Performing GROUP BY using MapReduce
This recipe shows how we can use MapReduce to group data into simple groups and calculate metrics for each group. We will use the web server's log dataset for this recipe as well. This computation is similar to the select page, count(*) from weblog_table group by page SQL statement. The following figure shows the execution flow of this computation:
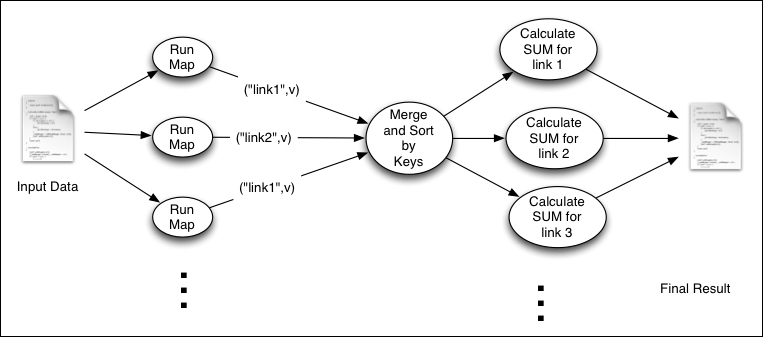
As shown in the figure, the Map tasks emit the requested URL path as the key. Then, Hadoop sorts and groups the intermediate data by the key. All values for a given key will be provided into a single Reduce function invocation, which will count the number of occurrences ...
Get Hadoop MapReduce v2 Cookbook - Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

