Chapter 4. The Reservoir of Data
The Actual Internet
We wouldn’t be talking about big data at all if it weren’t for the “explosion” of the internet. Several technologies that were drifting around in the 1980s eventually converged to make the first boom possible. Mainstream consumer culture experienced it as if the boom came from nowhere. Since the 1990s, the internet has taken a few more evolutionary steps.
Running a business or computing plant at global scale had never been done before Yahoo! and then Google and Facebook attempted it. They encountered and solved many engineering and organizational problems while taking commercial supercomputing from enterprise scale to global scale. But as Yahoo! has since demonstrated, making a sustainably profitable business by computing at this intensity is a different matter.
Traditional enterprises (companies that make films, 737s, or soap) are for the first time experiencing global-scale computing problems, but they’re still stuck with their decades-old, entrenched approach to enterprise-scale computing. For those who remember what happened in the 1990s—or, more to the point, what didn’t happen—skepticism about the Miracle of Big Data is justified.
Taken from the perspective that early technologies (for example, Java, Apache, or anything involving billions of users) are always unproven, the first boom is always going to be wishful thinking. And there was a lot of wishful thinking going on in the 1990s.
Many startup companies built prototypes using early technologies like the programming language Java, which made it easier to quickly develop applications. If a startup’s idea caught on, then the problem of too many customers quickly overwhelmed the designers’ intentions. Good problem to have.
Building platforms to scale requires a lot of scaffolding “tax” up front, and although a startup might wish for too many customers, building a system from the get-go to handle millions of customers was expensive, complex, and optimistic even for Silicon Valley startups in the 1990s.
An application could be designed to quickly demonstrate that pet food could be purchased online, but demonstrating this for millions of pet owners would require the annoying platform-engineering bits to work, which rarely came into question during the seed stage or even later phases of funding. Startups with a good idea and a reasonable application could soon be crushed by their inability to scale.
Companies trying to design a killer app would be pressured to constantly tweak the design in an attempt to land millions of customers in one quarter. Core design requirements could reverse every few weeks, and this redesign whirlpool became inescapable. Very few companies survived.
Amazon is often cited as a survivor, and many of the original core architects who built Amazon came from Wal-Mart, which had built one of the first at-scale inventory management platforms on the planet. Wal-Mart did such an impressive job that they changed forever the rules of supply chains, inventory, and retail.
Startup companies that did not acquire a modest amount of platform engineering chops or could not constrain their instinct to “add one more thing” did not survive, despite having a viable business plan and several hundred thousand customers.
Best of Inbred
Platform engineering embodies the mantra “the whole is more than the sum of its parts” and can make up for many deficiencies in particular technologies. Components of a platform do not have to be mature or stable—that is the best-of-breed myth corresponding to the current silo view of enterprise engineering.
A best-of-breed platform does not require all components to be best of breed, nor will a platform assembled from best-of-breed technology necessarily be best of breed either. Best of breed is a concept introduced by the enterprise silo vendors; it’s often the product with the most brand strength in a given silo.
Best of breed is simply unaffordable at global scale. Building successful big data platforms can be done with a broader pedigree among components because the pedigree is dictated by scalability and affordability.
If architects can make a data center full of noSQL database engines meet the business requirements, then they can get by without the sophistication and expense of Oracle. This doesn’t mean MySQL can replace Oracle or that surgically deploying DB2 is off the table either. But if the platform needs to handle hundreds of millions of users affordably, the secret sauce is in the platform engineering, not in the aggregation of best-of-breed products.
Some enterprises have been living with and managing their big data for a long time. Healthcare companies have been trying to archive patient histories since they built their earliest databases. Some of these records live on legacy arrays and some are hibernating on tape reels.
In order to discover insights from legacy data, it must be accessible. Moving that data into a shiny new Hadoop cluster will require solving several platform-engineering problems that will make standing up that shiny new object look easy.
There’s so much pent up demand for big data because companies have been trying to do it for 20 years, but vendors couldn’t offer solutions that were affordable at scale. And because data lives everywhere, no single product or suite of products from any given vendor can really “solve” big data problems.
Even enterprises that attempted the one-stop-shop approach over the last decade have ended up with several, if not many, isolated or stranded sources of data. Customers now have data sources stranded on Greenplum, Netezza, and Exadata, and they risk stranding new sources on Cassandra, Mongo, and even Hadoop.
