Chapter 1. Introduction: What Is Data Science?
Over the past few years, there’s been a lot of hype in the media about “data science” and “Big Data.” A reasonable first reaction to all of this might be some combination of skepticism and confusion; indeed we, Cathy and Rachel, had that exact reaction.
And we let ourselves indulge in our bewilderment for a while, first separately, and then, once we met, together over many Wednesday morning breakfasts. But we couldn’t get rid of a nagging feeling that there was something real there, perhaps something deep and profound representing a paradigm shift in our culture around data. Perhaps, we considered, it’s even a paradigm shift that plays to our strengths. Instead of ignoring it, we decided to explore it more.
But before we go into that, let’s first delve into what struck us as confusing and vague—perhaps you’ve had similar inclinations. After that we’ll explain what made us get past our own concerns, to the point where Rachel created a course on data science at Columbia University, Cathy blogged the course, and you’re now reading a book based on it.
Big Data and Data Science Hype
Let’s get this out of the way right off the bat, because many of you are likely skeptical of data science already for many of the reasons we were. We want to address this up front to let you know: we’re right there with you. If you’re a skeptic too, it probably means you have something useful to contribute to making data science into a more legitimate field that has the power to have a positive impact on society.
So, what is eyebrow-raising about Big Data and data science? Let’s count the ways:
-
There’s a lack of definitions around the most basic terminology. What is “Big Data” anyway? What does “data science” mean? What is the relationship between Big Data and data science? Is data science the science of Big Data? Is data science only the stuff going on in companies like Google and Facebook and tech companies? Why do many people refer to Big Data as crossing disciplines (astronomy, finance, tech, etc.) and to data science as only taking place in tech? Just how big is big? Or is it just a relative term? These terms are so ambiguous, they’re well-nigh meaningless.
-
There’s a distinct lack of respect for the researchers in academia and industry labs who have been working on this kind of stuff for years, and whose work is based on decades (in some cases, centuries) of work by statisticians, computer scientists, mathematicians, engineers, and scientists of all types. From the way the media describes it, machine learning algorithms were just invented last week and data was never “big” until Google came along. This is simply not the case. Many of the methods and techniques we’re using—and the challenges we’re facing now—are part of the evolution of everything that’s come before. This doesn’t mean that there’s not new and exciting stuff going on, but we think it’s important to show some basic respect for everything that came before.
-
The hype is crazy—people throw around tired phrases straight out of the height of the pre-financial crisis era like “Masters of the Universe” to describe data scientists, and that doesn’t bode well. In general, hype masks reality and increases the noise-to-signal ratio. The longer the hype goes on, the more many of us will get turned off by it, and the harder it will be to see what’s good underneath it all, if anything.
-
Statisticians already feel that they are studying and working on the “Science of Data.” That’s their bread and butter. Maybe you, dear reader, are not a statistician and don’t care, but imagine that for the statistician, this feels a little bit like how identity theft might feel for you. Although we will make the case that data science is not just a rebranding of statistics or machine learning but rather a field unto itself, the media often describes data science in a way that makes it sound like as if it’s simply statistics or machine learning in the context of the tech industry.
-
People have said to us, “Anything that has to call itself a science isn’t.” Although there might be truth in there, that doesn’t mean that the term “data science” itself represents nothing, but of course what it represents may not be science but more of a craft.
Getting Past the Hype
Rachel’s experience going from getting a PhD in statistics to working at Google is a great example to illustrate why we thought, in spite of the aforementioned reasons to be dubious, there might be some meat in the data science sandwich. In her words:
It was clear to me pretty quickly that the stuff I was working on at Google was different than anything I had learned at school when I got my PhD in statistics. This is not to say that my degree was useless; far from it—what I’d learned in school provided a framework and way of thinking that I relied on daily, and much of the actual content provided a solid theoretical and practical foundation necessary to do my work.
