Chapter 1. Introduction
Although much of this book talks about graph data models, it is not a book about graph theory.[2] We don’t need much theory to take advantage of graph databases: provided we understand what a graph is, we’re practically there. With that in mind, let’s refresh our memories about graphs in general.
What Is a Graph?
Formally, a graph is just a collection of vertices and edges—or, in less intimidating language, a set of nodes and the relationships that connect them. Graphs represent entities as nodes and the ways in which those entities relate to the world as relationships. This general-purpose, expressive structure allows us to model all kinds of scenarios, from the construction of a space rocket, to a system of roads, and from the supply-chain or provenance of foodstuff, to medical history for populations, and beyond.
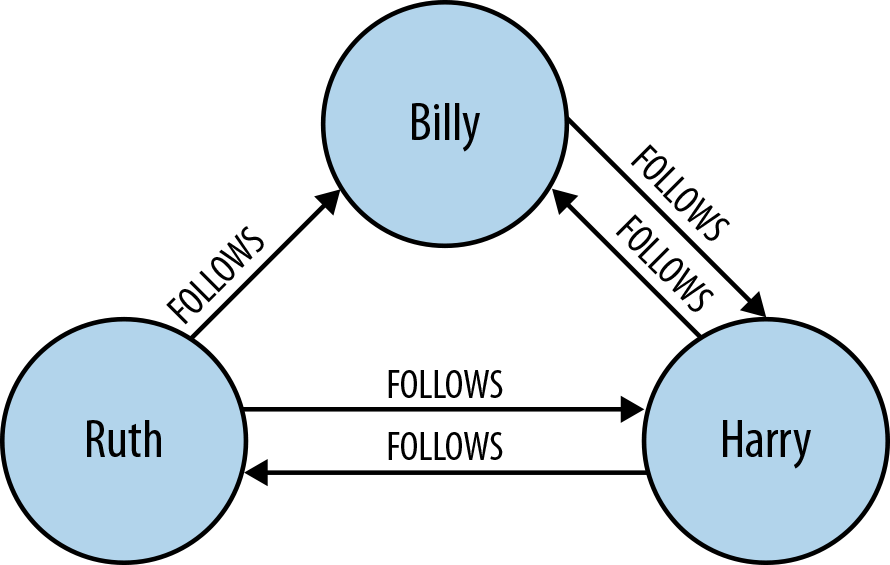
For example, Twitter’s data is easily represented as a graph. In Figure 1-1 we see a small network of followers. The relationships are key here in establishing the semantic context: namely, that Billy follows Harry, and that Harry, in turn, follows Billy. Ruth and Harry likewise follow each other, but sadly, although Ruth follows Billy, Billy hasn’t (yet) reciprocated.
Of course, Twitter’s real graph is hundreds of millions of times larger than the example in Figure 1-1, but it works on precisely the same principles. In Figure 1-2 we’ve expanded the graph to include the messages published by Ruth.
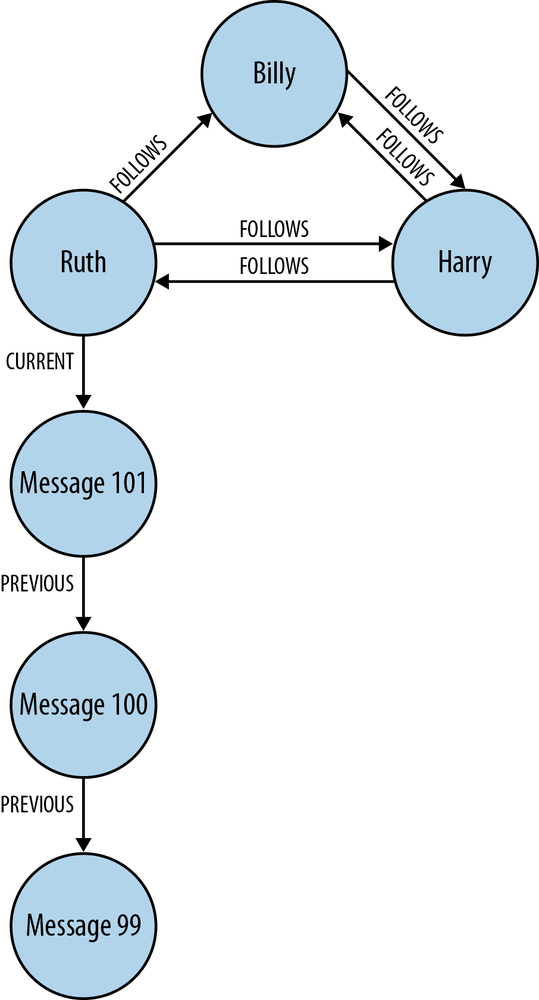
Though simple, Figure 1-2 shows the expressive power of the graph model. It’s easy to see that Ruth has published a string of messages. The most recent message can be found by following a relationship marked CURRENT; PREVIOUS relationships then create a time line of posts.
