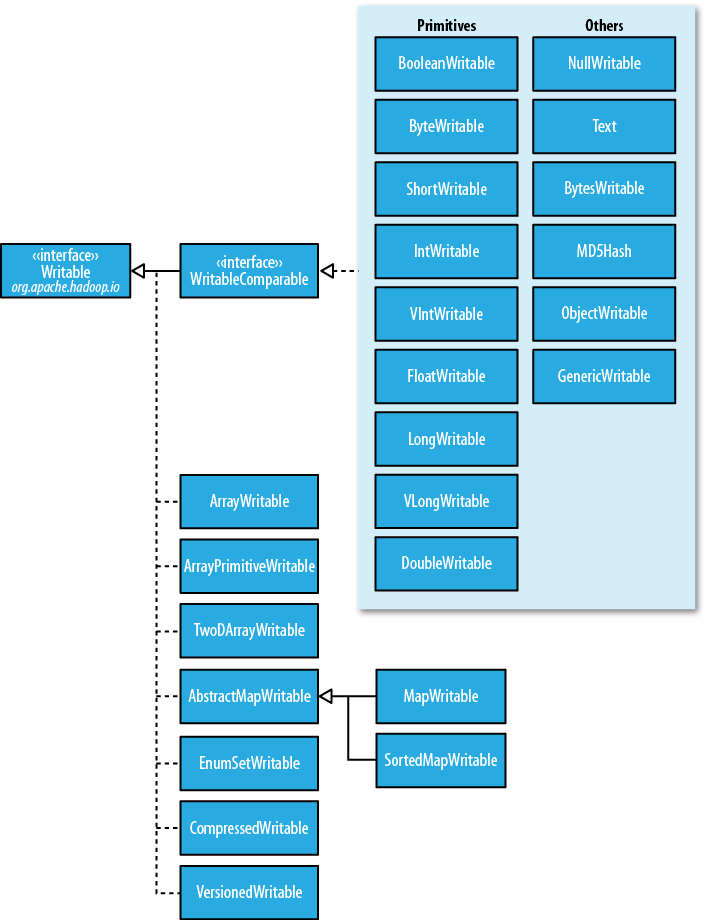
package. They form the class hierarchy shown in Figure 4-1.
There are Writable
wrappers for all the Java primitive types (see Table 4-7) except char (which can be
stored in an IntWritable). All have
a get() and set() method for
retrieving and storing the wrapped value.
Table 4-7. Writable wrapper classes for Java primitives
| Java primitive | Writable implementation | Serialized size (bytes) |
|---|---|---|
boolean | BooleanWritable | 1 |
byte | ByteWritable | 1 |
short | ShortWritable | 2 |
int | IntWritable | 4 |
VIntWritable | 1–5 | |
float | FloatWritable | 4 |
long | LongWritable | 8 |
VLongWritable | 1–9 | |
double | DoubleWritable | 8 |
When it comes to encoding integers, there is a choice
between the fixed-length formats (IntWritable and
LongWritable) and the
variable-length formats (VIntWritable and
VLongWritable). The variable-length
formats use only a single byte to encode the value if it is small
enough (between –112 and 127, inclusive); otherwise, they use the
first byte to indicate whether the value is positive or negative, and
how many bytes follow. For example, 163 requires two bytes:
byte[] data = serialize(new VIntWritable(163));
assertThat(StringUtils.byteToHexString(data), is("8fa3"));How do you choose between a fixed-length and a variable-length
encoding? Fixed-length encodings are good when the distribution of
values is fairly uniform across the whole value space, such as a
(well-designed) hash function. Most numeric variables tend to have
nonuniform distributions, and on average the variable-length encoding
will save space. Another advantage of variable-length encodings is
that you can switch from VIntWritable to
VLongWritable,
because their encodings are actually the same. So by choosing a
variable-length representation, you have room to grow without
committing to an 8-byte long
representation from the beginning.
Text is a Writable for UTF-8 sequences. It can be
thought of as the Writable
equivalent of java.lang.String.
Text is a replacement for the
UTF8 class, which was deprecated
because it didn’t support strings whose encoding was over 32,767 bytes
and because it used Java’s modified UTF-8.
The Text class uses an
int (with a variable-length
encoding) to store the number of bytes in the string encoding, so the
maximum value is 2 GB. Furthermore, Text uses standard UTF-8, which makes it
potentially easier to interoperate with other tools that understand
UTF-8.
Because of its emphasis on using standard UTF-8, there
are some differences between Text
and the Java String class.
Indexing for the Text class is in
terms of position in the encoded byte sequence, not the Unicode
character in the string or the Java char code unit (as
it is for String). For ASCII
strings, these three concepts of index position coincide. Here is an
example to demonstrate the use of the charAt()
method:
Text t = new Text("hadoop");
assertThat(t.getLength(), is(6));
assertThat(t.getBytes().length, is(6));
assertThat(t.charAt(2), is((int) 'd'));
assertThat("Out of bounds", t.charAt(100), is(-1));Notice that charAt() returns an
int representing a Unicode code
point, unlike the String variant
that returns a char. Text also has a find() method,
which is analogous to String’s
indexOf():
Text t = new Text("hadoop");
assertThat("Find a substring", t.find("do"), is(2));
assertThat("Finds first 'o'", t.find("o"), is(3));
assertThat("Finds 'o' from position 4 or later", t.find("o", 4), is(4));
assertThat("No match", t.find("pig"), is(-1));When we start using characters that are encoded with
more than a single byte, the differences between Text and String become clear. Consider the Unicode
characters shown in Table 4-8.[35]
Table 4-8. Unicode characters
| Unicode code point | U+0041 | U+00DF | U+6771 | U+10400 |
| Name | LATIN CAPITAL LETTER A | LATIN SMALL LETTER SHARP S | N/A (a unified Han ideograph) | DESERET CAPITAL LETTER LONG I |
| UTF-8 code units | 41 | c3 9f | e6 9d b1 | f0 90 90 80 |
| Java representation | \u0041 | \u00DF | \u6771 | \uuD801\uDC00 |
All but the last character in the table, U+10400, can be
expressed using a single Java char. U+10400 is a
supplementary character and is represented by two Java chars, known as a surrogate pair. The
tests in Example 4-5 show the
differences between String and
Text when processing a string of
the four characters from Table 4-8.
Example 4-5. Tests showing the differences between the String and Text classes
public class StringTextComparisonTest {
@Test
public void string() throws UnsupportedEncodingException {
String s = "\u0041\u00DF\u6771\uD801\uDC00";
assertThat(s.length(), is(5));
assertThat(s.getBytes("UTF-8").length, is(10));
assertThat(s.indexOf("\u0041"), is(0));
assertThat(s.indexOf("\u00DF"), is(1));
assertThat(s.indexOf("\u6771"), is(2));
assertThat(s.indexOf("\uD801\uDC00"), is(3));
assertThat(s.charAt(0), is('\u0041'));
assertThat(s.charAt(1), is('\u00DF'));
assertThat(s.charAt(2), is('\u6771'));
assertThat(s.charAt(3), is('\uD801'));
assertThat(s.charAt(4), is('\uDC00'));
assertThat(s.codePointAt(0), is(0x0041));
assertThat(s.codePointAt(1), is(0x00DF));
assertThat(s.codePointAt(2), is(0x6771));
assertThat(s.codePointAt(3), is(0x10400));
}
@Test
public void text() {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
assertThat(t.getLength(), is(10));
assertThat(t.find("\u0041"), is(0));
assertThat(t.find("\u00DF"), is(1));
assertThat(t.find("\u6771"), is(3));
assertThat(t.find("\uD801\uDC00"), is(6));
assertThat(t.charAt(0), is(0x0041));
assertThat(t.charAt(1), is(0x00DF));
assertThat(t.charAt(3), is(0x6771));
assertThat(t.charAt(6), is(0x10400));
}
}The test confirms that the length of a String is the number of char code units it
contains (5, made up of one from each of the first three characters
in the string and a surrogate pair from the last), whereas the
length of a Text object is the
number of bytes in its UTF-8 encoding (10 = 1+2+3+4). Similarly, the
indexOf() method in
String returns an index in
char code units,
and find() for Text is a byte offset.
The charAt() method in
String returns the char code unit for
the given index, which in the case of a surrogate pair will not
represent a whole Unicode character. The codePointAt()
method, indexed by char code unit, is
needed to retrieve a single Unicode character represented as an
int. In fact, the charAt() method in
Text is more like the codePointAt()
method than its namesake in String. The only difference is that it is
indexed by byte offset.
Iterating over the Unicode characters in Text is complicated by the use of byte
offsets for indexing, since you can’t just increment the index. The
idiom for iteration is a little obscure (see Example 4-6): turn the Text object into a
java.nio.ByteBuffer, then
repeatedly call the bytesToCodePoint()
static method on Text with the
buffer. This method extracts the next code point as an int and updates the position in the
buffer. The end of the string is detected when bytesToCodePoint()
returns –1.