Like scientific supercomputing, commercial supercomputing cannot be solved using products from a single vendor. Big data consists of a broad spectrum of purpose-built workloads, but traditional business intelligence products are either too general-purpose to address this diverse spectrum or too purpose-built and can only address a narrow range of workloads.
Big data requires strange, new hybrid-platform products, but this will give software vendors fits because a well-designed, heterogeneous product that can be form-fitted to each enterprise’s very peculiar mosh pit of old and new data makes for a lousy SKU and a complicated story. Vendors don’t like complicated stories.
Drowning Not Waving
By the time you read this, big data may already be a cliché or routinely parodied on YouTube. For many enterprises, big data was a cruel and expensive joke 20 years ago. The data warehousing products created in the 1990s were outgrowths of major RDBMS vendors who got an early glimpse of the tsunami.
This first-generation technology was made possible due to advances in server technology. Hardware companies like DEC, HP, and IBM (prodded by startups like Pyramid, Sequent, and SGI) designed servers that were finally powerful enough to execute queries against a terabyte of data.
A small startup, Teradata, developed one of the first database kernels to handle queries against a TB of data. Established database companies like Informix, Oracle, and Sybase were soon chasing Teradata. Vendors who had spent years building kernels that were optimized for transaction processing needed to re-tool their kernels in order to handle queries that could process a thousand times as much data.
Some companies developed purpose-built kernels to handle a specific class of workloads (which was the point in time where big data really started). This early, difficult, clumsy, and expensive market has been called a lot of things over the years—decision support, OLAP, data warehouse, business intelligence (BI)—but even in the 1990s, it was important enough that the benchmark standards committee, TPC, defined a benchmark to help users qualify industry solutions.
To the extent that benchmarks ever help customers make purchasing decisions, these artificial workloads defined a generation of technology and capabilities. As successful as Teradata was at setting the bar for warehouse performance, it turned out to be a mom-and-pop, purpose-built business just like scientific supercomputing. After almost 20 years, Teradata is still a David against the Goliaths of IBM, Oracle, and EMC.
In commercial computing, the highly un-sexy applications for bookkeeping and widget tracking are where the money has always been. Yet, even the Goliaths will have difficulty dominating big data and high performance commercial computing for all the reasons scientific computing was never much of a growth business: purpose-built complex engineering, boutique revenues, and very pregnant sales cycles.
Big data is moving so fast relative to the clumsy old industry that standards bodies will find it difficult to define a general-purpose benchmark for a purpose-built world.
As soon as it was possible to extract, transform, and load (ETL) warehouse quantities of data, enterprises started drowning in it. Prior to the 1990s, data sources were abundant, but the high cost of storage still meant stashing much of it on tape. Tape technology has more lives than cats.
The simple reason tape is still viable today is due to its economics. Even as disk storage approaches $1/TB, tape remains a couple of orders of magnitude cheaper.
Big data starts to live up to its name not when enterprises have 10 petabytes in their cluster, but when they can afford to load 500 exabytes. In that world, tape will still be alive and well because the sensors from which the 500 exabytes originated will be producing 500 zettabytes/year.
Spinning Rust
Hennessey and Paterson have shown that processing technology has more or less tracked Moore’s Law, but memory and storage have not. In the early 2000s, the cost of memory started to fall in line with Moore’s Law since memory is a semiconductor, but storage technology remained mechanical.
The technology of disk drives today is not far removed from disk drives made in the 1980s. The landmark IBM Winchester was made from spinning platters of rust (oxidized particles) and flying magnetic heads, which is still true today for the drives found in a Hadoop cluster.
The recent emergence of flash as storage technology and Hadoop as a low-cost alternative to arrays of expensive disks will combine to produce its own form of disruption to that industry. A flash-based Hadoop cluster, for the first time, will be able to operate on a working set of problems at memory speeds. However, the economics of storing hundreds of petabytes will ensure both forms of spinning and spooling rust will be required by big data.
A Spectrum of Perishability
In the old silo world, enterprise data was mission critical, extremely valuable, and should never be lost, corrupted, or compromised. Most enterprise vendors have designed their products to be extremely persistent and in some cases, as with databases, coherently persistent. Today in the land that is flooded with too much data, not only is it too expensive to cherish every bit, it is often not necessary.
For the first time, enterprises can afford to crunch on an absurd amount of data for analysis, discovery, and insight. The price of admission is being able to stage 25 PB long enough for the crunch to occur. In many cases, even at $1/TB, keeping 25 PB around after the crunch will be impractical and some data must be tossed.
