Process of analysis
We mentioned in Chapter 1, Introduction to Efficient Indexing and Chapter 2, What is an Elasticsearch Index that all Apache Lucene's data is stored in the inverted index. This means that the data is being transformed. The process of transforming data is called analysis. The analysis process relies on two basic pillars: tokenizing and normalizing.
The first step of the analysis process is to break the text into tokens using tokenizer after processing by the character filters for the inverted index. Then, it normalizes these tokens (that is, terms) to make them easily searchable.
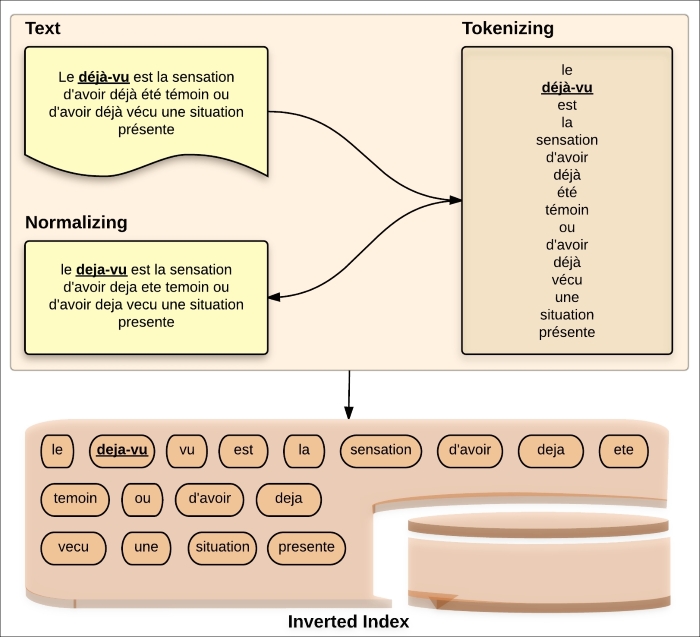
Inverted index processes are performed by analyzers. ...
Get Elasticsearch Indexing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

