Chapter 1. The Wall of Water
And Then There Was One
And then there was one—one ecosystem, one platform, one community—and most importantly, one force that retrains vendors to think about customers again. Welcome to the tsunami that Hadoop, noSQL, and all that computing on a global scale represents.
Some enterprises, whose businesses don’t appear to be about data at all, are far from the shoreline where the sirens are faint. Other organizations that have been splashing around in the surf for decades now find themselves watching the tide recede rapidly.
The speed of the approaching wave is unprecedented, even for an industry that has been committed, like any decent youth movement, to innovation, self-destruction, and reinvention. Welcome to the future of computing. Welcome to big data. Welcome to the end of computing as we have known it for 70 years.
Big data is a type of supercomputing for commercial enterprises and governments that will make it possible to monitor a pandemic as it happens, anticipate where the next bank robbery will occur, optimize fast food supply chains, predict voter behavior on election day, and forecast the volatility of political uprisings while they are happening. The course of economic history will change when, not if, criminals stand up their Hadoop clusters.
So many seemingly diverse and unrelated global activities will become part of the big data ecosystem. Like any powerful technology, in the right hands, it propels us toward limitless possibilities. In the wrong hands, the consequences can be unimaginably destructive.
The motivation to get big data is immediate for many organizations. If a threatening organization gets the tech first, then the other organization is in serious trouble. If Target gets it before Kohl’s or the Chinese navy gets it before the US navy or criminal organizations get it before banks, then they will have a powerful advantage.
The solutions will require enterprises to be innovative at many levels, including technical, financial, and organizational. As in the 1950s during the cold war, whoever masters big data will win the arms race, and big data is the arms race of the 21st century.
Commercial Supercomputing Comes of Age
Trends in the computing industry mimic those of fashion—if you wait long enough, you will wear it again. Many of the technologies found in big data have been circulating in the industry for decades, such as clustering, parallel processing, and distributed file systems.
Commercial supercomputing originated with internet companies operating at global scale that needed to process ever-increasing numbers of users and their data (Yahoo! in the 1990s, then Google and Facebook). However, they needed to do this quickly and economically—in other words, affordably at scale. This is commercial supercomputing known as big data.
Big data will bring disruptive changes to organizations and vendors, and will reach far beyond networks of friends to the social network that encompasses the planet. But with those changes come possibilities. Big data is not just this season’s trendy hemline; it is a must-have piece that will last for generations.
A Stitch in Time
Large-scale computing systems are not new. Weather forecasting has been a nasty big data problem since the beginning of time, when weather models ran on a single supercomputer that could fill a gymnasium and contained a couple of fast (for the 1970s) CPUs with very expensive memory. Software in the 1970s was primitive, so most of the performance at that time was in the clever hardware engineering.
By the 1990s, software had improved to the point where programs running on monolithic supercomputers could be broken into a hundred smaller programs working at the same time on a hundred workstations. When all the programs finished running, their results were stitched together to form a week-long weather simulation.
Even in the 1990s, the simulators used to take fifteen days to compute seven days of weather. It really didn’t help farmers to find out that it rained last week. Today, the parallel simulations for a weeklong forecast complete in hours.
As clairvoyant as weather forecasting appears to be, those programs can’t predict the future; they attempt to simulate and model its behavior. Actual humans do the forecasting, which is both art and supercomputing craft.
Most weather forecasting agencies use a variety of simulators that have different strengths. Simulators that are good at predicting where a waterspout will make landfall in Louisiana are not so great at predicting how the morning marine layer will affect air operations at San Francisco International.
Agency forecasters in each region pore over the output of several simulations with differing sets of initial conditions. They not only look at actual data from weather stations, but also look out the window (or the meteorological equivalent—Doppler radar).