When petabytes become exabytes, exabytes become zettabytes, and zettabytes become yottabytes, then keeping tons of data after it has been crunched will not be an option.
Data lives on a spectrum of perishability that spans from seconds to decades. Data can be so transient that if analysis does not complete within an hour, the shelf life of the insight expires and the data must be deleted to make room for the next hour’s data.
Perishability puts the emphasis on insight, not retention. Historically, most enterprises have chosen to keep data for as long as possible and as cheaply as possible, but for big data, ideas and policies regarding the duration and cost of retention must be revaluated.
Everything lives on a spectrum of perishability: data, technology, and the business itself. Innovation drives the rapid expiration of all three.
Software vendors built warehouse products to run on dedicated hardware out of necessity to ensure their complex product would even work. If the vendor was IBM, these products typically ran on IBM hardware. If the vendor was Oracle, these products typically ran on hardware from one of Oracle’s hardware partners such as Dell, HP, or even IBM. Prescribing and packaging the hardware platform increased the odds of a successful deployment.
This trend in engineered systems looks like a platform-aware evolution, but it turns out to be more about vendor franchise management and less about the customer experience. Plus it increases the likelihood of stranding customers’ data.
Stranded, captive data is the result of vendors optimizing their products for margins and not markets. This approach to product development also tends to stifle innovation.
If a franchise remains strong and can be enforced so captives can’t escape, vendors can still make a decent living. But no such franchise exists today in big data, even among established players like IBM, Oracle, and EMC.
Enterprise customers continue to purchase new warehouse products that promise to solve all their data problems only to have to move—yet again—all the data from the last failed platform to the new and improved one.
Improvements in cost and scale mean that the latest and most capable system ends up with the most data. All of the old platforms did such a good job of snaring data that it became technically or politically difficult—usually both—to migrate to a new system.
Many enterprises have an large collection of stranded data sources—not just in last year’s database on expensive storage arrays—but vast repositories of analog data (such as X-rays) that haven’t yet made it onto that cockroach of all storage mediums, tape.
Enclosed Water Towers
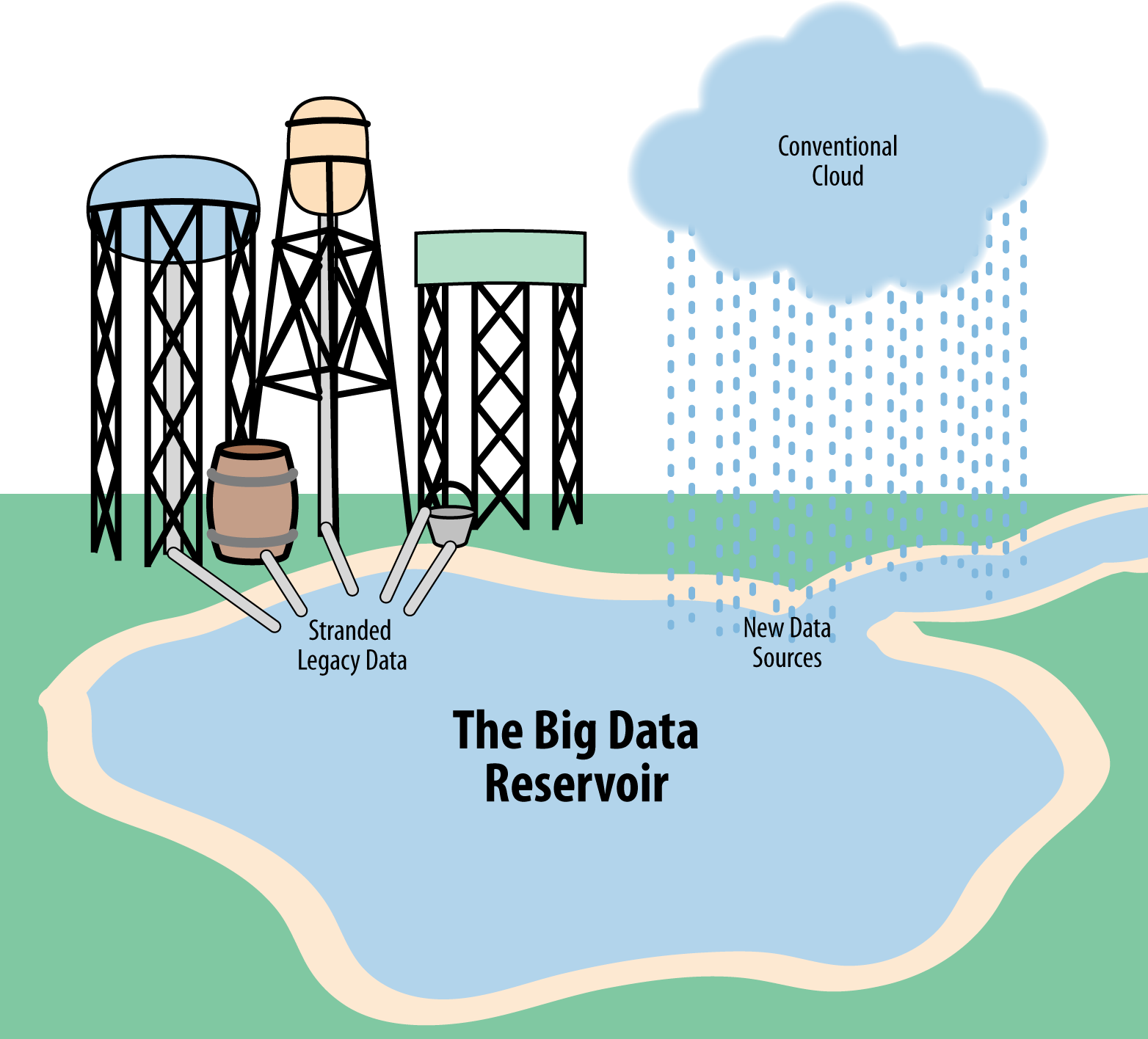
As the tsunami of data inundates enterprises, some may feel that their existing water towers of data are clean and safe from contamination. Despite those tanks being well built and expensive, relative to the millions of gallons of water that come ashore with just the first wave, they hold little and reveal less. The volume of data already coming into enterprises is enough to fill a Los Angeles County service reservoir in minutes.