Example 4-6. Iterating over the characters in a Text object
public class TextIterator {
public static void main(String[] args) {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
ByteBuffer buf = ByteBuffer.wrap(t.getBytes(), 0, t.getLength());
int cp;
while (buf.hasRemaining() && (cp = Text.bytesToCodePoint(buf)) != -1) {
System.out.println(Integer.toHexString(cp));
}
}
}Running the program prints the code points for the four characters in the string:
% hadoop TextIterator
41
df
6771
10400Another difference with String is that Text is mutable (like all Writable
implementations in Hadoop, except NullWritable, which
is a singleton). You can reuse a Text instance by calling one of the
set() methods on
it. For example:
Text t = new Text("hadoop");
t.set("pig");
assertThat(t.getLength(), is(3));
assertThat(t.getBytes().length, is(3));Warning
In some situations, the byte array returned by the
getBytes() method
may be longer than the length returned by getLength():
Text t = new Text("hadoop");
t.set(new Text("pig"));
assertThat(t.getLength(), is(3));
assertThat("Byte length not shortened", t.getBytes().length,
is(6));This shows why it is imperative that you always call
getLength() when
calling getBytes(), so
you know how much of the byte array is valid data.
BytesWritable is a
wrapper for an array of binary data. Its serialized format is an
integer field (4 bytes) that specifies the number of bytes to follow,
followed by the bytes themselves. For example, the byte array of
length two with values 3 and 5 is serialized as a 4-byte integer
(00000002) followed by the two
bytes from the array (03 and
05):
BytesWritable b = new BytesWritable(new byte[] { 3, 5 });
byte[] bytes = serialize(b);
assertThat(StringUtils.byteToHexString(bytes), is("000000020305"));BytesWritable is
mutable, and its value may be changed by calling its set() method. As with
Text, the size of the byte array
returned from the getBytes() method for
BytesWritable—the capacity—may not
reflect the actual size of the data stored in the BytesWritable. You
can determine the size of the BytesWritable by
calling getLength(). To
demonstrate:
b.setCapacity(11);
assertThat(b.getLength(), is(2));
assertThat(b.getBytes().length, is(11));NullWritable is a
special type of Writable, as it has
a zero-length serialization. No bytes are written to or read from the
stream. It is used as a placeholder; for example, in MapReduce, a key
or a value can be declared as a NullWritable when you
don’t need to use that position, effectively storing a constant empty
value. NullWritable can also
be useful as a key in SequenceFile
when you want to store a list of values, as opposed to key-value
pairs. It is an immutable singleton, and the instance can be retrieved
by calling NullWritable.get().
ObjectWritable is a
general-purpose wrapper for the following: Java primitives, String, enum, Writable, null, or arrays of any of these types. It is
used in Hadoop RPC to marshal and unmarshal method arguments and
return types.
ObjectWritable is
useful when a field can be of more than one type. For example, if the
values in a SequenceFile have
multiple types, you can declare the value type as an ObjectWritable and
wrap each type in an ObjectWritable. Being
a general-purpose mechanism, it wasted a fair amount of space because
it writes the classname of the wrapped type every time it is
serialized. In cases where the number of types is small and known
ahead of time, this can be improved by having a static array of types
and using the index into the array as the serialized reference to the
type. This is the approach that GenericWritable
takes, and you have to subclass it to specify which types to
support.
There are six Writable collection types in the org.apache.hadoop.io
package: ArrayWritable,
ArrayPrimitiveWritable, TwoDArrayWritable,
MapWritable,
SortedMapWritable, and EnumSetWritable.
ArrayWritable and
TwoDArrayWritable are
Writable implementations for arrays
and two-dimensional arrays (array of arrays) of Writable instances. All the elements of an
ArrayWritable or a
TwoDArrayWritable must be instances of the
same class, which is specified at construction as follows:
ArrayWritable writable = new ArrayWritable(Text.class);
In contexts where the Writable is defined by type, such as in
SequenceFile keys or values or as
input to MapReduce in general, you need to subclass ArrayWritable (or
TwoDArrayWritable, as
appropriate) to set the type statically. For example:
public class TextArrayWritable extends ArrayWritable {
public TextArrayWritable() {
super(Text.class);
}
}ArrayWritable and
TwoDArrayWritable
both have get() and set() methods, as
well as a toArray() method,
which creates a shallow copy of the array (or 2D array).
ArrayPrimitiveWritable is a wrapper for
arrays of Java primitives. The component type is detected when you
call set(), so there is no
need to subclass to set the type.
MapWritable and
SortedMapWritable are
implementations of java.util.Map<Writable,
Writable> and java.util.SortedMap<WritableComparable,
Writable>, respectively. The type of each key and value
field is a part of the serialization format for that field. The type
is stored as a single byte that acts as an index into an array of
types. The array is populated with the standard types in the
org.apache.hadoop.io
package, but custom Writable types are
accommodated, too, by writing a header that encodes the type array for
nonstandard types. As they are implemented, MapWritable and
SortedMapWritable use
positive byte values for custom
types, so a maximum of 127 distinct nonstandard Writable classes can be used in any
particular MapWritable or
SortedMapWritable
instance. Here’s a demonstration of using a MapWritable with
different types for keys and values:
MapWritable src = new MapWritable();
src.put(new IntWritable(1), new Text("cat"));
src.put(new VIntWritable(2), new LongWritable(163));
MapWritable dest = new MapWritable();
WritableUtils.cloneInto(dest, src);
assertThat((Text) dest.get(new IntWritable(1)), is(new Text("cat")));
assertThat((LongWritable) dest.get(new VIntWritable(2)), is(new
LongWritable(163)));Conspicuous by their absence are Writable collection implementations for sets
and lists. A general set can be emulated by using a MapWritable (or a
SortedMapWritable for
a sorted set) with NullWritable values.
There is also EnumSetWritable for
sets of enum types. For lists of a single type of Writable, ArrayWritable is
adequate, but to store different types of Writable in a single list, you can use
GenericWritable to wrap the elements in
an ArrayWritable.
Alternatively, you could write a general ListWritable using
the ideas from MapWritable.
Hadoop comes with a useful set of Writable implementations that serve most
purposes; however, on occasion, you may need to write your own custom
implementation. With a custom Writable, you have full control over the
binary representation and the sort order. Because Writables are at the
heart of the MapReduce data path, tuning the binary representation can
have a significant effect on performance. The stock Writable implementations that come with Hadoop are
well-tuned, but for more elaborate structures, it is often better to
create a new Writable type rather
than compose the stock types.
To demonstrate how to create a custom Writable, we shall write an implementation
that represents a pair of strings, called TextPair. The basic
implementation is shown in Example 4-7.
Example 4-7. A Writable implementation that stores a pair of Text objects
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}The first part of the implementation is straightforward: there are
two Text instance variables, first and second, and associated constructors, getters,
and setters. All Writable implementations must have a
default constructor so that the MapReduce framework can instantiate
them, then populate their fields by calling readFields(). Writable instances
are mutable and often reused, so you should take care to avoid
allocating objects in the write() or readFields() methods.
TextPair’s write() method serializes each
Text object in turn to
the output stream by delegating to the Text objects themselves. Similarly, readFields() deserializes the
bytes from the input stream by delegating to each Text object. The
DataOutput and
DataInput interfaces have a rich set of methods
for serializing and deserializing Java primitives, so, in general, you
have complete control over the wire format of your Writable object.
Just as you would for any value object you write in Java, you
should override the hashCode(), equals(), and toString() methods from
java.lang.Object. The
hashCode() method is used by the
HashPartitioner (the
default partitioner in MapReduce) to choose a reduce partition, so you
should make sure that you write a good hash function that mixes well to
ensure reduce partitions are of a similar size.
Warning
If you ever plan to use your custom Writable with TextOutputFormat,
then you must implement its toString() method. TextOutputFormat
calls toString() on keys and values
for their output representation. For TextPair, we write
the underlying Text objects as
strings separated by a tab character.
TextPair is an
implementation of WritableComparable, so
it provides an implementation of the compareTo() method that imposes
the ordering you would expect: it sorts by the first string followed by
the second. Notice that TextPair differs from
TextArrayWritable from
the previous section (apart from the number of Text objects it can store), since TextArrayWritable is
only a Writable, not a WritableComparable.
The code for TextPair in Example 4-7 will work as it stands; however, there is a
further optimization we can make. As explained in WritableComparable and comparators, when TextPair is being
used as a key in MapReduce, it will have to be deserialized into an
object for the compareTo() method to be
invoked. What if it were possible to compare two TextPair objects just by looking at their
serialized representations?
It turns out that we can do this because TextPair is the
concatenation of two Text objects,
and the binary representation of a Text object is a
variable-length integer containing the number of bytes in the UTF-8
representation of the string, followed by the UTF-8 bytes themselves.
The trick is to read the initial length so we know how long the first
Text object’s byte representation
is; then we can delegate to Text’s
RawComparator and
invoke it with the appropriate offsets for the first or second string.
Example 4-8 gives the details (note that
this code is nested in the TextPair
class).