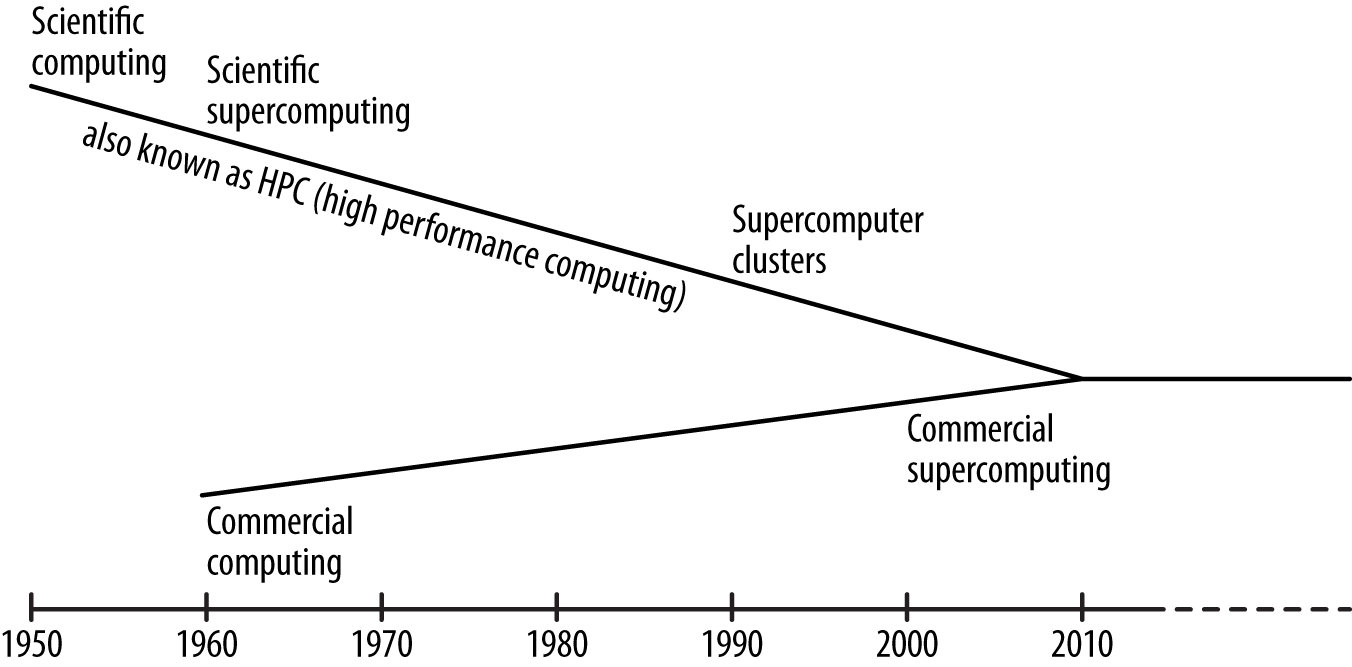
Although there is a lot of data involved, weather simulation is not considered “Big Data” because it is so computationally intense. Computing problems in science (including meteorology and engineering) are also known as high-performance computing (HPC) or scientific supercomputing.
The very first electronic computers were doing scientific computing, such as calculating trajectories of missiles or cracking codes, all of which were mathematical problems involving the solution of millions of equations. Scientific computing also solves equations for “non-scientific” problems such as rendering animated films.
Big data is the commercial equivalent of HPC, which could also be called high-performance commercial computing or commercial supercomputing. Big data can also solve large computing problems, but it is less about equations and more about discovering patterns.
In the 1960s, banks first used commercial computers for automating accounts and managing their credit card business. Today companies such as Amazon, eBay, and even large brick-and-mortar retailers use commercial supercomputing to solve their business problems, but commercial supercomputing can be used for much more than analyzing bounced checks, discovering fraud, and managing Facebook friends.
The Yellow Elephant in the Room
Hadoop is the first commercial supercomputing software platform that works at scale and is affordable at scale. Hadoop exploits the parlor trick of parallelism already well established in the HPC world. It was developed in-house at Yahoo! to solve a very specific problem, but they quickly realized its potential to tackle many other computing problems.
Although Yahoo!’s fortunes have changed, it made a huge and lasting contribution to the incubation of Google, Facebook, and big data.
Hadoop was originally created to affordably process Yahoo!’s flood of clickstream data, the history of the links a user clicks on. Since it could be monetized to prospective advertisers, analysis of clickstream data from tens of thousands of servers required a massively scalable database that was economical to build and operate.