But there were also many skills I had to acquire on the job at Google that I hadn’t learned in school. Of course, my experience is specific to me in the sense that I had a statistics background and picked up more computation, coding, and visualization skills, as well as domain expertise while at Google. Another person coming in as a computer scientist or a social scientist or a physicist would have different gaps and would fill them in accordingly. But what is important here is that, as individuals, we each had different strengths and gaps, yet we were able to solve problems by putting ourselves together into a data team well-suited to solve the data problems that came our way.
Here’s a reasonable response you might have to this story. It’s a general truism that, whenever you go from school to a real job, you realize there’s a gap between what you learned in school and what you do on the job. In other words, you were simply facing the difference between academic statistics and industry statistics.
We have a couple replies to this:
-
Sure, there’s is a difference between industry and academia. But does it really have to be that way? Why do many courses in school have to be so intrinsically out of touch with reality?
-
Even so, the gap doesn’t represent simply a difference between industry statistics and academic statistics. The general experience of data scientists is that, at their job, they have access to a larger body of knowledge and methodology, as well as a process, which we now define as the data science process (details in Chapter 2), that has foundations in both statistics and computer science.
Around all the hype, in other words, there is a ring of truth: this is something new. But at the same time, it’s a fragile, nascent idea at real risk of being rejected prematurely. For one thing, it’s being paraded around as a magic bullet, raising unrealistic expectations that will surely be disappointed.
Rachel gave herself the task of understanding the cultural phenomenon of data science and how others were experiencing it. She started meeting with people at Google, at startups and tech companies, and at universities, mostly from within statistics departments.
From those meetings she started to form a clearer picture of the new thing that’s emerging. She ultimately decided to continue the investigation by giving a course at Columbia called “Introduction to Data Science,” which Cathy covered on her blog. We figured that by the end of the semester, we, and hopefully the students, would know what all this actually meant. And now, with this book, we hope to do the same for many more people.
Why Now?
We have massive amounts of data about many aspects of our lives, and, simultaneously, an abundance of inexpensive computing power. Shopping, communicating, reading news, listening to music, searching for information, expressing our opinions—all this is being tracked online, as most people know.
What people might not know is that the “datafication” of our offline behavior has started as well, mirroring the online data collection revolution (more on this later). Put the two together, and there’s a lot to learn about our behavior and, by extension, who we are as a species.
It’s not just Internet data, though—it’s finance, the medical industry, pharmaceuticals, bioinformatics, social welfare, government, education, retail, and the list goes on. There is a growing influence of data in most sectors and most industries. In some cases, the amount of data collected might be enough to be considered “big” (more on this in the next chapter); in other cases, it’s not.
But it’s not only the massiveness that makes all this new data interesting (or poses challenges). It’s that the data itself, often in real time, becomes the building blocks of data products. On the Internet, this means Amazon recommendation systems, friend recommendations on Facebook, film and music recommendations, and so on. In finance, this means credit ratings, trading algorithms, and models. In education, this is starting to mean dynamic personalized learning and assessments coming out of places like Knewton and Khan Academy. In government, this means policies based on data.
We’re witnessing the beginning of a massive, culturally saturated feedback loop where our behavior changes the product and the product changes our behavior. Technology makes this possible: infrastructure for large-scale data processing, increased memory, and bandwidth, as well as a cultural acceptance of technology in the fabric of our lives. This wasn’t true a decade ago.
Considering the impact of this feedback loop, we should start thinking seriously about how it’s being conducted, along with the ethical and technical responsibilities for the people responsible for the process. One goal of this book is a first stab at that conversation.
Datafication
In the May/June 2013 issue of Foreign Affairs, Kenneth Neil Cukier and Viktor Mayer-Schoenberger wrote an article called “The Rise of Big Data”. In it they discuss the concept of datafication, and their example is how we quantify friendships with “likes”: it’s the way everything we do, online or otherwise, ends up recorded for later examination in someone’s data storage units. Or maybe multiple storage units, and maybe also for sale.
They define datafication as a process of “taking all aspects of life and turning them into data.” As examples, they mention that “Google’s augmented-reality glasses datafy the gaze. Twitter datafies stray thoughts. LinkedIn datafies professional networks.”