Example 4-8. A RawComparator for comparing TextPair byte representations
public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1,
b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
static {
WritableComparator.define(TextPair.class, new Comparator());
}We actually subclass WritableComparator
rather than implement RawComparator
directly, since it provides some convenience methods and default
implementations. The subtle part of this code is calculating firstL1 and firstL2, the lengths of the first Text field in each byte stream. Each is made
up of the length of the variable-length integer (returned by
decodeVIntSize() on WritableUtils) and the value it is encoding
(returned by readVInt()).
The static block registers the raw comparator so that whenever
MapReduce sees the TextPair class, it
knows to use the raw comparator as its default comparator.
As we can see with TextPair, writing raw
comparators takes some care because you have to deal with details at
the byte level. It is worth looking at some of the implementations of
Writable in the org.apache.hadoop.io
package for further ideas if you need to write your own. The utility
methods on WritableUtils are
very handy, too.
Custom comparators should also be written to be RawComparators, if possible. These are
comparators that implement a different sort order from the natural
sort order defined by the default comparator. Example 4-9 shows a comparator for TextPair, called
FirstComparator, that
considers only the first string of the pair. Note that we override the
compare() method that takes
objects so both compare() methods have the same
semantics.
We will make use of this comparator in Chapter 8, when we look at joins and secondary sorting in MapReduce (see Joins).
Example 4-9. A custom RawComparator for comparing the first field of TextPair byte representations
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}Although most MapReduce programs use Writable key and value types, this isn’t
mandated by the MapReduce API. In fact, any type can be used; the only
requirement is a mechanism that translates to and from a binary
representation of each type.
To support this, Hadoop has an API for pluggable serialization
frameworks. A serialization framework is represented by an
implementation of Serialization (in
the org.apache.hadoop.io.serializer package).
WritableSerialization,
for example, is the implementation of Serialization for Writable types.
A Serialization defines a
mapping from types to Serializer
instances (for turning an object into a byte stream) and Deserializer instances (for turning a byte
stream into an object).
Set the io.serializations
property to a comma-separated list of classnames to register Serialization implementations. Its default
value includes org.apache.hadoop.io.serializer.WritableSerialization
and the Avro-specific and reflect serializations, which means that only
Writable or Avro
objects can be serialized or deserialized out of the box.
Hadoop includes a class called JavaSerialization that
uses Java Object Serialization. Although it makes it convenient to be
able to use standard Java types such as Integer or String in
MapReduce programs, Java Object Serialization is not as efficient as
Writables, so it’s not worth making this trade-off (see the sidebar
Why Not Use Java Object Serialization?).
There are a number of other serialization frameworks that approach the problem in a different way: rather than defining types through code, you define them in a language-neutral, declarative fashion, using an interface description language (IDL). The system can then generate types for different languages, which is good for interoperability. They also typically define versioning schemes that make type evolution straightforward.
Hadoop’s own Record I/O (found in the org.apache.hadoop.record package) has an IDL
that is compiled into Writable objects, which makes it convenient for
generating types that are compatible with MapReduce. For whatever
reason, however, Record I/O was
not widely used, and has been deprecated in favor of Avro.
Apache Thrift and Google Protocol Buffers are both popular serialization frameworks, and they are commonly used as a format for persistent binary data. There is limited support for these as MapReduce formats;[36] however, they are used internally in parts of Hadoop for RPC and data exchange.
In the next section, we look at Avro, an IDL-based serialization framework designed to work well with large-scale data processing in Hadoop.
Apache Avro[37] is a language-neutral data serialization system. The project was created by Doug Cutting (the creator of Hadoop) to address the major downside of Hadoop Writables: lack of language portability. Having a data format that can be processed by many languages (currently C, C++, C#, Java, PHP, Python, and Ruby) makes it easier to share datasets with a wider audience than one tied to a single language. It is also more future-proof, allowing data to potentially outlive the language used to read and write it.
But why a new data serialization system? Avro has a set of features that, taken together, differentiate it from other systems such as Apache Thrift or Google’s Protocol Buffers.[38] Like these systems and others, Avro data is described using a language-independent schema. However, unlike some other systems, code generation is optional in Avro, which means you can read and write data that conforms to a given schema even if your code has not seen that particular schema before. To achieve this, Avro assumes that the schema is always present—at both read and write time—which makes for a very compact encoding, since encoded values do not need to be tagged with a field identifier.
Avro schemas are usually written in JSON, and data is usually encoded using a binary format, but there are other options, too. There is a higher-level language called Avro IDL for writing schemas in a C-like language that is more familiar to developers. There is also a JSON-based data encoder, which, being human-readable, is useful for prototyping and debugging Avro data.
The Avro specification precisely defines the binary format that all implementations must support. It also specifies many of the other features of Avro that implementations should support. One area that the specification does not rule on, however, is APIs: implementations have complete latitude in the API they expose for working with Avro data, since each one is necessarily language-specific. The fact that there is only one binary format is significant, because it means the barrier for implementing a new language binding is lower and avoids the problem of a combinatorial explosion of languages and formats, which would harm interoperability.
Avro has rich schema resolution capabilities. Within certain carefully defined constraints, the schema used to read data need not be identical to the schema that was used to write the data. This is the mechanism by which Avro supports schema evolution. For example, a new, optional field may be added to a record by declaring it in the schema used to read the old data. New and old clients alike will be able to read the old data, while new clients can write new data that uses the new field. Conversely, if an old client sees newly encoded data, it will gracefully ignore the new field and carry on processing as it would have done with old data.
Avro specifies an object container format for sequences of objects—similar to Hadoop’s sequence file. An Avro datafile has a metadata section where the schema is stored, which makes the file self-describing. Avro datafiles support compression and are splittable, which is crucial for a MapReduce data input format. Furthermore, since Avro was designed with MapReduce in mind, in the future it will be possible to use Avro to bring first-class MapReduce APIs (that is, ones that are richer than Streaming, such as the Java API or C++ Pipes) to languages that speak Avro.
Avro can be used for RPC, too, although this isn’t covered here. More information is in the specification.
Avro defines a small number of primitive data types, which can be used to build application-specific data structures by writing schemas. For interoperability, implementations must support all Avro types.
Avro’s primitive types are listed in Table 4-9. Each primitive type may also be
specified using a more verbose form by using the type attribute, such as:
{ "type": "null" }Table 4-9. Avro primitive types
| Type | Description | Schema |
|---|---|---|
null | The absence of a value | "null" |
boolean | A binary value | "boolean" |
int | 32-bit signed integer | "int" |
long | 64-bit signed integer | "long" |
float | Single-precision (32-bit) IEEE 754 floating-point number | "float" |
double | Double-precision (64-bit) IEEE 754 floating-point number | "double" |
bytes | Sequence of 8-bit unsigned bytes | "bytes" |
string | Sequence of Unicode characters | "string" |
Avro also defines the complex types listed in Table 4-10, along with a representative example of a schema of each type.
Table 4-10. Avro complex types
Each Avro language API has a representation for each Avro type
that is specific to the language. For example, Avro’s double type is
represented in C, C++, and Java by a double, in Python by a float, and in Ruby by a Float.
What’s more, there may be more than one representation, or mapping, for a language. All languages support a dynamic mapping, which can be used even when the schema is not known ahead of runtime. Java calls this the generic mapping.
In addition, the Java and C++ implementations can generate code to represent the data for an Avro schema. Code generation, which is called the specific mapping in Java, is an optimization that is useful when you have a copy of the schema before you read or write data. Generated classes also provide a more domain-oriented API for user code than generic ones.
Java has a third mapping, the reflect mapping, which maps Avro types onto preexisting Java types using reflection. It is slower than the generic and specific mappings, and is generally not recommended for new applications.
Java’s type mappings are shown in Table 4-11. As the table shows, the specific
mapping is the same as the generic one unless otherwise noted (and the
reflect one is the same as the specific one unless noted). The specific
mapping differs from the generic one only for record, enum, and fixed, all of which have generated classes
(the name of which is controlled by the name and optional namespace
attribute).
Note
Avro string can be
represented by either Java String
or the Avro Utf8 Java type. The
reason to use Utf8 is efficiency:
because it is mutable, a single Utf8 instance may be reused for reading or
writing a series of values. Also, Java String decodes UTF-8 at object
construction time, whereas Avro Utf8 does it lazily, which can increase
performance in some cases.
Utf8 implements Java’s
java.lang.CharSequence interface, which
allows some interoperability with Java libraries. In other cases it
may be necessary to convert Utf8
instances to String objects by
calling its toString()
method.
From Avro 1.6.0 onward, there is an option to have Avro always
perform the conversion to String.
There are a couple of ways to achieve this. The
first is to set the avro.java.string
property in the schema to String:
{ "type": "string", "avro.java.string": "String" }Alternatively, for the specific mapping, you can generate
classes that have String-based
getters and setters. When using the Avro Maven plug-in, this is done
by setting the configuration property stringType to
String (the example code that
accompanies the book has a demonstration of this).