Because enterprises have spent the last 20 years constructing larger and larger water tanks of stranded, captive data, they need to start building reservoirs to safely capture the raw data (including all the debris) so that it can be processed and treated. An Oracle database running on EMC hardware is a very capable water tank, but it remains a closed source for only a few analytic residents.
For enterprises to reap the benefits that will come from being able to analyze all their aggregated data, both old and new, they must stop stranding data in tanks and start constructing a more open and common reservoir for data that uncouples accessibility from analysis. These new repositories will function like the fresh water reservoirs that serve a city the size of Los Angeles.
In California, the majority of rain falls between November and March, but water demand is constant. Reservoirs are an efficient way to store hundreds of thousands of acre-feet, so water districts use their plumbing and pumps to deliver water to downstream customers.
Like water in a tsunami wall or behind an earthen damn that has just failed, water can be an extremely destructive force of nature. Too little water and mammals like you and I end up at the wrong end of our own perishability scale. At rest, too much water is not usually considered a hazard, but water under the influence of gravity or seismicity can get out of control and cause limitless destruction.
Data, like water, must be treated with respect. Mammals need fresh and clean drinking water; enterprises need safe and clean data. Since a big data reservoir will need to efficiently accommodate hundreds of exabytes, it will be worth the bother of building accessible and robust reservoirs. And it will be critical to the sustainability of the enterprise.
The Big Data Water District
The Tennessee Valley Authority was one of the largest public works projects in the history of the United States. To many enterprises, building a big data reservoir will feel like a project on the scale of the TVA.
A big data reservoir must be able to hold all the water you might ever need to collect, yet still be accessible, robust, and affordable to both construct in the present and maintain in the future.
The file system contained within Hadoop is one of the first commercial file systems to meet all these criteria. Hadoop consists of two major components: the file system (HDFS) and a parallel job scheduler. When HDFS creates a file, it spreads the file over all available nodes and makes enough copies so that when a job runs on the cluster, there are enough spare copies of the file to ensure as much parallelism and protection as possible.
File systems have always been closely associated with databases and operating systems. A file system isn’t usually thought of as a distinct piece of technology, but more as a tightly integrated piece or natural extension of the database or operating system kernel. For example, Oracle’s database kernel always had aspects of a file system built into it: tables, segments, and extents all perform functions that are associated with a traditional file system.