Datafication is an interesting concept and led us to consider its importance with respect to people’s intentions about sharing their own data. We are being datafied, or rather our actions are, and when we “like” someone or something online, we are intending to be datafied, or at least we should expect to be. But when we merely browse the Web, we are unintentionally, or at least passively, being datafied through cookies that we might or might not be aware of. And when we walk around in a store, or even on the street, we are being datafied in a completely unintentional way, via sensors, cameras, or Google glasses.
This spectrum of intentionality ranges from us gleefully taking part in a social media experiment we are proud of, to all-out surveillance and stalking. But it’s all datafication. Our intentions may run the gamut, but the results don’t.
They follow up their definition in the article with a line that speaks volumes about their perspective:
Once we datafy things, we can transform their purpose and turn the information into new forms of value.
Here’s an important question that we will come back to throughout the book: who is “we” in that case? What kinds of value do they refer to? Mostly, given their examples, the “we” is the modelers and entrepreneurs making money from getting people to buy stuff, and the “value” translates into something like increased efficiency through automation.
If we want to think bigger, if we want our “we” to refer to people in general, we’ll be swimming against the tide.
The Current Landscape (with a Little History)
So, what is data science? Is it new, or is it just statistics or analytics rebranded? Is it real, or is it pure hype? And if it’s new and if it’s real, what does that mean?
This is an ongoing discussion, but one way to understand what’s going on in this industry is to look online and see what current discussions are taking place. This doesn’t necessarily tell us what data science is, but it at least tells us what other people think it is, or how they’re perceiving it. For example, on Quora there’s a discussion from 2010 about “What is Data Science?” and here’s Metamarket CEO Mike Driscoll’s answer:
Data science, as it’s practiced, is a blend of Red-Bull-fueled hacking and espresso-inspired statistics.
But data science is not merely hacking—because when hackers finish debugging their Bash one-liners and Pig scripts, few of them care about non-Euclidean distance metrics.
And data science is not merely statistics, because when statisticians finish theorizing the perfect model, few could read a tab-delimited file into R if their job depended on it.
Data science is the civil engineering of data. Its acolytes possess a practical knowledge of tools and materials, coupled with a theoretical understanding of what’s possible.
Driscoll then refers to Drew Conway’s Venn diagram of data science from 2010, shown in Figure 1-1.
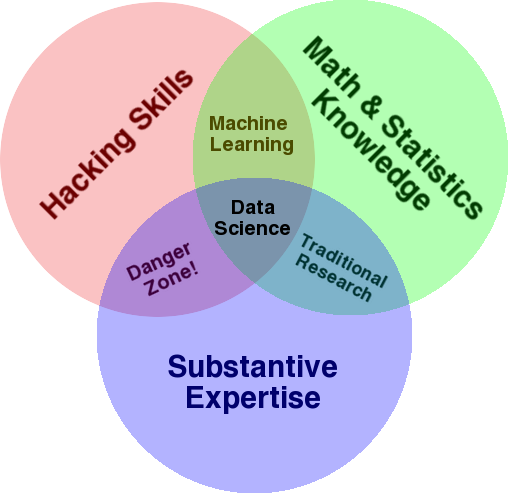
Figure 1-1. Drew Conway’s Venn diagram of data science
He also mentions the sexy skills of data geeks from Nathan Yau’s 2009 post, “Rise of the Data Scientist”, which include:
But wait, is data science just a bag of tricks? Or is it the logical extension of other fields like statistics and machine learning?
For one argument, see Cosma Shalizi’s posts here and here, and Cathy’s posts here and here, which constitute an ongoing discussion of the difference between a statistician and a data scientist. Cosma basically argues that any statistics department worth its salt does all the stuff in the descriptions of data science that he sees, and therefore data science is just a rebranding and unwelcome takeover of statistics.
For a slightly different perspective, see ASA President Nancy Geller’s 2011 Amstat News article, “Don’t shun the ‘S’ word”, in which she defends statistics:
We need to tell people that Statisticians are the ones who make sense of the data deluge occurring in science, engineering, and medicine; that statistics provides methods for data analysis in all fields, from art history to zoology; that it is exciting to be a Statistician in the 21st century because of the many challenges brought about by the data explosion in all of these fields.