Finally, note that the Java reflect mapping always uses
String objects, since it is
designed for Java compatibility, not performance.
Table 4-11. Avro Java type mappings
Avro provides APIs for serialization and deserialization, which are useful when you want to integrate Avro with an existing system, such as a messaging system where the framing format is already defined. In other cases, consider using Avro’s datafile format.
Let’s write a Java program to read and write Avro data to and from streams. We’ll start with a simple Avro schema for representing a pair of strings as a record:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"}
]
}If this schema is saved in a file on the classpath called
StringPair.avsc (.avsc is the conventional extension for an
Avro schema), we can load it using the following two lines of
code:
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("StringPair.avsc"));We can create an instance of an Avro record using the generic API as follows:
GenericRecord datum = new GenericData.Record(schema);
datum.put("left", "L");
datum.put("right", "R");Next, we serialize the record to an output stream:
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();There are two important objects here: the DatumWriter and the Encoder. A DatumWriter
translates data objects into the types understood by an Encoder, which the latter writes to
the output stream. Here we are using a GenericDatumWriter, which passes
the fields of GenericRecord to the Encoder. We pass a null to the encoder factory because we are not
reusing a previously constructed encoder here.
In this example only one object is written to the stream, but we
could call write() with more
objects before closing the stream if we wanted to.
The GenericDatumWriter needs to be
passed the schema because it follows the schema to determine which
values from the data objects to write out. After we have called the
writer’s write() method, we flush the
encoder, then close the output stream.
We can reverse the process and read the object back from the byte buffer:
DatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder);
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));We pass null to the calls to
binaryDecoder() and read() because we are not reusing
objects here (the decoder or the record, respectively).
The objects returned by result.get("left") and result.get("left") are of type Utf8, so we convert them into Java String objects by calling their toString()
methods.
Let’s look now at the equivalent code using the specific
API. We can generate the StringPair class from the schema
file by using Avro’s Maven plug-in for compiling schemas. The
following is the relevant part of the Maven Project Object Model
(POM):
<project>
...
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<includes>
<include>StringPair.avsc</include>
</includes>
<sourceDirectory>src/main/resources</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/java
</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
...
</project>As an alternative to Maven, you can use Avro’s Ant task,
org.apache.avro.specific.SchemaTask, or the
Avro command-line tools[39] to generate Java code for a schema.
In the code for serializing and deserializing, instead of a
GenericRecord we construct a
StringPair instance, which we
write to the stream using a SpecificDatumWriter and read back
using a SpecificDatumReader:
StringPair datum = new StringPair(); datum.left = "L"; datum.right = "R"; ByteArrayOutputStream out = new ByteArrayOutputStream(); DatumWriter<StringPair> writer = new SpecificDatumWriter<StringPair>(StringPair.class); Encoder encoder = EncoderFactory.get().binaryEncoder(out, null); writer.write(datum, encoder); encoder.flush(); out.close(); DatumReader<StringPair> reader = new SpecificDatumReader<StringPair>(StringPair.class); Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null); StringPair result = reader.read(null, decoder); assertThat(result.left.toString(), is("L")); assertThat(result.right.toString(), is("R"));
From Avro 1.6.0, the generated Java code has getters and
setters, so you can instead write datum.setLeft("L") and result.getLeft().
Avro’s object container file format is for storing sequences of Avro objects. It is very similar in design to Hadoop’s sequence files, which are described in SequenceFile. The main difference is that Avro datafiles are designed to be portable across languages, so, for example, you can write a file in Python and read it in C (we will do exactly this in the next section).
A datafile has a header containing metadata, including the Avro schema and a sync marker, followed by a series of (optionally compressed) blocks containing the serialized Avro objects. Blocks are separated by a sync marker that is unique to the file (the marker for a particular file is found in the header) and that permits rapid resynchronization with a block boundary after seeking to an arbitrary point in the file, such as an HDFS block boundary. Thus, Avro datafiles are splittable, which makes them amenable to efficient MapReduce processing.
Writing Avro objects to a datafile is similar to writing to a
stream. We use a DatumWriter as
before, but instead of using an Encoder, we create a DataFileWriter instance with the
DatumWriter. Then we can create a
new datafile (which, by convention, has a .avro extension) and append objects to
it:
File file = new File("data.avro");
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter =
new DataFileWriter<GenericRecord>(writer);
dataFileWriter.create(schema, file);
dataFileWriter.append(datum);
dataFileWriter.close();The objects that we write to the datafile must conform to the
file’s schema; otherwise, an exception will be thrown when we call
append().
This example demonstrates writing to a local file (java.io.File in the previous
snippet), but we can write to any java.io.OutputStream by using the
overloaded create() method on DataFileWriter. To write a file to
HDFS, for example, get an OutputStream by calling create() on
FileSystem (see Writing Data).
Reading back objects from a datafile is similar to the earlier
case of reading objects from an in-memory stream, with one important
difference: we don’t have to specify a schema, since it is read from the
file metadata. Indeed, we can get the schema from the DataFileReader instance, using
getSchema(), and verify that it
is the same as the one we used to write the original object:
DatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>();
DataFileReader<GenericRecord> dataFileReader =
new DataFileReader<GenericRecord>(file, reader);
assertThat("Schema is the same", schema, is(dataFileReader.getSchema()));DataFileReader is a regular Java
iterator, so we can iterate through its data objects by calling its
hasNext() and next() methods. The following
snippet checks that there is only one record and that it has the
expected field values:
assertThat(dataFileReader.hasNext(), is(true));
GenericRecord result = dataFileReader.next();
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));
assertThat(dataFileReader.hasNext(), is(false));Rather than using the usual next() method, however, it is
preferable to use the overloaded form that takes an instance of the
object to be returned (in this case,
GenericRecord), since it
will reuse the object and save allocation and garbage collection costs
for files containing many objects. The following is idiomatic:
GenericRecord record = null;
while (dataFileReader.hasNext()) {
record = dataFileReader.next(record);
// process record
}If object reuse is not important, you can use this shorter form:
for (GenericRecord record : dataFileReader) {
// process record
}For the general case of reading a file on a Hadoop filesystem, use
Avro’s FsInput to specify the input file using a
Hadoop Path object. DataFileReader actually offers
random access to Avro datafiles (via its seek() and sync() methods); however, in many
cases, sequential streaming access is sufficient, for which DataFileStream should be used.
DataFileStream can read from any
Java InputStream.
To demonstrate Avro’s language interoperability, let’s write a datafile using one language (Python) and read it back with another (C).
The program in Example 4-10 reads
comma-separated strings from standard input and writes them as
StringPair records to
an Avro datafile. Like the Java code for writing a datafile, we create
a DatumWriter and a DataFileWriter object. Notice
that we have embedded the Avro schema in the code, although we could
equally well have read it from a file.
Python represents Avro records as dictionaries; each line that
is read from standard in is turned into a dict object and
appended to the DataFileWriter.
Example 4-10. A Python program for writing Avro record pairs to a datafile
import os
import string
import sys
from avro import schema
from avro import io
from avro import datafile
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.exit('Usage: %s <data_file>' % sys.argv[0])
avro_file = sys.argv[1]
writer = open(avro_file, 'wb')
datum_writer = io.DatumWriter()
schema_object = schema.parse("\
{ "type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"}
]
}")
dfw = datafile.DataFileWriter(writer, datum_writer, schema_object)
for line in sys.stdin.readlines():
(left, right) = string.split(line.strip(), ',')
dfw.append({'left':left, 'right':right});
dfw.close()Before we can run the program, we need to install Avro for Python:
%easy_install avro
To run the program, we specify the name of the file to write output to (pairs.avro) and send input pairs over standard in, marking the end of file by typing Ctrl-D:
%python avro/src/main/py/write_pairs.py pairs.avroa,1c,2b,3b,2^D
Next we’ll turn to the C API and write a program to display the contents of pairs.avro; see Example 4-11.[40]
Example 4-11. A C program for reading Avro record pairs from a datafile
#include <avro.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: dump_pairs <data_file>\n");
exit(EXIT_FAILURE);
}
const char *avrofile = argv[1];
avro_schema_error_t error;
avro_file_reader_t filereader;
avro_datum_t pair;
avro_datum_t left;
avro_datum_t right;
int rval;
char *p;
avro_file_reader(avrofile, &filereader);
while (1) {
rval = avro_file_reader_read(filereader, NULL, &pair);
if (rval) break;
if (avro_record_get(pair, "left", &left) == 0) {
avro_string_get(left, &p);
fprintf(stdout, "%s,", p);
}
if (avro_record_get(pair, "right", &right) == 0) {
avro_string_get(right, &p);
fprintf(stdout, "%s\n", p);
}
}
avro_file_reader_close(filereader);
return 0;
}The core of the program does three things:
Opens a file reader of type
avro_file_reader_tby calling Avro’savro_file_readerfunction[41]Reads Avro data from the file reader with the
avro_file_reader_readfunction in a while loop until there are no pairs left (as determined by the return valuerval)Closes the file reader with
avro_file_reader_close
The avro_file_reader_read
function accepts a schema as its second argument to support the case
where the schema for reading is different from the one used when the
file was written (this is explained in the next section), but we
simply pass in NULL, which tells
Avro to use the datafile’s schema. The third argument is a pointer to
a avro_datum_t object,
which is populated with the contents of the next record read from the
file. We unpack the pair structure into its fields by calling avro_record_get, and then we extract the
value of these fields as strings using avro_string_get, which we print to the
console.
