Chapter 1. Introduction
If I had asked people what they wanted, they would have said faster horses.
Henry Ford (July 30, 1863 - April 7, 1947), founder of the Ford Motor Company
With microservices taking the software industry by storm, traditional enterprises are forced to rethink what they’ve been doing for almost two decades. It’s not the first time technology has shocked the well-oiled machine of software architecture to its core. We’ve seen design paradigms change over time and project management methodologies evolve. Old hands might see this as another wave that will gently find its way to the shore of daily business. But this time it looks like the influence is far bigger than anything we’ve seen before. And the interesting part is that microservices aren’t new.
Talking about compartmentalization and introducing modules belongs to the core skills of architects. Our industry has learned how to couple services and build them around organizational capabilities. The really new part in microservices-based architectures is the way truly independent services are distributed and connected back together. Building an individual service is easy. Building a system out of many is the real challenge because it introduces us to the problem space of distributed systems. This is a major difference from classical, centralized infrastructures. As a result, there are very few concepts from the old world that still fit into a modern architecture.
Today’s Challenges for Enterprises
In the past, enterprise developers had to think in terms of specifications and build their implementations inside application server containers without caring too much about their individual life cycle. Creating standardized components for every application layer (e.g., UI, Business, Data, and Integration) while accessing components across them was mostly just an injected instance away.
Connecting to other systems via messaging, connectors, or web services in a point-to-point fashion and exposing system logic to centralized infrastructures was considered best practice. It was just too easy to quickly build out a fully functional and transactional system without having to think about the hard parts like scaling and distributing those applications. Whatever we built with a classic Java EE or Spring platform was a “majestic monolith” at best.
While there was nothing wrong with most of them technically, those applications can’t scale beyond the limits of what the base platform allows for in terms of clustering or even distributed caching. And this is no longer a reasonable choice for many of today’s business requirements.
With the growing demand for real- and near-time data originating from mobile and other Internet-connected devices, the amount of requests hitting today’s middleware infrastructures goes beyond what’s manageable for operations and affordable for management. In short, digital business is disrupting traditional business models and driving application leaders to quickly modernize their application architecture and infrastructure strategies. The logical step now is to switch thinking from collaboration between objects in one system to a collaboration of individually scaling systems. There is no other way to scale with the growing demands of modern enterprise systems.
Why Java EE Is Not an Option
Traditional application servers offer a lot of features, but they don’t provide what a distributed system needs. Using standard platform APIs and application servers can only be a viable approach if you scale both an application server and database for each deployed service and invest heavily to use asynchronous communication as much as possible. And this approach would still put you back into the 1990s with CORBA, J2EE, and distributed objects. What’s more, those runtimes are resource intensive and don’t start up or restart fast enough to compensate for failing instances. If that’s not enough, you’re still going to miss many parts of the so-called “outer architecture” like service discovery, orchestration, configuration, and monitoring.
Aren’t Microservices Just SOA?
Many might think that service-oriented architecture (SOA) dressed up in new clothes is the perfect acronym for microservices. However, the answer to this question is twofold: yes, because the thoughts behind isolation, composition, integration, and discrete and autonomous services are the same; and no, because the fundamental ideas of SOA were often misunderstood and misused, resulting in complicated systems where an enterprise service bus (ESB) was used to hook up multiple monoliths communicating over complicated, inefficient, and inflexible protocols. This means the requirement for SOA is stronger than ever. And this might have been the biggest problem for SOA-based applications. They simply tried to apply a new technology stack without redesigning and re-architecturing the existing application portfolio.
DevOps and Methodologies
Model culture after open source organizations: meritocracy, shared consciousness, transparency, network, platforms.
Christian Posta, Red Hat
Let me issue a warning here: this book focuses on the implementation parts, rather than the organizational aspects, of reactive microservices. But you won’t succeed with a microservices architecture if you forget about them. While you can read a lot about how early adopters like Netflix structured their teams for speed instead of efficiency, the needs for enterprise-grade software are different. Teams are usually bigger and the software to be produced is more complex and involves a lot more legacy code. Nevertheless, there are good approaches to structuring enterprise-size development teams around business capabilities and in small units while retaining the relevant steering mechanisms.
The many organizational aspects are summarized in a great presentation by Fred George. The most important individual principle from this presentation is: “When you build it, you own it.” From development to testing to production.
The Pyramid of Modern Enterprise Java Development
There are other surrounding innovations that are creating new opportunities and platform approaches for traditional enterprises. Our industry is learning how everything fits into the bigger picture of distributed systems by embracing all the individual parts and architecting the modern enterprise.
The pyramid in Figure 1-1 was introduced in my first book and breaking it down into individual parts and technologies from an implementation perspective is a natural next step.