A High-Level View of the Graph Space
Numerous projects and products for managing, processing, and analyzing graphs have exploded onto the scene in recent years. The sheer number of technologies makes it difficult to keep track of these tools and how they differ, even for those of us who are active in the space. This section provides a high-level framework for making sense of the emerging graph landscape.
From 10,000 feet we can divide the graph space into two parts:
- Technologies used primarily for transactional online graph persistence, typically accessed directly in real time from an application
- These technologies are called graph databases and are the main focus of this book. They are the equivalent of “normal” online transactional processing (OLTP) databases in the relational world.
- Technologies used primarily for offline graph analytics, typically performed as a series of batch steps
- These technologies can be called graph compute engines. They can be thought of as being in the same category as other technologies for analysis of data in bulk, such as data mining and online analytical processing (OLAP).
Note
Another way to slice the graph space is to look at the graph models employed by the various technologies. There are three dominant graph data models: the property graph, Resource Description Framework (RDF) triples, and hypergraphs. We describe these in detail in Appendix A. Most of the popular graph databases on the market use the property graph model, and in consequence, it’s the model we’ll use throughout the remainder of this book.
Graph Databases
A graph database management system (henceforth, a graph database) is an online database management system with Create, Read, Update, and Delete (CRUD) methods that expose a graph data model. Graph databases are generally built for use with transactional (OLTP) systems. Accordingly, they are normally optimized for transactional performance, and engineered with transactional integrity and operational availability in mind.
There are two properties of graph databases you should consider when investigating graph database technologies:
- The underlying storage
- Some graph databases use native graph storage that is optimized and designed for storing and managing graphs. Not all graph database technologies use native graph storage, however. Some serialize the graph data into a relational database, an object-oriented database, or some other general-purpose data store.
- The processing engine
- Some definitions require that a graph database use index-free adjacency, meaning that connected nodes physically “point” to each other in the database.[3] Here we take a slightly broader view: any database that from the user’s perspective behaves like a graph database (i.e., exposes a graph data model through CRUD operations) qualifies as a graph database. We do acknowledge, however, the significant performance advantages of index-free adjacency, and therefore use the term native graph processing to describe graph databases that leverage index-free adjacency.
Note
It’s important to note that native graph storage and native graph processing are neither good nor bad—they’re simply classic engineering trade-offs. The benefit of native graph storage is that its purpose-built stack is engineered for performance and scalability. The benefit of nonnative graph storage, in contrast, is that it typically depends on a mature nongraph backend (such as MySQL) whose production characteristics are well understood by operations teams. Native graph processing (index-free adjacency) benefits traversal performance, but at the expense of making some nontraversal queries difficult or memory intensive.
Relationships are first-class citizens of the graph data model, unlike other database management systems, which require us to infer connections between entities using contrived properties such as foreign keys, or out-of-band processing like map-reduce. By assembling the simple abstractions of nodes and relationships into connected structures, graph databases enable us to build arbitrarily sophisticated models that map closely to our problem domain. The resulting models are simpler and at the same time more expressive than those produced using traditional relational databases and the other NOSQL stores.
Figure 1-3 shows a pictorial overview of some of the graph databases on the market today based on their storage and processing models.
Graph Compute Engines
A graph compute engine is a technology that enables global graph computational algorithms to be run against large datasets. Graph compute engines are designed to do things like identify clusters in your data, or answer questions such as, “how many relationships, on average, does everyone in a social network have?”
Because of their emphasis on global queries, graph compute engines are normally optimized for scanning and processing large amounts of information in batch, and in that respect they are similar to other batch analysis technologies, such as data mining and OLAP, that are familiar in the relational world. Whereas some graph compute engines include a graph storage layer, others (and arguably most) concern themselves strictly with processing data that is fed in from an external source, and returning the results.
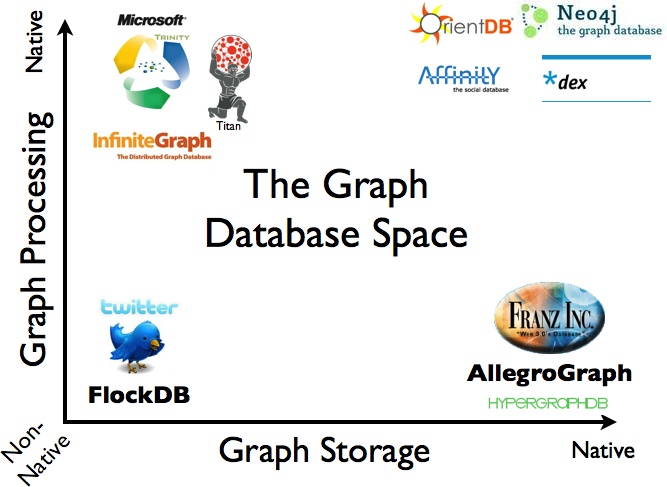
Figure 1-4 shows a common architecture for deploying a graph compute engine. The architecture includes a system of record (SOR) database with OLTP properties (such as MySQL, Oracle, or Neo4j), which serves, requests, and responds to queries from the application (and ultimately the users) at runtime. Periodically, an Extract, Transform, and Load (ETL) job moves data from the system of record database into the graph compute engine for offline querying and analysis.