Though we get her point—the phrase “art history to zoology” is supposed to represent the concept of A to Z—she’s kind of shooting herself in the foot with these examples because they don’t correspond to the high-tech world where much of the data explosion is coming from. Much of the development of the field is happening in industry, not academia. That is, there are people with the job title data scientist in companies, but no professors of data science in academia. (Though this may be changing.)
Not long ago, DJ Patil described how he and Jeff Hammerbacher—then at LinkedIn and Facebook, respectively—coined the term “data scientist” in 2008. So that is when “data scientist” emerged as a job title. (Wikipedia finally gained an entry on data science in 2012.)
It makes sense to us that once the skill set required to thrive at Google—working with a team on problems that required a hybrid skill set of stats and computer science paired with personal characteristics including curiosity and persistence—spread to other Silicon Valley tech companies, it required a new job title. Once it became a pattern, it deserved a name. And once it got a name, everyone and their mother wanted to be one. It got even worse when Harvard Business Review declared data scientist to be the “Sexiest Job of the 21st Century”.
But we can go back even further. In 2001, William Cleveland wrote a position paper about data science called “Data Science: An action plan to expand the field of statistics.”
So data science existed before data scientists? Is this semantics, or does it make sense?
This all begs a few questions: can you define data science by what data scientists do? Who gets to define the field, anyway? There’s lots of buzz and hype—does the media get to define it, or should we rely on the practitioners, the self-appointed data scientists? Or is there some actual authority? Let’s leave these as open questions for now, though we will return to them throughout the book.
Data Science Jobs