Veritas was one of the first companies to demonstrate that a file system was valuable enough to stand on its own as a product and didn’t have to be embedded within either the OS or database. Veritas is no longer around, but it wasn’t because the functional autonomy of a file system was a bad idea. Execution, competitors’ egos, and sheer luck influence the destiny of most commercial technologies.
The HDFS Reservoir
The Hadoop Distributed File System is not a complex, feature-rich, kitchen sink file system, but it does two things very well: it’s economical and functional at enormous scale. Affordable. At. Scale. Maybe that’s all it should be.
HDFS is the only economically sustainable, computational file system in existence. Some file systems share, like NFS. Some file systems scale, like Ceph. Most file systems require the user to supply the processing capabilities, such as a database or pile of scripts.
Hadoop comes with a scheduling capability that enables several diverse forms of processing across the entire file system. Sometimes that processing is for analytics, sometimes for transcoding, and sometimes it enables databases and their SQL queries.
Hadoop comes with some built-in processing capabilities, such as Pig (pile of scripts) and Hive (a simple SQL database) that are scheduled in parallel across the cluster. HDFS is not a general purpose, transactional file system like NFS, but it is a flexible, purpose-built, hyper-scalable analytics file system.
A big data reservoir should make it possible for traditional database products to directly access HDFS and still provide a canal for enterprises to channel their old data sources into the new reservoir.
Big data reservoirs must allow old and new data to coexist and intermingle. For example, DB2 currently supports table spaces on traditional OS file systems, but when it supports HDFS directly, it could provide customers with a built-in channel from the past to the future.
HDFS contains a feature called federation that, over time, could be used to create a reservoir of reservoirs, which will make it possible to create planetary file systems that can act locally but think globally.
Third Eye Blind
The time and engineering effort required to navigate old data sources through the canal will frequently exceed the effort to run a Hadoop job, which itself is no small task. Hadoop is a powerful programming platform, but it is not an application platform.
Some customers are surprised to find their Hadoop cluster comes from the factory empty. This is the DIY part of it: even if you buy a dedicated hardware appliance for Hadoop, it doesn’t come with the applications that your business requires to analyze your data.
Doing it yourself involves having a competent team of engineers who are capable of both loading the data and writing the applications to process that data. These developers must construct a processing workflow that is responsible for generating the insight.
The cast of developers required includes data scientists, workflow engineers (data wranglers), and cluster engineers who keep the supercomputers fed and clothed.
Clusters are loaded two ways: from all the existing stranded sources and with greenfield sources (such as a gaggle of web server logs). Moving old data from the existing stranded sources is often an underfunded project of astonishing complexity. Like any major canal project, the construction of a data canal between legacy sources and the new reservoir will be a complex platform project in its own right.
Migrating large amounts of data is particularly annoying because old systems need to continue to run unimpeded during migration, so accessing those systems is a delicate problem. This third migration platform is hidden from view and must architecturally serve two masters while moving data quickly and carefully.
It can be so difficult that even moving a modest amount of data (for example, 30 TB of patient records from an old DB2 mainframe into a Hadoop cluster) will feel like moving passengers off a bus that explodes if it slows down.
Spectrum of Analytic Visibility
Chocolate or vanilla, analog versus digital—it seems as if big data only comes in two flavors, structured and unstructured, but structure lives on a spectrum of analytic visibility into the data.
Video data is frequently cited as an unstructured data source, but is seriously structured. An MPEG transport stream contains all sorts of bits to help a set-top box find the correct audio and video streams. Within those streams, there is enough “structure” for a set-top box to disentangle the audio and video streams.
The degree of structure required depends on what is to be discovered. A set-top box must be aware of many layers of structure within the bit-stream, whereas an analyst running a big data job to search for criminals in CCTV footage is only interested in the odd macro block and doesn’t care if the sound locks to picture.
NoSQL databases have become popular for their affordability and ease of use while operating at global scale. The organization of data found in the family of noSQL databases is often pejoratively described as “unstructured,” but a better way to describe it is “simply structured.”
Viewed from deep within a complex and expensive relational database, this simple structure might seem completely unstructured, but the amount of structure required depends entirely on where and what is being looked for and how fast it must be found.
As far back as the 1960s, there was a need to access information in a way that was simple and fast, yet not necessarily sequentially. This method was called the index sequential access method. Access method is a term still used today inside database engines to describe how data is read from tables. An ISAM file had a single index key that could be used to randomly access single records instead of using a ponderous sequential scan. A user supplied a key and values that were associated with that key were returned to the user.
