Chapter 4. How Do You Analyze Infinite Data Sets?
Infinite data sets raise important questions about how to do certain operations when you don’t have all the data and never will. In particular, what do classic SQL operations like GROUP BY and JOIN mean in this context?
A theory of streaming semantics is emerging to answer questions like these. Central to this theory is the idea that operations like GROUP BY and JOIN are now based on snapshots of the data available at points in time.
Apache Beam, formerly known as Google Dataflow, is perhaps the best-known mature streaming engine that offers a sophisticated formulation of these semantics. It has become the de facto standard for how precise analytics can be performed in real-world streaming scenarios. A third-party “runner” is required to execute Beam dataflows. In the open source world, teams are implementing this functionality for Flink, Gearpump, and Spark Streaming, while Google’s own runner is its cloud service, Cloud Dataflow. This means you will soon be able to write Beam dataflows and run them with these tools, or you will be able to use the native Flink, Gearpump, or Spark Streaming APIs to write dataflows with the same behaviors.
For space reasons, I can only provide a sketch of these semantics here, but two O’Reilly Radar blog posts by Tyler Akidau, a leader of the Beam/Dataflow team, cover them in depth.1 If you follow no other links in this report, at least read those blog posts!
Suppose we set out to build our own streaming engine. We might start by implementing two “modes” of processing, to cover a large fraction of possible scenarios: single-event processing and what I’ll call aggregation processing over many records, including summary statistics and GROUP BY, JOIN, and similar queries.
Single-event processing is the simplest case to support, where we process each event individually. We might trigger an alarm on an error event, or filter out events that aren’t interesting, or transform each event into a more useful format. All of these actions can be performed one event at a time. All of the low-latency tools discussed previously support this simple model.
The next level of sophistication is aggregations of events. Because the stream may be infinite, the simplest approach is to trigger a computation over a fixed-size window (usually limited by time, but possibly also by volume). For example, suppose I want to track clicks per page per minute. At the same time, I might want to segregate all those clicks into different files, one per minute. I collect the data coming in and at the end of each minute, I perform these tasks on the accumulated data, while the next minute’s data is being accumulated. This fixed-window approach is what Spark Streaming’s mini-batch model provides.2 It was a clever way to adapt Spark, which started life as a batch-mode tool, to provide a stream processing capability.
But the fixed-window model raises a problem. Time is a first-class concern in streaming. There is a difference between event time (when the event happened on the server where it happened), and processing time (the point in time later when the event was processed, probably on a different server). While processing time is easiest to handle, event time is usually more important for reconstructing reality, such as transaction sequences, anomalous activity, etc. Unfortunately, the fixed-window model I just described works with processing time.
Complicating the picture is the fact that times across different servers will never be completely aligned. If I’m trying to reconstruct a session—the sequence of events based on event times for activity that spans servers—I have to account for the inevitable clock skew between the servers.
One implication of the difference between event and processing time is the fact that I can’t really know that my processing system has received all of the events for a particular window of event time. Arrival delays could be significant, due to network delays or partitions, servers that crash and then reboot, mobile devices that leave and then rejoin the Internet, etc.
In the clicks per page per minute example, because of inevitable latencies, however small, the actual events in the mini-batch will include stragglers from the previous window of event time. For example, they might include very late events that were received after a network problem was corrected. Similarly, some events with event times in this window won’t arrive until the next mini-batch window, if not much later.
Figure 4-1 illustrates event vs. processing times.