Yahoo! found most commercial solutions at the time were either incapable of scaling or unaffordable if they could scale, so Yahoo! had to build it from scratch, and DIY commercial supercomputing was born.
Like Linux, Hadoop is an open-source software technology. Just as Linux spawned commodity HPC clusters and clouds, Hadoop has created a big data ecosystem of new products, old vendors, new startups, and disruptive possibilities.
Because Hadoop is portable, it is not just available on Linux. The ability to run an open source product like Hadoop on a Microsoft operating system is significant and a triumph for the open source community—a wild fantasy only 10 years ago.
Scaling Yahoovians
Because Yahoo! was the first company to operate at such scale, understanding their history is key to understanding big data’s history. Jerry Yang and Dave Filo started Yahoo! as a project to index the web, but the problem grew to the point where conventional strategies simply could not keep up with the growth of content that needed to be indexed.
Even before Hadoop came along, Yahoo! required a computing platform that always took the same amount of time to build the web index however large the web grew. Yahoo! realized they needed to borrow the parallelism trick from the HPC world to achieve scalability, and then Yahoo!’s computing grid became the cluster infrastructure that Hadoop was subsequently developed on.
Just as important as the technology that Yahoo! developed was how they reorganized their Engineering and Operations teams to support computing platforms of this magnitude. Yahoo!’s experience operating a massive computing plant that spread across multiple locations led them to reinvent the IT department.
Complex platforms need to be initially developed and deployed by small teams. Getting an organization to scale up to support these platforms is an entirely different matter, but that reinvention of the organization is just as crucial as getting the hardware and software infrastructure to scale.
Like most corporate departments from HR to Sales, IT organizations traditionally achieved scalability by centralizing skills. There is no question that having a small team of experts managing a thousand storage arrays is more cost effective than paying the salaries for a huge team, but Storage Admins don’t have a working knowledge of the hundreds of applications on those arrays.
Centralization trades generalist working knowledge for cost efficiency and subject matter expertise. Enterprises are finally starting to understand the unintended consequences of trade-offs made long ago that produced silos that will inhibit their ability to implement big data.
Traditional IT organizations partition expertise and responsibilities, which constrains collaboration between and among groups. Small errors due to misunderstandings might be tolerable on few small email servers, but small errors on production supercomputers can cost corporations a lot of time and money.
Even a 1% error can make a huge difference. In the world of big data, 300 terabytes is merely Tiny Data, but a 1% error in 300 terabytes is 3 million megabytes. Finding and fixing errors at this scale can take countless hours.
Yahoo! learned what the HPC community that has been living with large clusters for about 20 years knows. They learned that a small team with a working knowledge of the entire platform works best. Silos of data and responsibility become impediments in both scientific supercomputing and commercial supercomputing.
Internet-scale computing plants work because early practitioners learned a key lesson: supercomputers are finely tuned platforms that have many interdependent parts and don’t operate as silos of processing. Starting in the 1980s, however, customers were encouraged to view the computing platform as a stack with autonomous layers of functionality.
This paradigm was easier to understand, but with increasingly complex platforms, the layer metaphor began to cognitively mask the underlying complexity that hindered or even prevented successful triage of performance and reliability problems.
Like an F1 racing platform or a Boeing 737, supercomputer platforms must be understood as a single collection of technologies or the efficiency and manageability will be impaired.
Supercomputers Are Platforms
In the early history of the computer industry, systems were platforms—they were called mainframes and typically came from a company that also supplied a dedicated group of engineers in white shirts and ties who worked alongside their customers to ensure the platform performed when they handed over the keys.
This method was successful as long as you enjoyed being an IBM customer—there has always been a fine line between “throat to choke” and monopoly arrogance. After IBM crossed this line in the 1960s, the resulting industry offered more choice and better pricing, but it became an industry of silos.
Today, companies that dominate their silo still tend to behave like a monopoly for as long as they can get away with it. As database, server, and storage companies proliferated, IT organizations mirrored this alignment with corresponding teams of database, server, and storage experts.
