Creating the solution outline
Let's start by diving straight into the solution right now. Our goal is to do the following things step by step:
- Loading data into HDFS using batch mode: Flume.
- Loading data into HDFS using streaming mode: Kafka.
- Data analysis using Hive.
- Data visualization using Grafana and Open TSDB.
The following is an architecture diagram for the solution:
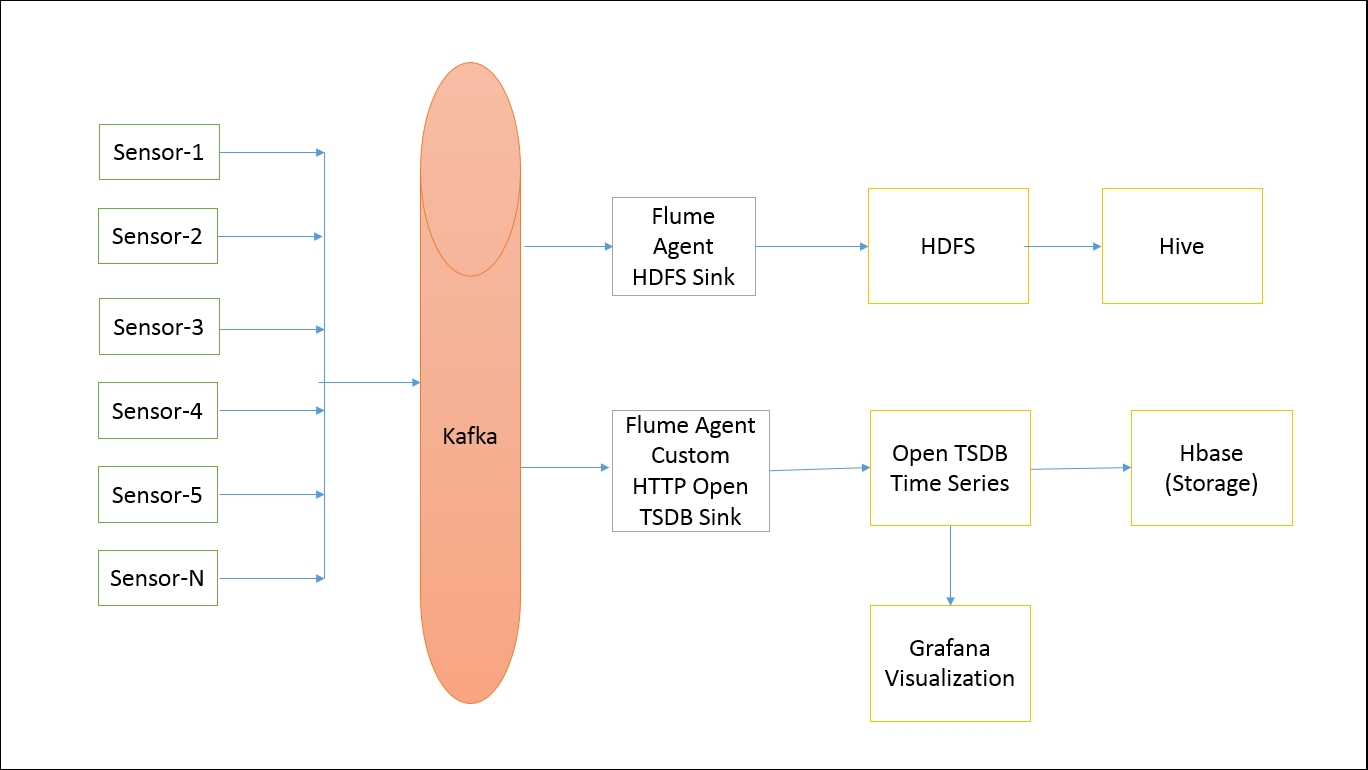
This architecture takes care of both real-time and batch analytics. We will be collecting data into Kafka topics. Then we will be using Flume agents to write this data to HDFS as well as to Open TSDB. Open TSDB is an open source time series database that uses HBase as its storage ...
Get Hadoop Blueprints now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