Running the program using the output of the Python program prints the original input:
%./dump_pairs pairs.avroa,1 c,2 b,3 b,2
We have successfully exchanged complex data between two Avro implementations.
We can choose to use a different schema for reading the
data back (the reader’s schema) from the one we
used to write it (the writer’s schema). This is a
powerful tool because it enables schema evolution. To illustrate,
consider a new schema for string pairs with an added description field:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings with an added field.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"},
{"name": "description", "type": "string", "default": "}
]
}We can use this schema to read the data we serialized earlier
because crucially, we have given the description field a default value (the empty
string),[42] which Avro will use when there is no field defined in the
records it is reading. Had we omitted the default attribute, we would get an error when
trying to read the old data.
Note
To make the default value null rather than the empty string, we would
instead define the description field using a union with the null Avro type:
{"name": "description", "type": ["null", "string"], "default": null}When the reader’s schema is different from the writer’s, we use
the constructor for GenericDatumReader that takes two
schema objects, the writer’s and the reader’s, in that order:
DatumReader<GenericRecord> reader =
new GenericDatumReader<GenericRecord>(schema, newSchema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder);
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));
assertThat(result.get("description").toString(), is("));For datafiles, which have the writer’s schema stored in the
metadata, we only need to specify the readers’s schema explicitly, which
we can do by passing null for the
writer’s schema:
DatumReader<GenericRecord> reader =
new GenericDatumReader<GenericRecord>(null, newSchema);Another common use of a different reader’s schema is to drop
fields in a record, an operation called
projection. This is useful when you have records
with a large number of fields and you want to read only some of them.
For example, this schema can be used to get only the right field of a StringPair:
{
"type": "record",
"name": "StringPair",
"doc": "The right field of a pair of strings.",
"fields": [
{"name": "right", "type": "string"}
]
}The rules for schema resolution have a direct bearing on how schemas may evolve from one version to the next, and are spelled out in the Avro specification for all Avro types. A summary of the rules for record evolution from the point of view of readers and writers (or servers and clients) is presented in Table 4-12.
Table 4-12. Schema resolution of records
| New schema | Writer | Reader | Action |
|---|---|---|---|
| Added field | Old | New | The reader uses the default value of the new field, since it is not written by the writer. |
| New | Old | The reader does not know about the new field written by the writer, so it is ignored (projection). | |
| Removed field | Old | New | The reader ignores the removed field (projection). |
| New | Old | The removed field is not written by the writer. If the old schema had a default defined for the field, the reader uses this; otherwise, it gets an error. In this case, it is best to update the reader’s schema, either at the same time as or before the writer’s. |
Another useful technique for evolving Avro schemas is the use of
name aliases. Aliases allow you to use
different names in the schema used to read the Avro data than in the
schema originally used to write the data. For example, the following
reader’s schema can be used to read StringPair data with
the new field names first and
second instead of left and right (which is what it was written
with).
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings with aliased field names.",
"fields": [
{"name": "first", "type": "string", "aliases": ["left"]},
{"name": "second", "type": "string", "aliases": ["right"]}
]
}Note that the aliases are used to translate (at read time) the
writer’s schema into the reader’s, but the alias names are not available
to the reader. In this example, the reader cannot use the field names
left and right, because they have already been
translated to first and second.
Avro defines a sort order for objects. For most Avro types, the order is the natural one you would expect—for example, numeric types are ordered by ascending numeric value. Others are a little more subtle. For instance, enums are compared by the order in which the symbol is defined and not by the value of the symbol string.
All types except record have
preordained rules for their sort order, as described in the Avro
specification, that cannot be overridden by the user. For records,
however, you can control the sort order by specifying the order attribute for a field. It takes one of
three values: ascending (the
default), descending (to reverse the
order), or ignore (so the field is
skipped for comparison purposes).
For example, the following schema (SortedStringPair.avsc) defines an ordering of
StringPair records by
the right field in descending order.
The left field is ignored for the
purposes of ordering, but it is still present in the projection:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings, sorted by right field descending.",
"fields": [
{"name": "left", "type": "string", "order": "ignore"},
{"name": "right", "type": "string", "order": "descending"}
]
}The record’s fields are compared pairwise in the document order of
the reader’s schema. Thus, by specifying an appropriate reader’s schema,
you can impose an arbitrary ordering on data records. This schema
(SwitchedStringPair.avsc) defines a
sort order by the right field, then
the left:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings, sorted by right then left.",
"fields": [
{"name": "right", "type": "string"},
{"name": "left", "type": "string"}
]
}Avro implements efficient binary comparisons. That is to say, Avro
does not have to deserialize a binary data into objects to perform the
comparison, because it can instead work directly on the byte
streams.[43] In the case of the original StringPair schema (with
no order attributes), for example,
Avro implements the binary comparison as follows.
The first field, left, is a
UTF-8-encoded string, for which Avro can compare the bytes
lexicographically. If they differ, the order is determined, and Avro can
stop the comparison there. Otherwise, if the two-byte sequences are the
same, it compares the second two (right) fields, again lexicographically at the
byte level because the field is another UTF-8 string.
Notice that this description of a comparison function has exactly the same logic as the binary comparator we wrote for Writables in Implementing a RawComparator for speed. The great thing is that Avro provides the comparator for us, so we don’t have to write and maintain this code. It’s also easy to change the sort order just by changing the reader’s schema. For the SortedStringPair.avsc or SwitchedStringPair.avsc schemas, the comparison function Avro uses is essentially the same as the one just described. The differences are which fields are considered, the order in which they are considered, and whether the sort order is ascending or descending.
Later in the chapter we’ll use Avro’s sorting logic in conjunction with MapReduce to sort Avro datafiles in parallel.
Avro provides a number of classes for making it easy to
run MapReduce programs on Avro data. For example, AvroMapper and AvroReducer in the org.apache.avro.mapred
package are specializations of Hadoop’s (old-style) Mapper and Reducer classes. They eliminate the
key-value distinction for inputs and outputs, since Avro datafiles are
just a sequence of values. However, intermediate data is still divided
into key-value pairs for the shuffle.
Let’s rework the MapReduce program for finding the maximum temperature for each year in the weather dataset, this time using the Avro MapReduce API. We will represent weather records using the following schema:
{
"type": "record",
"name": "WeatherRecord",
"doc": "A weather reading.",
"fields": [
{"name": "year", "type": "int"},
{"name": "temperature", "type": "int"},
{"name": "stationId", "type": "string"}
]
}The program in Example 4-12 reads text input (in the format we saw in earlier chapters) and writes Avro datafiles containing weather records as output.
Example 4-12. MapReduce program to find the maximum temperature, creating Avro output
public class AvroGenericMaxTemperature extends Configured implements Tool {
private static final Schema SCHEMA = new Schema.Parser().parse(
"{" +
" \"type\": \"record\"," +
" \"name\": \"WeatherRecord\"," +
" \"doc\": \"A weather reading.\"," +
" \"fields\": [" +
" {\"name\": \"year\", \"type\": \"int\"}," +
" {\"name\": \"temperature\", \"type\": \"int\"}," +
" {\"name\": \"stationId\", \"type\": \"string\"}" +
" ]" +
"}"
);
public static class MaxTemperatureMapper
extends AvroMapper<Utf8, Pair<Integer, GenericRecord>> {
private NcdcRecordParser parser = new NcdcRecordParser();
private GenericRecord record = new GenericData.Record(SCHEMA);
@Override
public void map(Utf8 line,
AvroCollector<Pair<Integer, GenericRecord>> collector,
Reporter reporter) throws IOException {
parser.parse(line.toString());
if (parser.isValidTemperature()) {
record.put("year", parser.getYearInt());
record.put("temperature", parser.getAirTemperature());
record.put("stationId", parser.getStationId());
collector.collect(
new Pair<Integer, GenericRecord>(parser.getYearInt(), record));
}
}
}
public static class MaxTemperatureReducer
extends AvroReducer<Integer, GenericRecord, GenericRecord> {
@Override
public void reduce(Integer key, Iterable<GenericRecord> values,
AvroCollector<GenericRecord> collector, Reporter reporter)
throws IOException {
GenericRecord max = null;
for (GenericRecord value : values) {
if (max == null ||
(Integer) value.get("temperature") > (Integer) max.get("temperature")) {
max = newWeatherRecord(value);
}
}
collector.collect(max);
}
private GenericRecord newWeatherRecord(GenericRecord value) {
GenericRecord record = new GenericData.Record(SCHEMA);
record.put("year", value.get("year"));
record.put("temperature", value.get("temperature"));
record.put("stationId", value.get("stationId"));
return record;
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
JobConf conf = new JobConf(getConf(), getClass());
conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
AvroJob.setInputSchema(conf, Schema.create(Schema.Type.STRING));
AvroJob.setMapOutputSchema(conf,
Pair.getPairSchema(Schema.create(Schema.Type.INT), SCHEMA));
AvroJob.setOutputSchema(conf, SCHEMA);
conf.setInputFormat(AvroUtf8InputFormat.class);
AvroJob.setMapperClass(conf, MaxTemperatureMapper.class);
AvroJob.setReducerClass(conf, MaxTemperatureReducer.class);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new AvroGenericMaxTemperature(), args);
System.exit(exitCode);
}
}This program uses the generic Avro mapping. This frees us from
generating code to represent records, at the expense of type safety
(field names are referred to by string value, such as "temperature").[44] The schema for weather records is inlined in the code for
convenience (and read into the SCHEMA
constant), although in practice it might be more maintainable to read
the schema from a local file in the driver code and pass it to the
mapper and reducer via the Hadoop job configuration. (Techniques for
achieving this are discussed in Side Data Distribution.)