However, in order to stand up a big data cluster successfully, every person who touches or works on the cluster must be physically and organizationally close to one another. The collaborative teamwork required for successful cluster deployments at this scale never, ever happens in a sub-silo of a silo.
If your company wants to embrace big data or gather in that magical place where Big Data Meets The Cloud, the IT organization will have to tear down some silos and become more aware of the platform.
Unfortunately, most organizations do not handle any change well, let alone rapid change. Chaos and disruption have been constants in this industry, yet were always accompanied by possibility and innovation. For enterprises that are willing to acknowledge and prepare for the wall of water, big data will be a cleansing flood of new ideas and opportunities.
Big Data! Big Bang!
As the big data ecosystem evolves over the next few years, it will inundate vendors and customers in a number of ways.
First, the disruption to the silo mentality, both in IT organizations and the industry that serves them, will be the Big Story of big data.
Second, the IT industry will be battered by the new technology of big data because many of the products that predate Hadoop are laughably unaffordable at scale. Big data hardware and software is hundreds of times faster than existing enterprise-scale products and often thousands of times cheaper.
Third, technology as new and disruptive as big data is often resisted by IT organizations because their corporate mandate requires them to obsess about minimizing OPEX and not tolerate innovation, forcing IT to be the big bad wolf of big data.
Fourth, IT organizations will be affected by the generation that replaces those who invested their careers in Oracle, Microsoft, and EMC. The old adage “no one ever gets fired for buying (historically) IBM” only applies to mature, established technology, not to immature, disruptive technology. Big data is the most disruptive force this industry has seen since the introduction of the relational database.
Fifth, big data requires data scientists and programmers to develop a better understanding of how the data flows underneath them, including an introduction (or reintroduction) to the computing platform that makes it possible. This may be outside of their comfort zones if they are similarly entrenched within silos. Professionals willing to learn new ways of collaborating, working, and thinking will prosper, and that prosperity is as much about highly efficient and small teams of people as it is about highly efficient and large groups of servers.
Sixth and finally, civil liberties and privacy will be compromised as technology improvements make it affordable for any organization (private, public, or clandestine) to analyze the patterns of data and behavior of anyone who uses a mobile phone.
Endless Possibilities
Today, big data isn’t just for social networking and machine-generated web logs. Agencies and enterprises will find answers to questions that they could never afford to ask and big data will help identify questions that they never knew to ask.
For the first time, car manufacturers can afford to view their global parts inventory spread over hundreds of plants and also collect the petabytes of data coming from all the sensors that are now in most vehicles.
Other companies will be able to process and analyze vast amounts of data while they are still in the field collecting it. Prospecting for oil involves seismic trucks in the field collecting terabytes of data.
Previously, the data was taken back to an expensive datacenter and transferred to expensive supercomputers, which took a lot of expensive time to process. Now a Hadoop cluster spread over a fleet of trucks sitting in a motel parking lot could run a job overnight that provides guidance on where the next day’s prospecting should take place.
In the next field over, farmers could plant thousands of environmental sensors that transmit data back to a Hadoop cluster running in a barn to “watch” the crops grow.
Hadoop clusters make it more affordable for government agencies to analyze their data. The WHO and CDC will be able to track regional or global outbreaks like H1N1 and SARS almost as they happen.
Although big data makes it possible to process huge data sets, it is parallelism that makes it happen quickly. Hadoop can also be used for data sets that don’t qualify as big data, but still need to be processed in parallel. Think about a tiny Hadoop cluster running as an artificial retina.
Whether the wall of data arrives in the form of a tsunami, monsoon, or even a fog, it must be collected into a commonly accessible and affordable reservoir so that many of these possibilities can be realized.
This reservoir cannot be yet another drag-and-drop enterprise data warehouse pyramid schema. The data contained in this reservoir, like the fresh water found in real reservoirs, must sustain the future life of the business.
Disruptive and opportunistic, big data is thrusting computer science away from the classic John von Neumann style of computing, where we finally stop looking at every piece of hay in the millions of haystacks that big data makes possible and move toward a new form of spatial supercomputing. Long before those steps are taken, big data will change the course of history.
Get Disruptive Possibilities: How Big Data Changes Everything now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