A variety of different types of graph compute engines exist. Most notably there are in-memory/single machine graph compute engines like Cassovary, and distributed graph compute engines like Pegasus or Giraph. Most distributed graph compute engines are based on the Pregel white paper, authored by Google, which describes the graph compute engine Google uses to rank pages.
The Power of Graph Databases
Notwithstanding the fact that just about anything can be modeled as a graph, we live in a pragmatic world of budgets, project time lines, corporate standards, and commoditized skillsets. That a graph database provides a powerful but novel data modeling technique does not in itself provide sufficient justification for replacing a well-established, well-understood data platform; there must also be an immediate and very significant practical benefit. In the case of graph databases, this motivation exists in the form of a set of use cases and data patterns whose performance improves by one or more orders of magnitude when implemented in a graph, and whose latency is much lower compared to batch processing of aggregates. On top of this performance benefit, graph databases offer an extremely flexible data model, and a mode of delivery aligned with today’s agile software delivery practices.
Performance
One compelling reason, then, for choosing a graph database is the sheer performance increase when dealing with connected data versus relational databases and NOSQL stores. In contrast to relational databases, where join-intensive query performance deteriorates as the dataset gets bigger, with a graph database performance tends to remain relatively constant, even as the dataset grows. This is because queries are localized to a portion of the graph. As a result, the execution time for each query is proportional only to the size of the part of the graph traversed to satisfy that query, rather than the size of the overall graph.
Flexibility
As developers and data architects we want to connect data as the domain dictates, thereby allowing structure and schema to emerge in tandem with our growing understanding of the problem space, rather than being imposed upfront, when we know least about the real shape and intricacies of the data. Graph databases address this want directly. As we show in Chapter 3, the graph data model expresses and accommodates business needs in a way that enables IT to move at the speed of business.
Graphs are naturally additive, meaning we can add new kinds of relationships, new nodes, and new subgraphs to an existing structure without disturbing existing queries and application functionality. These things have generally positive implications for developer productivity and project risk. Because of the graph model’s flexibility, we don’t have to model our domain in exhaustive detail ahead of time—a practice that is all but foolhardy in the face of changing business requirements. The additive nature of graphs also means we tend to perform fewer migrations, thereby reducing maintenance overhead and risk.
Agility
We want to be able to evolve our data model in step with the rest of our application, using a technology aligned with today’s incremental and iterative software delivery practices. Modern graph databases equip us to perform frictionless development and graceful systems maintenance. In particular, the schema-free nature of the graph data model, coupled with the testable nature of a graph database’s application programming interface (API) and query language, empower us to evolve an application in a controlled manner.
At the same time, precisely because they are schema free, graph databases lack the kind of schema-oriented data governance mechanisms we’re familiar with in the relational world. But this is not a risk; rather, it calls forth a far more visible and actionable kind of governance. As we show in Chapter 4, governance is typically applied in a programmatic fashion, using tests to drive out the data model and queries, as well as assert the business rules that depend upon the graph. This is no longer a controversial practice: more so than relational development, graph database development aligns well with today’s agile and test-driven software development practices, allowing graph database–backed applications to evolve in step with changing business environments.
Summary
In this chapter we’ve reviewed the graph property model, a simple yet expressive tool for representing connected data. Property graphs capture complex domains in an expressive and flexible fashion, while graph databases make it easy to develop applications that manipulate our graph models.
In the next chapter we’ll look in more detail at how several different technologies address the challenge of connected data, starting with relational databases, moving onto aggregate NOSQL stores, and ending with graph databases. In the course of the discussion, we’ll see why graphs and graph databases provide the best means for modeling, storing, and querying connected data. Later chapters then go on to show how to design and implement a graph database–based solution.
[2] For introductions to graph theory, see Richard J. Trudeau, Introduction To Graph Theory (Dover, 1993) and Gary Chartrand, Introductory Graph Theory (Dover, 1985). For an excellent introduction to how graphs provide insight into complex events and behaviors, see David Easley and Jon Kleinberg, Networks, Crowds, and Markets: Reasoning about a Highly Connected World (Cambridge University Press, 2010).
[3] See Rodriguez, M.A., Neubauer, P., “The Graph Traversal Pattern,” 2010.
Get Graph Databases now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