Columbia just decided to start an Institute for Data Sciences and Engineering with Bloomberg’s help. There are 465 job openings in New York City alone for data scientists last time we checked. That’s a lot. So even if data science isn’t a real field, it has real jobs.
And here’s one thing we noticed about most of the job descriptions: they ask data scientists to be experts in computer science, statistics, communication, data visualization, and to have extensive domain expertise. Nobody is an expert in everything, which is why it makes more sense to create teams of people who have different profiles and different expertise—together, as a team, they can specialize in all those things. We’ll talk about this more after we look at the composite set of skills in demand for today’s data scientists.
A Data Science Profile
In the class, Rachel handed out index cards and asked everyone to profile themselves (on a relative rather than absolute scale) with respect to their skill levels in the following domains:
-
Computer science
-
Math
-
Statistics
-
Machine learning
-
Domain expertise
-
Communication and presentation skills
-
Data visualization
As an example, Figure 1-2 shows Rachel’s data science profile.
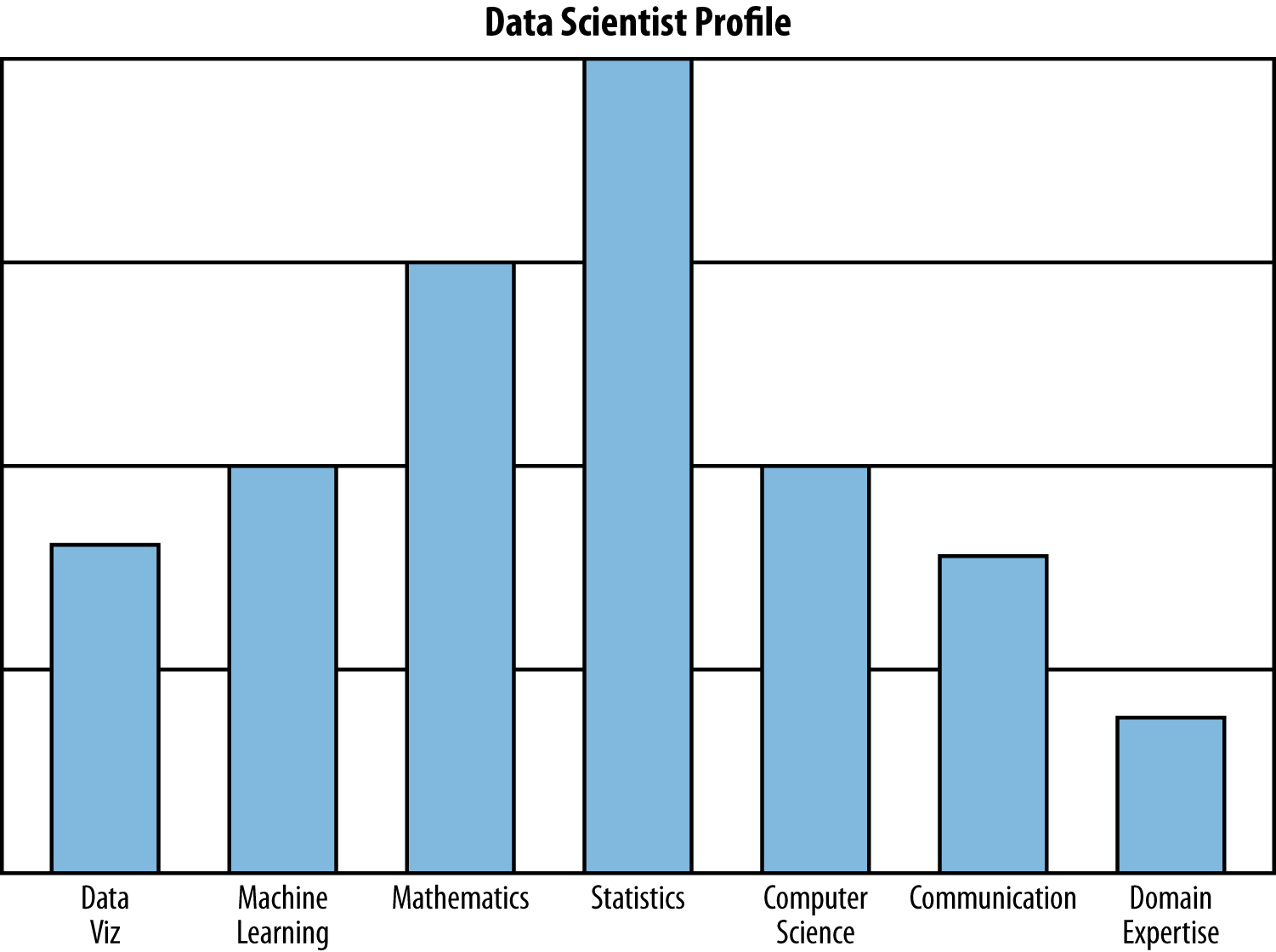
Figure 1-2. Rachel’s data science profile, which she created to illustrate trying to visualize oneself as a data scientist; she wanted students and guest lecturers to “riff” on this—to add buckets or remove skills, use a different scale or visualization method, and think about the drawbacks of self-reporting
We taped the index cards to the blackboard and got to see how everyone else thought of themselves. There was quite a bit of variation, which is cool—lots of people in the class were coming from social sciences, for example.
Where is your data science profile at the moment, and where would you like it to be in a few months, or years?
As we mentioned earlier, a data science team works best when different skills (profiles) are represented across different people, because nobody is good at everything. It makes us wonder if it might be more worthwhile to define a “data science team”—as shown in Figure 1-3—than to define a data scientist.