An ISAM-like, key-value table can also be constructed in an enterprise-grade relational database as a simple table, but it is going to be an expensive key-value table, and this is what limits its size, not the inability of the enterprise engine’s ability to construct it.
The easiest way to access hundreds of terabytes of data requires access methods to be simple (and by implication, scalable). Simple and scalable requires a relatively simple method like key-value pair.
The new generation of fast and cheap noSQL databases now being used for big data applications are also known as key-value pair databases. The structural antithesis of noSQL is the class of complex and expensive uberSQL relational databases.
Big data is about the workflow of cleaning, filtering, and analyzing patterns that lead to discovery. Overly structured data, by definition, has already been editorialized, refined, and transformed. With the ability to aggregate so much raw data and all the intermediate steps (including the mistakes) and the final “clean” data, a big data reservoir exposes the workflow.
The more this workflow (as ugly as it might be) is exposed to scientists, business owners, and data wranglers, the greater the potential to discover things they didn’t know they should have been looking for in the first place. This puts the epiphany into big data.
Historically, this process was called extract, transform, and load (ETL). But the economics and scale of Hadoop have changed the order to ELT since the raw data is loaded before the scheduling power of Map/Reduce can be brought to bear on multiple transform pipelines.
Hadoop users have already discovered that the ability to clean up processing pipelines alone justifies the acquisition of a Hadoop cluster. In these cases, analysis must still be conducted in old legacy database silos and re-tooling the analysis pipelines tends to be more difficult. Hadoop also redefines ETL to ELTP, where the P stands for Park. The raw data, processed data, and archived data can now all park together in a single, affordable reservoir.
The Cost of Flexibility
Initial attempts at data discovery started on relational databases when enough data had accumulated to make discovery worthwhile. Most relational databases were not designed to handle acre-feet of data—most were designed to be proficient at online transaction processing (OLTP). Eventually, data warehousing capabilities were grafted onto these database engines, but the grafting was difficult and early versions were unsuccessful.
These early attempts at analyzing big data were impeded by kernels that had been optimized for hundreds of tables with hundreds of columns, not a few huge tables with just a few columns and billions of rows.
Eventually, traditional database vendors developed effective methods for handling queries on huge tables, but this resulted in more structure than necessary. A relational data model (or schema) is a collection of tables with various columns. This model provided far more flexibility than the approach it replaced (IBM’s IMS hierarchical data model from the 1970s), yet relational technology still required users to know—ahead of time—which columns went into what tables.
Common relational database design encouraged a practice called normalization, which maximized flexibility in case users needed to add new tables or new columns to existing tables. Normalization also minimized the duplication of data between tables because disk space was expensive. This flexibility is why the relational database quickly replaced hierarchical database technology that had been the de facto database up until that point.
SQL queries frequently require many tables to be joined together. The piece of magic inside the database kernel that makes this possible is called the SQL query parser/optimizer or cost-based optimizer (CBO). SQL optimizers use algorithms to determine the cost of retrieving the data in order to select the most cost-effective retrieval strategy.
Joining all these tables together to solve a query quickly is a torturous exercise in pretzel logic. A CBO engineered for highly normalized OLTP schemas is designed to join complex tables with thousands of rows. It was not designed for big data schemas that have simpler tables with billions of rows. OLTP-based CBOs optimize space for time, whereas big data CBOs must optimize time for space.
Big data workloads consist of a broad spectrum of purpose-built workloads. This has spawned a myriad of new database products that work at scale but are purpose-built because it is not possible to build a single, general-purpose database kernel or CBO to handle the entire spectrum.
In their attempts to address big data with general-purpose warehouse products, customers often end up purchasing “one of each,” only to have each attempt result in yet another stranded water tank of data.
By the early 2000s, vast quantities of enterprise data were stranded on software and hardware platforms that were never designed for big data. Even the software and hardware components that were capable of big data (and had re-tooled their CBO to handle billion-row tables) were so expensive that big data would be better described as Big Bucks.
Large pools of data that need discovery or that need to be combined with pools from other uberSQL repositories have been trapped in slow, complex, and expensive databases. Building diversion canals between these stranded water towers and the big data reservoir will be difficult, but once fully charged, a reservoir that finally aggregates the data in a single, scalable repository for a single analytic view will be the most important legacy of big data.
Get Disruptive Possibilities: How Big Data Changes Everything now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