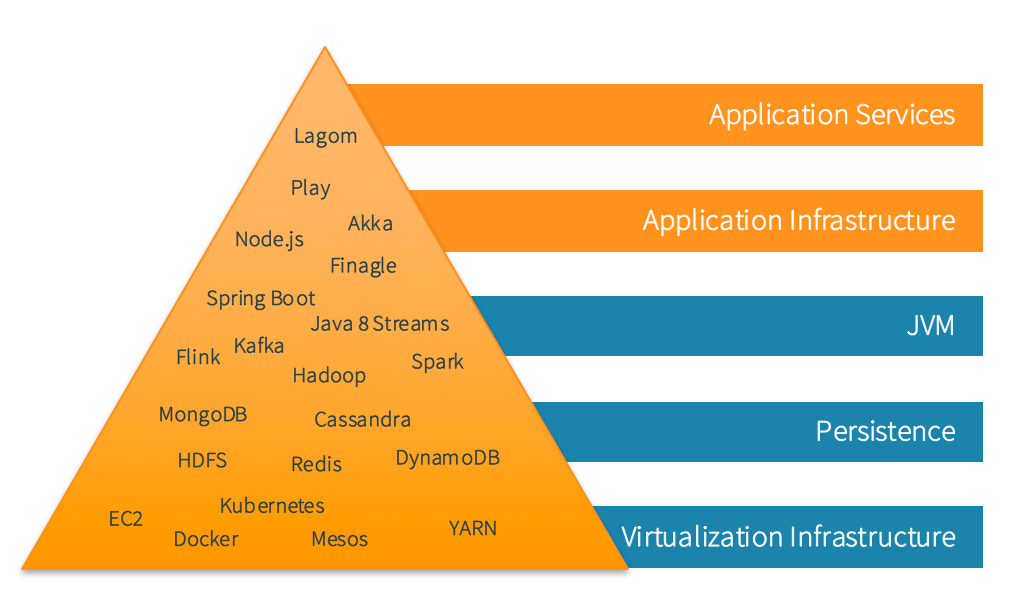
Figure 1-1. Pyramid of modern enterprise Java development refined
Virtualization Infrastructure
Virtualization and infrastructures have been major trends in software development, from specialized appliances and software as a service (SaaS) offerings to virtualized datacenters. In fact, most of the applications we use—and cloud computing as we know it today—would not have been possible without the server utilization and cost savings that resulted from virtualization.
But now new cloud architectures are reimagining the entire data center. Virtualization as we know it is reaching the limits of what is possible for scaling and orchestration of individual applications. With today’s applications looking to exploit smaller runtimes and individual services, the need for a complete virtualized operating system (OS) is decreasing. What originated with the Internet giants like Google and Facebook quickly caught the attention of major enterprise customers who are now looking to adopt containers and orchestration. And the trust put forward into cloud-based solutions using those technologies is only increasing.
Both virtual machines and containers are means of isolating applications from hardware. However, unlike virtual machines—which virtualize the underlying hardware and contain an OS along with the application stack—containers virtualize only the OS and contain only the application. As a result, containers have a very small footprint and can be launched in mere seconds. A physical machine can accommodate four to eight times more containers than VMs. With the transformation of data centers, and the switch over to more lightweight container operation systems, our industry is fully adopting public, private, and hybrid cloud infrastructures.
Persistence
The traditional method of data access in monoliths (e.g., Java database access—JDBC) doesn’t scale well enough in highly distributed applications because JDBC operations block the socket input/output (IO) and, further on, blocks the thread they run on. The key concept of immutability plays a very important role in microservices. They are thread-safe and you don’t run into synchronization issues. And while they can’t be changed, there is no problem parallelizing work without conflicting access. This is extremely helpful in representing commands, messages, and states. It also encourages developers to implement distributed systems with an event-sourced architecture.
Event sourcing (ES) and command query responsibility segregation (CQRS) are frequently mentioned together. Both of them are explained in Chapter 3. Although neither one necessarily implies the other, they do complement each other. The main conceptual difference for ES architectures is that changes are captured as immutable facts of things that have happened. For example: “the flight was booked by Markus.” All events are stored and the current state can be derived from the events. The advantages are plenty:
-
There is no need for O/R mapping. Events are logged and part of the domain model.
-
With every change being captured as an event, the current state can easily be replayed and audited because both operate on the same data.
-
Persistence works without updates or deletes, the most expensive data manipulation operations.
With these approaches in mind, there is no longer a need for traditional relational database management systems (RDBMS). The persistence of modern applications allows for the embrace of NoSQL-based data stores. A NoSQL (originally referring to “non-SQL” or “nonrelational”) database provides a mechanism for storage and retrieval of data that is modeled differently than the tabular relations used in relational databases.
Combining these technologies with the JVM allows developers to build a “fast data” architecture. The emphasis on immutability improves robustness, and data pipelines are naturally modeled and implemented using collections (like lists and maps) with composable operations. The phrase “fast data” captures the range of new systems and approaches, which balance various tradeoffs to deliver timely, cost-efficient data processing, as well as higher developer productivity.
Java Virtual Machine (JVM)
Handling streams of data, especially “live” data whose volume is not predetermined, requires special care in an asynchronous system. The most prominent issue is that resource consumption needs to be controlled so that a fast data source does not overwhelm the stream destination. Asynchronicity is the better way to enable the parallel use of computing resources on collaborating network hosts or multiple CPU cores within a single machine.
The second key to handling this data is about being able to scale your application to deal with a lot of concurrency. This can best be achieved with a nonblocking, streams-based programming approach. It can’t be done effectively with thread pools and blocking (OS threads) implementations. The components and implementations that meet these requirements must follow the Reactive Manifesto, which means they are:
-
Scalable up and down with demand
-
Resilient against failures that are inevitable in large distributed systems
-
Responsive to service requests even if failures limit the ability to deliver services
-
Driven by messages or events from the world around them
Aims and Scope
This report walks you through the creation of a sample reactive microservices-based system. The example is based on Lagom, a new framework that helps Java developers to easily follow the described requirements for building distributed, reactive systems. As an Apache-licensed, open source project, it is freely available for download, and you can try out the example yourself or play with others provided in the project’s GitHub repository.
Going forward, Chapter 2 provides an overview of the reactive programming model and basic requirements for developing reactive microservices. Chapter 3 looks at creating base services, exposing endpoints, and then connecting them with a simple, Web-based user interface. Chapter 4 deals with the application’s persistence, while Chapter 5 focuses on first pointers for using integration technologies to start a successful migration away from legacy systems.
Get Developing Reactive Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