There are a couple of differences from the regular Hadoop
MapReduce API. The first is the use of a org.apache.avro.mapred.Pair to wrap the map
output key and value in MaxTemperatureMapper.
(The reason that the org.apache.avro.mapred.AvroMapper doesn’t have
a fixed output key and value is so that map-only jobs can emit just
values to Avro datafiles.) For this MapReduce program, the key is the
year (an integer), and the value is the weather record, which is
represented by Avro’s GenericRecord.
Avro MapReduce does preserve the notion of key-value pairs for the
input to the reducer, however, because this is what comes out of the
shuffle, and it unwraps the Pair
before invoking the org.apache.avro.mapred.AvroReducer. The
MaxTemperatureReducer
iterates through the records for each key (year) and finds the one with
the maximum temperature. It is necessary to make a copy of the record
with the highest temperature found so far, since the iterator reuses the
instance for reasons of efficiency (and only the fields are
updated).
The second major difference from regular MapReduce is the use of
AvroJob for configuring
the job. AvroJob is a
convenience class for specifying the Avro schemas for the input, map
output, and final output data. In this program the input schema is an
Avro string because we are reading
from a text file, and the input format is set correspondingly, to
AvroUtf8InputFormat. The map output
schema is a pair schema whose key schema is an Avro int and whose value schema is the weather
record schema. The final output schema is the weather record schema, and
the output format is the default, AvroOutputFormat, which
writes to Avro datafiles.
The following command line shows how to run the program on a small sample dataset:
%hadoop jar avro-examples.jar AvroGenericMaxTemperature \ input/ncdc/sample.txt output
On completion we can look at the output using the Avro tools JAR to render the Avro datafile as JSON, one record per line:
%java -jar $AVRO_HOME/avro-tools-*.jar tojson output/part-00000.avro{"year":1949,"temperature":111,"stationId":"012650-99999"} {"year":1950,"temperature":22,"stationId":"011990-99999"}
In this example, we used an AvroMapper and an
AvroReducer, but the
API supports a mixture of regular MapReduce mappers and reducers with
Avro-specific ones, which is useful for converting between Avro formats
and other formats, such as SequenceFiles. See the documentation for the
Avro MapReduce package for details.
In this section we use Avro’s sort capabilities and combine them with MapReduce to write a program to sort an Avro datafile (Example 4-13).
Example 4-13. A MapReduce program to sort an Avro datafile
public class AvroSort extends Configured implements Tool {
static class SortMapper<K> extends AvroMapper<K, Pair<K, K>> {
public void map(K datum, AvroCollector<Pair<K, K>> collector,
Reporter reporter) throws IOException {
collector.collect(new Pair<K, K>(datum, null, datum, null));
}
}
static class SortReducer<K> extends AvroReducer<K, K, K> {
public void reduce(K key, Iterable<K> values,
AvroCollector<K> collector,
Reporter reporter) throws IOException {
for (K value : values) {
collector.collect(value);
}
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 3) {
System.err.printf(
"Usage: %s [generic options] <input> <output> <schema-file>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
String input = args[0];
String output = args[1];
String schemaFile = args[2];
JobConf conf = new JobConf(getConf(), getClass());
conf.setJobName("Avro sort");
FileInputFormat.addInputPath(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
Schema schema = new Schema.Parser().parse(new File(schemaFile));
AvroJob.setInputSchema(conf, schema);
Schema intermediateSchema = Pair.getPairSchema(schema, schema);
AvroJob.setMapOutputSchema(conf, intermediateSchema);
AvroJob.setOutputSchema(conf, schema);
AvroJob.setMapperClass(conf, SortMapper.class);
AvroJob.setReducerClass(conf, SortReducer.class);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new AvroSort(), args);
System.exit(exitCode);
}
}This program (which uses the generic Avro mapping and hence does
not require any code generation) can sort Avro records of any type,
represented in Java by the generic type parameter K. We choose a value that is the same as the
key, so that when the values are grouped by key we can emit all of the
values in the case that more than one of them share the same key
(according to the sorting function), thereby not losing any
records.[45] The mapper simply emits an org.apache.avro.mapred.Pair object with this
key and value. The reducer acts as an identity, passing the values
through to the (single-valued) output, which will get written to an Avro
datafile.
The sorting happens in the MapReduce shuffle, and the sort function is determined by the Avro schema that is passed to the program. Let’s use the program to sort the pairs.avro file created earlier, using the SortedStringPair.avsc schema to sort by the right field in descending order. First, we inspect the input using the Avro tools JAR:
%java -jar $AVRO_HOME/avro-tools-*.jar tojson input/avro/pairs.avro{"left":"a","right":"1"} {"left":"c","right":"2"} {"left":"b","right":"3"} {"left":"b","right":"2"}
Then we run the sort:
%hadoop jar avro-examples.jar AvroSort input/avro/pairs.avro output \ ch04-avro/src/main/resources/SortedStringPair.avsc
Finally, we inspect the output and see that it is sorted correctly.
%java -jar $AVRO_HOME/avro-tools-*.jar tojson output/part-00000.avro{"left":"b","right":"3"} {"left":"c","right":"2"} {"left":"b","right":"2"} {"left":"a","right":"1"}
For languages other than Java, there are a few choices for working with Avro data.
AvroAsTextInputFormat
is designed to allow Hadoop Streaming programs to read Avro datafiles.
Each datum in the file is converted to a string, which is the JSON
representation of the datum, or just to the raw bytes if the type is
Avro bytes. Going the other way, you
can specify AvroTextOutputFormat as
the output format of a Streaming job to create Avro datafiles with a
bytes schema, where each datum is the
tab-delimited key-value pair written from the Streaming output. Both of
these classes can be found in the org.apache.avro.mapred
package.
For a richer interface than Streaming, Avro provides a connector
framework (in the org.apache.avro.mapred.tether package), which
is the Avro analog of Hadoop Pipes. At the time of this writing, there
are no bindings for other languages, but a Python implementation will be
available in a future release.
It’s also worth considering Pig and Hive for doing Avro processing, since both can read and write Avro datafiles by specifying the appropriate storage formats.
For some applications, you need a specialized data structure to hold your data. For doing MapReduce-based processing, putting each blob of binary data into its own file doesn’t scale, so Hadoop developed a number of higher-level containers for these situations.
Imagine a logfile where each log record is a new line of
text. If you want to log binary types, plain text isn’t a suitable
format. Hadoop’s SequenceFile class
fits the bill in this situation,
providing a persistent data structure for binary key-value pairs. To use
it as a logfile format, you would choose a key, such as timestamp
represented by a LongWritable, and the value would be
Writable that represents the quantity
being logged.
SequenceFiles also work
well as containers for smaller files. HDFS and MapReduce are optimized for large files, so packing
files into a SequenceFile makes
storing and processing the smaller
files more efficient. (Processing a whole file as a record contains a
program to pack files into a SequenceFile).[46]
To create a SequenceFile, use one of its createWriter() static
methods, which return a SequenceFile.Writer
instance. There are several overloaded versions, but they all require you to specify a stream to write
to (either an FSDataOutputStream or
a FileSystem and Path pairing), a Configuration object,
and the key and value types. Optional arguments include the
compression type and codec, a Progressable callback to be informed of
write progress, and a Metadata
instance to be stored in the SequenceFile header.
The keys and values stored in a SequenceFile do not necessarily need to be
Writable. Any types that can be
serialized and deserialized by a Serialization may be used.
Once you have a SequenceFile.Writer,
you then write key-value pairs using the append() method. When
you’ve finished, you call the close() method
(SequenceFile.Writer
implements java.io.Closeable).
Example 4-14 shows a short program
to write some key-value pairs to a SequenceFile using the API just
described.
Example 4-14. Writing a SequenceFile
public class SequenceFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}The keys in the sequence file are integers counting down from
100 to 1, represented as IntWritable objects.