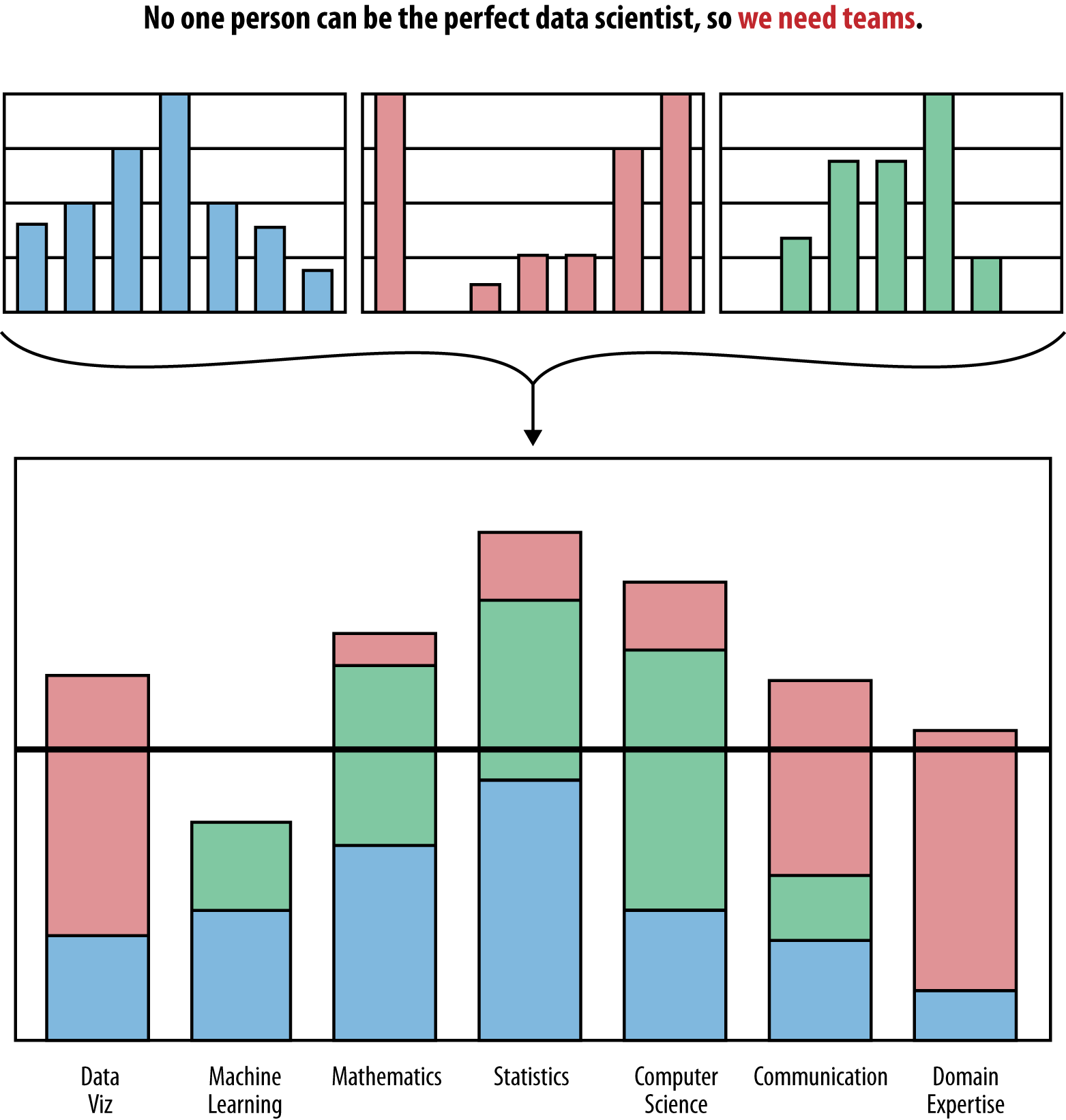
Figure 1-3. Data science team profiles can be constructed from data scientist profiles; there should be alignment between the data science team profile and the profile of the data problems they try to solve
Thought Experiment: Meta-Definition
Every class had at least one thought experiment that the students discussed in groups. Most of the thought experiments were very open-ended, and the intention was to provoke discussion about a wide variety of topics related to data science. For the first class, the initial thought experiment was: can we use data science to define data science?
The class broke into small groups to think about and discuss this question. Here are a few interesting things that emerged from those conversations:
- Start with a text-mining model.
-
We could do a Google search for “data science” and perform a text-mining model. But that would depend on us being a usagist rather than a prescriptionist with respect to language. A usagist would let the masses define data science (where “the masses” refers to whatever Google’s search engine finds). Would it be better to be a prescriptionist and refer to an authority such as the Oxford English Dictionary? Unfortunately, the OED probably doesn’t have an entry yet, and we don’t have time to wait for it. Let’s agree that there’s a spectrum, that one authority doesn’t feel right, and that “the masses” doesn’t either.