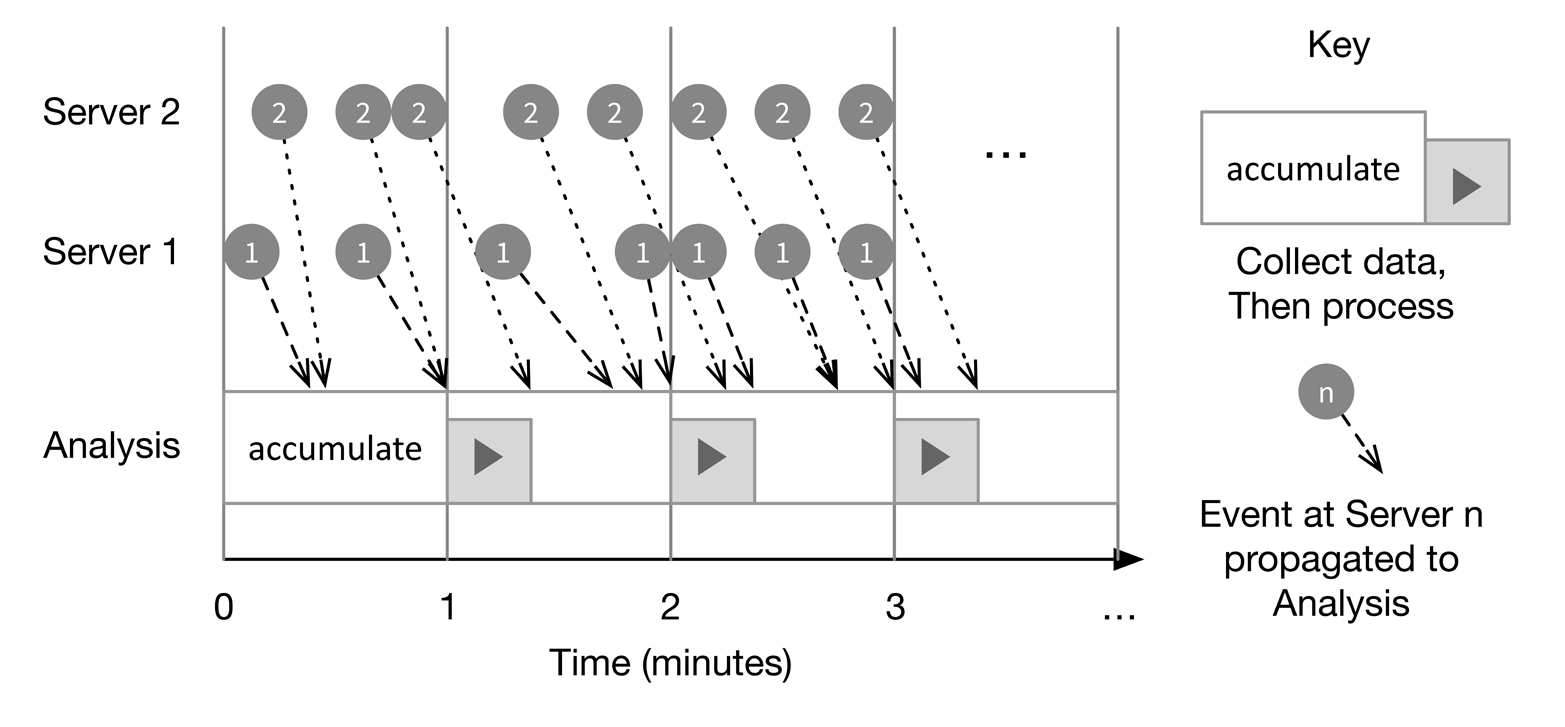
Figure 4-1. Event time vs. processing time
Events generated on Servers 1 and 2 at particular event times propagate to the Analysis server at different rates (shown exaggerated). While most events that occur in a particular one-minute interval arrive in the same interval, some arrive in the next interval. During each minute, events that arrive are accumulated. At minute boundaries, the analysis task for the previous minute’s events is invoked, but clearly some data will usually be missing.
So, I really need to process by event time, independent of the mini-batch processing times, to compute clicks per page per minute. However, if my persistent storage supports incremental updates, the second task I mentioned—segregating clicks by minute—is less problematic. When they aren’t within the same mini-batch interval, I can just append stragglers later.
This impacts correctness, too. For fast data architectures to truly supplant batch-mode architectures, they have to provide the same correctness guarantees. My clicks per page per minute calculation should have the same accuracy whether I do it incrementally over the event log or in a batch job over yesterday’s accumulated data.
I still need some sense of finite windows, because I can’t wait for an infinite stream to end. Therefore, I need to decide when to trigger processing. Three concepts help us refine what to do within windows:
-
Watermarks indicate that all events relative to a session or other “context” have been received, so it’s now safe to process the final result for the context.
-
Triggers are a more general tool for invoking processing, including the detection of watermarks, a timer firing, a threshold being reached, etc. They may result in computation of incomplete results for a given context, as more data may arrive later.
-
Accumulation modes encapsulate how we should treat multiple observations within the same window, whether they are disjoint or overlapping. If overlapping, do later observations override earlier ones or are they merged somehow?
Except for the case when we know we’ve seen everything for a context, we still need a plan for handling late-arriving events. One possibility is to structure our analysis so that we can always take a snapshot in time, then improve it as events arrive later. My dashboard might show results for clicks per page per minute for the last hour, but some of them might be updated as late events arrive and are processed. In a dashboard, it’s probably better to show provisional results sooner rather than later, as long as it’s clear to the viewer that the results aren’t final.