The values are Text objects. Before
each record is appended to the SequenceFile.Writer,
we call the getLength() method to
discover the current position in the file. (We will use this
information about record boundaries in the next section when we read
the file nonsequentially.) We write the position out to the console,
along with the key and value pairs. The result of running it is shown
here:
% hadoop SequenceFileWriteDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
...
[1976] 60 One, two, buckle my shoe
[2021] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat henReading sequence files from beginning to end is a matter
of creating an instance of SequenceFile.Reader
and iterating over records by repeatedly invoking one of the
next() methods. Which
one you use depends on the serialization framework you are using. If
you are using Writable types, you
can use the next() method that
takes a key and a value argument and reads the next key and value in
the stream into these variables:
public boolean next(Writable key, Writable val)
The return value is true if a
key-value pair was read and false
if the end of the file has been reached.
For other, non-Writable
serialization frameworks (such as Apache Thrift), you should use these
two methods:
public Object next(Object key) throws IOException public Object getCurrentValue(Object val) throws IOException
In this case, you need to make sure that the serialization you
want to use has been set in the io.serializations
property; see Serialization Frameworks.
If the next() method returns
a non-null object, a key-value pair
was read from the stream, and the value can be retrieved using the
getCurrentValue()
method. Otherwise, if next() returns
null, the end of the file has been
reached.
The program in Example 4-15
demonstrates how to read a sequence file that has Writable keys and
values. Note how the types are discovered from the SequenceFile.Reader
via calls to getKeyClass() and
getValueClass(), and
then ReflectionUtils is
used to create an instance for the key and an instance for the value.
By using this technique, the program can be used with any sequence
file that has Writable keys and
values.
Example 4-15. Reading a SequenceFile
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : ";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}Another feature of the program is that it displays the position
of the sync points in the sequence file. A sync
point is a point in the stream that can be used to resynchronize with
a record boundary if the reader is “lost”—for example, after seeking
to an arbitrary position in the stream. Sync points are recorded by
SequenceFile.Writer,
which inserts a special entry to mark the sync point every few records
as a sequence file is being written. Such entries are small enough to
incur only a modest storage overhead—less than 1%. Sync points always
align with record boundaries.
Running the program in Example 4-15 shows the sync points in the sequence file as asterisks. The first one occurs at position 2021 (the second one occurs at position 4075, but is not shown in the output):
% hadoop SequenceFileReadDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
[590] 90 One, two, buckle my shoe
...
[1976] 60 One, two, buckle my shoe
[2021*] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat henThere are two ways to seek to a given position in a sequence
file. The first is the seek() method, which
positions the reader at the given point in the file. For example,
seeking to a record boundary works as expected:
reader.seek(359);
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(95));But if the position in the file is not at a record boundary, the
reader fails when the next() method is
called:
reader.seek(360);
reader.next(key, value); // fails with IOExceptionThe second way to find a record boundary makes use of sync
points. The sync(long position)
method on SequenceFile.Reader
positions the reader at the next sync point after position. (If there are no sync points in
the file after this position, then the reader will be positioned at
the end of the file.) Thus, we can call sync() with any
position in the stream—a nonrecord boundary, for example—and the
reader will reestablish itself at the next sync point so reading can
continue:
reader.sync(360);
assertThat(reader.getPosition(), is(2021L));
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(59));Warning
SequenceFile.Writer
has a method called sync() for
inserting a sync point at the current position in the stream. This
is not to be confused with the identically named but otherwise
unrelated sync() method
defined by the Syncable interface
for synchronizing buffers to the underlying device.
Sync points come into their own when using sequence files as input to MapReduce, since they permit the file to be split and different portions of it can be processed independently by separate map tasks. See SequenceFileInputFormat.
The hadoop fs command
has a -text option to display
sequence files in textual form. It looks at a file’s magic number so
that it can attempt to detect the type of the file and appropriately
convert it to text. It can recognize gzipped files and sequence files;
otherwise, it assumes the input is plain text.
For sequence files, this command is really useful only if the
keys and values have a meaningful string representation (as defined by
the toString() method).
Also, if you have your own key or value classes, you will need to make
sure they are on Hadoop’s classpath.
Running it on the sequence file we created in the previous section gives the following output:
% hadoop fs -text numbers.seq | head
100 One, two, buckle my shoe
99 Three, four, shut the door
98 Five, six, pick up sticks
97 Seven, eight, lay them straight
96 Nine, ten, a big fat hen
95 One, two, buckle my shoe
94 Three, four, shut the door
93 Five, six, pick up sticks
92 Seven, eight, lay them straight
91 Nine, ten, a big fat henThe most powerful way of sorting (and merging) one or more sequence files is to use MapReduce. MapReduce is inherently parallel and will let you specify the number of reducers to use, which determines the number of output partitions. For example, by specifying one reducer, you get a single output file. We can use the sort example that comes with Hadoop by specifying that the input and output are sequence files and by setting the key and value types:
%hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar sort -r 1 \-inFormat org.apache.hadoop.mapred.SequenceFileInputFormat \-outFormat org.apache.hadoop.mapred.SequenceFileOutputFormat \-outKey org.apache.hadoop.io.IntWritable \-outValue org.apache.hadoop.io.Text \numbers.seq sorted%hadoop fs -text sorted/part-00000 | head1 Nine, ten, a big fat hen 2 Seven, eight, lay them straight 3 Five, six, pick up sticks 4 Three, four, shut the door 5 One, two, buckle my shoe 6 Nine, ten, a big fat hen 7 Seven, eight, lay them straight 8 Five, six, pick up sticks 9 Three, four, shut the door 10 One, two, buckle my shoe
Sorting is covered in more detail in Sorting.
As an alternative to using MapReduce for sort/merge, there is a
SequenceFile.Sorter
class that has a number of sort() and merge() methods.
These functions predate MapReduce and are lower-level functions than
MapReduce (for example, to get parallelism, you need to partition your
data manually), so in general MapReduce is the preferred approach to
sort and merge sequence files.
A sequence file consists of a header followed by one or
more records (see Figure 4-2). The first three
bytes of a sequence file are the bytes SEQ, which acts as a magic number, followed
by a single byte representing the version number. The header contains
other fields, including the names of the key and value classes,
compression details, user-defined metadata, and the sync
marker.[47] Recall that the sync marker is used to allow a reader to
synchronize to a record boundary from any position in the file. Each
file has a randomly generated sync marker, whose value is stored in
the header. Sync markers appear between records in the sequence file.
They are designed to incur less than a 1% storage overhead, so they
don’t necessarily appear between every pair of records (such is the
case for short records).
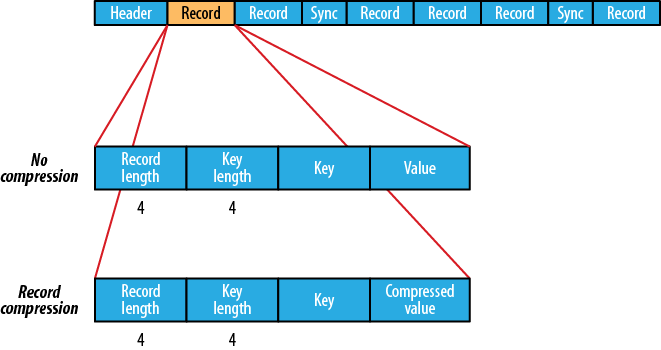
Figure 4-2. The internal structure of a sequence file with no compression and with record compression
The internal format of the records depends on whether compression is enabled, and if it is, whether it is record compression or block compression.
If no compression is enabled (the default), each record is made
up of the record length (in bytes), the key length, the key, and then
the value. The length fields are written as four-byte integers
adhering to the contract of the writeInt() method of java.io.DataOutput.
Keys and values are serialized using the Serialization defined for the class being
written to the sequence file.
The format for record compression is almost identical to no compression, except the value bytes are compressed using the codec defined in the header. Note that keys are not compressed.
Block compression compresses multiple records at once; it is
therefore more compact than and should generally be preferred over
record compression because it has the opportunity to take advantage of
similarities between records. (See Figure 4-3.) Records are added to a block until
it reaches a minimum size in bytes, defined by the io.seqfile.compress.blocksize property;
the default is 1 million bytes. A sync marker is written before the
start of every block. The format of a block is a field indicating the
number of records in the block, followed by four compressed fields:
the key lengths, the keys, the value lengths, and the
values.
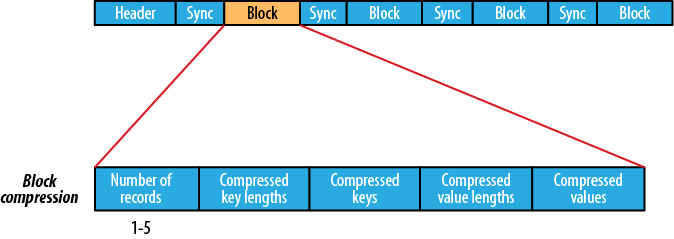
A MapFile is a sorted
SequenceFile with an index to permit
lookups by key. MapFile can be
thought of as a persistent form of java.util.Map (although it doesn’t implement
this interface), which is able to grow beyond the size of a Map that is kept in memory.