- So what about a clustering algorithm?
-
How about we look at practitioners of data science and see how they describe what they do (maybe in a word cloud for starters)? Then we can look at how people who claim to be other things like statisticians or physicists or economists describe what they do. From there, we can try to use a clustering algorithm (which we’ll use in Chapter 3) or some other model and see if, when it gets as input “the stuff someone does,” it gives a good prediction on what field that person is in.
Just for comparison, check out what Harlan Harris recently did related to the field of data science: he took a survey and used clustering to define subfields of data science, which gave rise to Figure 1-4.
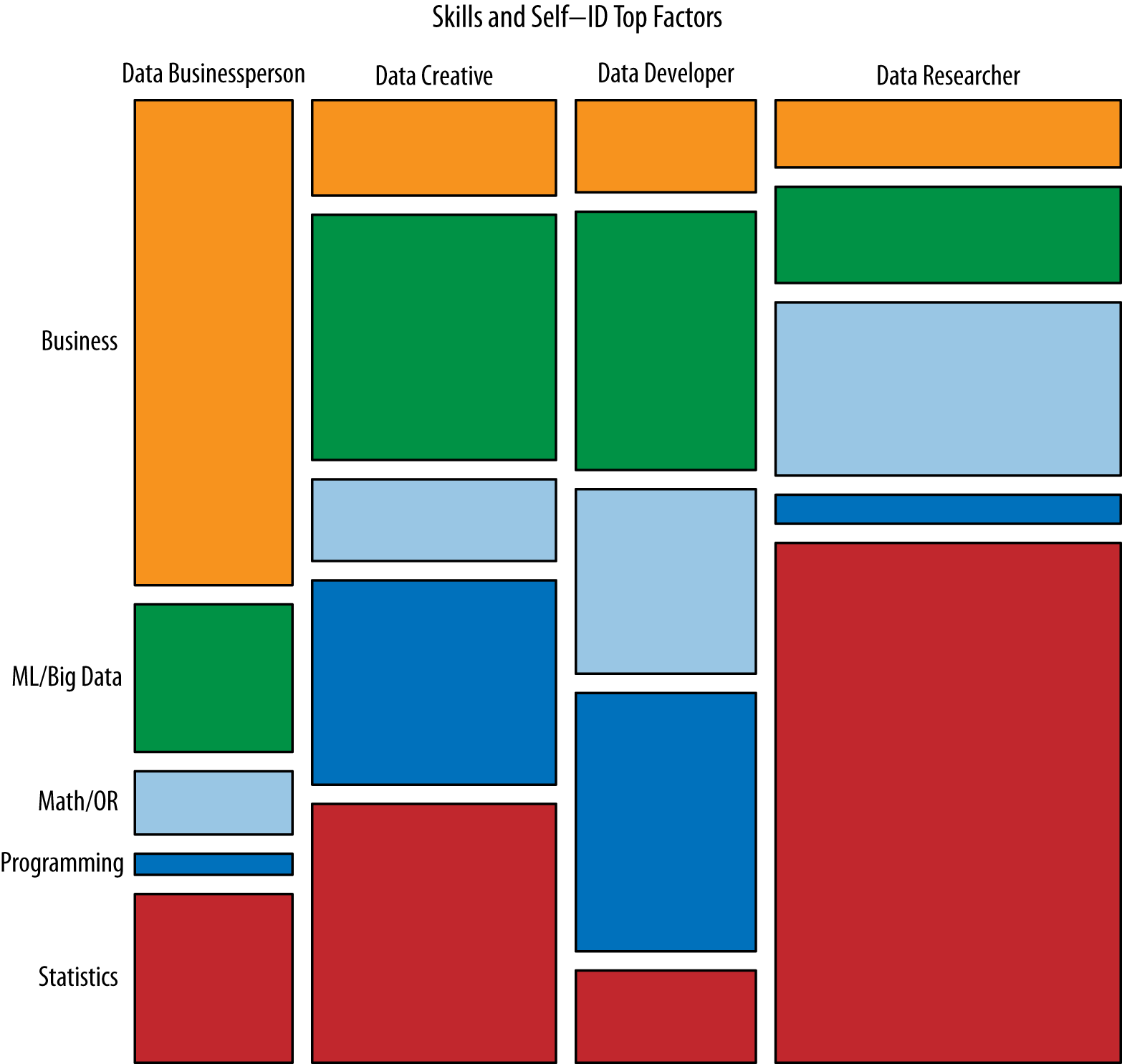
Figure 1-4. Harlan Harris’s clustering and visualization of subfields of data science from Analyzing the Analyzers (O’Reilly) by Harlan Harris, Sean Murphy, and Marck Vaisman based on a survey of several hundred data science practitioners in mid-2012
OK, So What Is a Data Scientist, Really?