However, suppose instead that these point-in-time analytics are written to yet another stream of data that feeds a billing system. Simply overwriting a previous value isn’t an option. Accountants never modify an entry in their bookkeeping; instead, they add a correction entry later to fix earlier mistakes. Similarly, my streaming tools need to support retractions, followed by new values.
We’ve just scratched the surface of the important considerations required for processing infinite streams in a timely fashion, yet preserving correctness, robustness, and durability.
Now that you understand some of the important concepts required for effective stream processing, let’s examine several of the currently available options and how they support these concepts.
Which Streaming Engine(s) Should You Use?
How do the low-latency and mini-batch engines available today stand up? Which ones should you use?
While Spark Streaming version 1.x was limited to mini-batch intervals based on processing time, Structured Streaming in Spark version 2.0 starts the evolution toward a low-latency streaming engine with full support for the semantics just discussed. Spark 2.0 still uses mini-batches internally, but features like event-time support have been added. A major goal of the Spark project is to promote so-called continuous applications, where the division between batch and stream processing is further reduced. The project also wants to simplify common scenarios where other services integrate with streaming data.
Today, Spark Streaming offers the benefit of enabling very rich, very scalable, and resource-intensive processing, like training machine learning models, when the longer latencies of mini-batches are tolerable.
Flink and Gearpump are the two most prominent open source tools that are aggressively pursuing the ability to run Beam dataflows. Flink is better known, while Gearpump is better integrated with Akka and Akka Streams. For example, Gearpump can materialize Akka Streams (analogous to being a Beam runner) in a distributed configuration not natively supported by Akka. Cloudera is leading an effort to add Beam support to Spark’s Structured Streaming as well.
Kafka Streams and Akka Streams are designed for the sweet spot of building microservices that process data asynchronously, versus a focus on data analytics. Both provide single-event processing with very low latency and high throughput, as well as some aggregation processing, like grouping and joins. Akka and Akka Streams are also very good for implementing complex event processing (CEP) scenarios, such as lifecycle state transitions, alarm triggering off certain events, etc. Kafka Streams runs as a library on top of the Kafka cluster, so it requires no additional cluster setup and minimal additional management overhead. Akka is part of the Lightbend Reactive Platform, which puts more emphasis on building microservices. Therefore, Akka Streams is a good choice when you are integrating a wide variety of other services with your data processing system.
The reason why I included so many tools in Figure 2-1 is because a real environment may need several of them. However, there’s enough overlap that you won’t need all of them. Indeed, you shouldn’t take on the management burden of using all of these tools. If you already use or plan to use Spark for interactive SQL queries, machine learning, and batch jobs, then Spark Streaming is a good choice that covers a wide class of problems and lets you share logic between streaming and batch applications.
If you need the sophisticated semantics and low latency provided by Beam, then use the Beam API with Flink or Gearpump as the runner, or use the Flink or Gearpump native API to define your dataflows directly. Even if you don’t (yet) need Beam semantics, if you are primarily doing stream processing and you don’t need the full spectrum of Spark features, consider using Flink or Gearpump instead of Spark.
Since we assume that Kafka is a given, use Kafka Streams for low-overhead processing that doesn’t require the sophistication or flexibility provided by the other tools. The management overhead is minimal, once Kafka is running. ETL tasks like filtering, transformation, and many aggregation tasks are ideal for Kafka Streams. Use it for Kafka-centric microservices that process asynchronous data streams.
Use Akka Streams to implement and integrate more general microservices and a wide variety of other tools and products, with flexible options for communication protocols besides REST, such as Aeron, and especially those that support the Reactive Streams specification, a new standard for asynchronous communications.3 Consider Gearpump as a materializer for Akka Streams for more deployment options. Akka Streams also supports the construction of complex graphs of streams for sophisticated dataflows. Other recommended uses include low-latency processing (similar to Kafka Streams) such as ETL filtering and transformation, alarm signaling, and two-way stateful sessions, such as interactions with IoT devices.
1 See “The World Beyond Batch: Streaming 101”, and “The World Beyond Batch: Streaming 102”.
2 I’m using “windows” and “batches” informally, glossing over the distinction that moving windows over a set of batches is also an important construct.
3 Reactive Streams is a protocol for dynamic flow control though backpressure that’s negotiated between the consumer and producer.
Get Fast Data Architectures for Streaming Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