Writing a MapFile is
similar to writing a SequenceFile:
you create an instance of MapFile.Writer, then call the
append() method to
add entries in order. (Attempting to add entries out of order will
result in an IOException.) Keys
must be instances of WritableComparable, and values must be
Writable. Contrast this to SequenceFile, which can use any
serialization framework for its entries.
The program in Example 4-16 creates a
MapFile and writes some entries to
it. It is very similar to the program in Example 4-14 for creating a SequenceFile.
Example 4-16. Writing a MapFile
public class MapFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null;
try {
writer = new MapFile.Writer(conf, fs, uri,
key.getClass(), value.getClass());
for (int i = 0; i < 1024; i++) {
key.set(i + 1);
value.set(DATA[i % DATA.length]);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}Let’s use this program to build a MapFile:
% hadoop MapFileWriteDemo numbers.mapIf we look at the MapFile, we
see it’s actually a directory containing two files called data and index:
% ls -l numbers.map
total 104
-rw-r--r-- 1 tom tom 47898 Jul 29 22:06 data
-rw-r--r-- 1 tom tom 251 Jul 29 22:06 indexBoth files are SequenceFiles. The
data file contains all of the
entries, in order:
% hadoop fs -text numbers.map/data | head
1 One, two, buckle my shoe
2 Three, four, shut the door
3 Five, six, pick up sticks
4 Seven, eight, lay them straight
5 Nine, ten, a big fat hen
6 One, two, buckle my shoe
7 Three, four, shut the door
8 Five, six, pick up sticks
9 Seven, eight, lay them straight
10 Nine, ten, a big fat henThe index file contains a fraction of the keys and contains a mapping from the key to that key’s offset in the data file:
% hadoop fs -text numbers.map/index
1 128
129 6079
257 12054
385 18030
513 24002
641 29976
769 35947
897 41922As we can see from the output, by default only every 128th key
is included in the index, although you can change this value either by
setting the io.map.index.interval
property or by calling the
setIndexInterval() method on
the MapFile.Writer
instance. A reason to increase the index interval would be to decrease
the amount of memory that the MapFile needs to store the index.
Conversely, you might decrease the interval to improve the time for
random selection (since fewer records need to be skipped on average)
at the expense of memory usage.
Because the index is only a partial index of keys, MapFile is not able to provide methods to
enumerate, or even count, all the keys it contains. The only way to
perform these operations is to read the whole file.
Iterating through the entries in order in a MapFile is similar to the procedure for a
SequenceFile: you create a
MapFile.Reader, then
call the next() method until
it returns false, signifying that
no entry was read because the end of the file was reached:
public boolean next(WritableComparable key, Writable val) throws IOException
A random access lookup can be performed by calling the
get() method:
public Writable get(WritableComparable key, Writable val) throws IOException
The return value is used to determine whether an entry was found
in the MapFile; if it’s null, no value exists for the given key. If key was found, the value for that key is
read into val, as well as being
returned from the method call.
It might be helpful to understand how this is implemented. Here
is a snippet of code that retrieves an entry for the MapFile we created in the previous
section:
Text value = new Text();
reader.get(new IntWritable(496), value);
assertThat(value.toString(), is("One, two, buckle my shoe"));For this operation, the MapFile.Reader reads
the index file into memory (this
is cached so that subsequent random access calls will use the same
in-memory index). The reader then performs a binary search on the
in-memory index to find the key in the index that is less than or
equal to the search key, 496. In this example, the index key found is
385, with value 18030, which is the offset in the data file. Next, the reader seeks to this
offset in the data file and reads
entries until the key is greater than or equal to the search key
(496). In this case, a match is found and the value is read from the
data file. Overall, a lookup
takes a single disk seek and a scan through up to 128 entries on disk.
For a random-access read, this is actually very efficient.
The getClosest() method
is like get(), except it
returns the “closest” match to the specified key rather than returning
null on no match. More precisely,
if the MapFile contains the
specified key, then that is the entry returned; otherwise, the key in
the MapFile that is immediately
after (or before, according to a boolean argument) the specified key is
returned.
A very large MapFile’s index
can take up a lot of memory. Rather than reindex to change the index
interval, it is possible to load only a fraction of the index keys
into memory when reading the MapFile by setting the io.map.index.skip
property. This property is normally 0, which means no index keys are skipped; a
value of 1 means skip one key for
every key in the index (so every other key ends up in the index),
2 means skip two keys for every key
in the index (so one third of the keys end up in the index), and so
on. Larger skip values save memory but at the expense of lookup time,
since on average, more entries have to be scanned on disk.
Hadoop comes with a few variants on the general
key-value MapFile interface:
SetFileis a specialization ofMapFilefor storing a set ofWritablekeys. The keys must be added in sorted order.ArrayFileis aMapFilewhere the key is an integer representing the index of the element in the array and the value is aWritablevalue.BloomMapFileis aMapFilethat offers a fast version of theget()method, especially for sparsely populated files. The implementation uses a dynamic bloom filter for testing whether a given key is in the map. The test is very fast because it is in-memory, but it has a nonzero probability of false positives, in which case the regularget()method is called.There are two tuning parameters:
io.mapfile.bloom.sizefor the (approximate) number of entries in the map (default 1,048,576) andio.mapfile.bloom.error.ratefor the desired maximum error rate (default 0.005, which is 0.5%).
One way of looking at a MapFile is as an indexed and sorted SequenceFile. So it’s quite natural to want
to be able to convert a SequenceFile into a MapFile. We covered how to sort a SequenceFile in Sorting and merging SequenceFiles, so here we look at how to
create an index for a SequenceFile.
The program in Example 4-17 hinges around the
static utility method fix() on MapFile, which re-creates the index for a
MapFile.
Example 4-17. Re-creating the index for a MapFile
public class MapFileFixer {
public static void main(String[] args) throws Exception {
String mapUri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(mapUri), conf);
Path map = new Path(mapUri);
Path mapData = new Path(map, MapFile.DATA_FILE_NAME);
// Get key and value types from data sequence file
SequenceFile.Reader reader = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = reader.getKeyClass();
Class valueClass = reader.getValueClass();
reader.close();
// Create the map file index file
long entries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
System.out.printf("Created MapFile %s with %d entries\n", map, entries);
}
}The fix() method is
usually used for recreating corrupted indexes, but because it creates
a new index from scratch, it’s exactly what we need here. The recipe
is as follows:
Sort the sequence file numbers.seq into a new directory called number.map that will become the
MapFile(if the sequence file is already sorted, you can skip this step; instead, copy it to a file number.map/data, and go to step 3):%
hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar sort -r 1 \-inFormat org.apache.hadoop.mapred.SequenceFileInputFormat \-outFormat org.apache.hadoop.mapred.SequenceFileOutputFormat \-outKey org.apache.hadoop.io.IntWritable \-outValue org.apache.hadoop.io.Text \numbers.seq numbers.mapRename the MapReduce output to be the data file:
%
hadoop fs -mv numbers.map/part-00000 numbers.map/dataCreate the index file:
%
hadoop MapFileFixer numbers.mapCreated MapFile numbers.map with 100 entries
[34] For a comprehensive set of compression benchmarks, https://github.com/ning/jvm-compressor-benchmark is a good reference for JVM-compatible libraries (includes some native libraries). For command-line tools, see Jeff Gilchrist’s Archive Comparison Test at http://compression.ca/act/act-summary.html.
[35] This example is based on one from the article “Supplementary Characters in the Java Platform.”
[36] Twitter’s Elephant Bird project (http://github.com/kevinweil/elephant-bird) includes tools for working with Thrift and Protocol Buffers in Hadoop.
[37] Named after the British aircraft manufacturer from the 20th century.
[38] Avro also performs favorably compared to other serialization libraries, as the benchmarks at http://code.google.com/p/thrift-protobuf-compare/ demonstrate.
[39] Avro can be downloaded in both source and binary forms from
http://avro.apache.org/releases.html. Get
usage instructions for the Avro tools by typing java -jar
avro-tools-*.jar.
[40] For the general case, the Avro tools JAR file has a
tojson command
that dumps the contents of a Avro datafile as JSON.
[41] Avro functions and types have a avro_ prefix and are defined in the
avro.h header
file.
[42] Default values for fields are encoded using JSON. See the Avro specification for a description of this encoding for each data type.
[43] A useful consequence of this property is that you can compute
an Avro datum’s hash code from either the object or the binary
representation (the latter by using the static hashCode() method on
BinaryData) and get the same result in both
cases.
[44] For an example that uses the specific mapping with generated
classes, see the AvroSpecificMaxTemperature class in the
example code.
[45] We encounter this idea of duplicating information from the key in the value object again in Secondary Sort.
[46] In a similar vein, the blog post “A Million Little Files” by
Stuart Sierra includes code for converting a tar file into a SequenceFile (().
[47] Full details of the format of these fields may be found in
SequenceFile’s documentation
and source code.
Get Hadoop: The Definitive Guide, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