Perhaps the most concrete approach is to define data science is by its usage—e.g., what data scientists get paid to do. With that as motivation, we’ll describe what data scientists do. And we’ll cheat a bit by talking first about data scientists in academia.
In Academia
The reality is that currently, no one calls themselves a data scientist in academia, except to take on a secondary title for the sake of being a part of a “data science institute” at a university, or for applying for a grant that supplies money for data science research.
Instead, let’s ask a related question: who in academia plans to become a data scientist? There were 60 students in the Intro to Data Science class at Columbia. When Rachel proposed the course, she assumed the makeup of the students would mainly be statisticians, applied mathematicians, and computer scientists. Actually, though, it ended up being those people plus sociologists, journalists, political scientists, biomedical informatics students, students from NYC government agencies and nonprofits related to social welfare, someone from the architecture school, others from environmental engineering, pure mathematicians, business marketing students, and students who already worked as data scientists. They were all interested in figuring out ways to solve important problems, often of social value, with data.
For the term “data science” to catch on in academia at the level of the faculty, and as a primary title, the research area needs to be more formally defined. Note there is already a rich set of problems that could translate into many PhD theses.
Here’s a stab at what this could look like: an academic data scientist is a scientist, trained in anything from social science to biology, who works with large amounts of data, and must grapple with computational problems posed by the structure, size, messiness, and the complexity and nature of the data, while simultaneously solving a real-world problem.
The case for articulating it like this is as follows: across academic disciplines, the computational and deep data problems have major commonalities. If researchers across departments join forces, they can solve multiple real-world problems from different domains.
In Industry
What do data scientists look like in industry? It depends on the level of seniority and whether you’re talking about the Internet/online industry in particular. The role of data scientist need not be exclusive to the tech world, but that’s where the term originated; so for the purposes of the conversation, let us say what it means there.
A chief data scientist should be setting the data strategy of the company, which involves a variety of things: setting everything up from the engineering and infrastructure for collecting data and logging, to privacy concerns, to deciding what data will be user-facing, how data is going to be used to make decisions, and how it’s going to be built back into the product. She should manage a team of engineers, scientists, and analysts and should communicate with leadership across the company, including the CEO, CTO, and product leadership. She’ll also be concerned with patenting innovative solutions and setting research goals.
More generally, a data scientist is someone who knows how to extract meaning from and interpret data, which requires both tools and methods from statistics and machine learning, as well as being human. She spends a lot of time in the process of collecting, cleaning, and munging data, because data is never clean. This process requires persistence, statistics, and software engineering skills—skills that are also necessary for understanding biases in the data, and for debugging logging output from code.
Once she gets the data into shape, a crucial part is exploratory data analysis, which combines visualization and data sense. She’ll find patterns, build models, and algorithms—some with the intention of understanding product usage and the overall health of the product, and others to serve as prototypes that ultimately get baked back into the product. She may design experiments, and she is a critical part of data-driven decision making. She’ll communicate with team members, engineers, and leadership in clear language and with data visualizations so that even if her colleagues are not immersed in the data themselves, they will understand the implications.
That’s the high-level picture, and this book is about helping you understand the vast majority of it. We’re done with talking about data science; let’s go ahead and do some!
Get Doing Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

