Chapter 4. Speech Recognition Technology
WE’VE TALKED ABOUT MANY of the crucial voice user interface (VUI) design elements. So far, they’ve been light on the technical details of speech recognition technology itself. This chapter gets more technical, looking under the hood so that you can make sure your VUI design takes into account (and takes advantage of) the technology itself. It will also give you the ability to confidently reference the underlying technology when explaining your design decisions.
To create a VUI, your app must have one key component: automated speech recognition (ASR). ASR refers to the technology by which a user speaks, and their speech is then translated into text.
Choosing an Engine
So how to choose your ASR tool? There are free services as well as those that require licensing fees. Some offer free use for development but require payment for commercial use.
As of this writing, there are two major fee-based speech recognition engines: Google and Nuance. Other options in this space include Microsoft’s Bing and iSpeech.
Free ASR tools include the Web Speech API, Wit.ai, Sphinx (from Carnegie Mellon), and Kaldi. Amazon has its own tool, but at the moment it can be used only when creating skills for the Amazon Echo (which is free).
Wikipedia has a much more detailed list, which you can access at https://en.wikipedia.org/wiki/List_of_speech_recognition_software.
Some companies offer multiple engines, as well; for example, Nuance has different offerings depending on what you plan to do, such as a medical app or dictation.
When choosing an engine, there are two things that are key:
Robustness of dataset/accuracy
Endpoint detection performance
New companies often have difficulty breaking into the speech recognition market—they might have good technology, they simply don’t have the data that larger companies have spent years amassing. Therefore, their recognition will probably not be as good, depending on how wide the domain is.
Often, people become so caught up in focusing on an ASR tool’s accuracy that they forget about the second crucial requirement: good endpoint detection. Endpoint detection is a fancy way of describing how the computer knows when you begin and finish speaking. Choosing an engine with good endpoint (or end-of-speech) detection is crucial. I’ll get into that a little bit later in this chapter.
It can be tempting to use the cheapest available ASR tool in your design, but beware: if the recognition accuracy is poor, or the endpoint detection is sloppy, your user experience will suffer greatly. Having “pretty good” recognition might seem good enough, but users will quickly grow frustrated and give up on your product.
It is also worth noting that not all ASR tools include important advanced features like N-best lists, settable parameters like end-of-speech timeouts, and customized vocabularies.
Barge-In
Another aspect of speech recognition technology that heavily affects your design is the use of barge-in. That is, will you allow your users to interrupt the system when it’s talking?
Barge-in is generally turned on for interactive voice response (IVR) systems, so the user can interrupt the system at any time. When the system detects speech of any kind, it immediately stops playing the current prompt and begins listening, as demonstrated in the following example:
BANKING IVR
You can transfer money, check your account balance, pay a...
USER
[interrupting] Check my account balance.
In the IVR world, barge-in makes a lot of sense. There are often long menus or lists of options, and it’s tedious to always force users to wait. This is especially true for IVR systems that users call regularly.
When you allow barge-in, you must be extra careful with pauses in the prompt as well as placement of questions. Here are some examples of where things can go wrong:
VUI SYSTEM
What would you like to do? [1-second silence] You...
USER
I would...
VUI SYSTEM
[system continues] can. [then stops because user has barged in]
USER
[stops]
In the previous example, the system paused briefly after the initial question. At that point, the user began to speak, but just at that moment, the system continued with its next instruction. Now the user thinks they’ve interrupted the system before it was finished and stops talking, but it’s too late: the system has stopped talking, as well. The conversation has been broken, and it will take an error prompt to get the user back on track. Imagine talking to someone on a bad cell phone connection—there can be a noticeable lag that doesn’t exist in person, and callers often talk over each other.
The example has a second problem. When the system asked the user a question, the user naturally responded. Avoid asking a question and following it with more information, because users tend to respond to the question and will begin speaking before the prompt is finished. It’s best to list what you can do, followed by the question:
VUI SYSTEM
You can check your balance, transfer funds, or speak to an agent. What would you like to do?
Barge-in is also very useful when the system is performing an action that can take a long time or reciting a lot of information. For example, when the Amazon Echo is playing a song, you can barge in at any time and say, “Alexa, stop.” Without barge-in, there would be no way to stop playing music by using a voice command.
Unlike traditional IVR systems, however, Alexa does not stop speaking when just any speech is detected—only her wake word does that. This is sometimes referred to as a hotword or magic word. It’s a very neat trick because it does not stop the system from performing/speaking unless a particular keyword or phrase has been recognized. This is very important in certain situations. Imagine you’ve asked Alexa to play a particular Pandora radio station. Meanwhile, you begin chatting with your family. Having Alexa say, “Sorry, what was that?” after you spoke would be a terrible user experience. Instead, she happily ignores you until her wake word has been confidently recognized.
Hotwords are used in the IVR world as well, but in specific contexts. One example is the San Francisco Bay Area 511 IVR system (for which I was the lead VUI designer). Users can call to get traffic information and estimated driving times, among other things. After giving the name of a highway, the system looks for relevant traffic incidents and begins reading them back to the caller. I wanted to allow users the flexibility of skipping ahead to the next incident, but worried about background noise in the car or other input interrupting the system and stopping it. Imagine that you’re listening to a list of 10 traffic incidents, and you sneeze and the system stops and says, “I’m sorry, I didn’t get that.” You would need to start all over!
Instead, using the hotword technique, only a few key phrases are recognized during this readback, such as “next” and “previous.” When the user speaks, the system does not immediately cut off the prompt, as is done in normal barge-in mode, but continues unless one of the keywords was recognized, only then stopping and moving on to the next action.
Another example for which using a hotword is useful is when the user needs to pause to complete an action in the middle of a conversation. This could occur if a user needs to go and grab something to answer a question, such as getting a pill bottle to check a prescription number in the middle of requesting a refill. The system asks, “Do you need some time to find the prescription number?” and if the user says “yes,” the system instructs the user to say “I’m back” or “continue” when they’re ready, essentially putting the conversation on pause.
For VUI systems that are not voice-only, barge-in is not always advised. When using prerecorded video, for example, barge-in should not be used, because it is difficult to know what to do with video in that case. Would the video of the actor suddenly stop? Would it then shift to a prerecorded video of the actor having been interrupted?
When your VUI system has an avatar or prerecorded video, it’s much more similar to a real human conversation, and users tend to be more polite and wait the system out. They also engage in side speech (talking to someone else) while the avatar or video is speaking, clearly showing they don’t expect the avatar to be listening at that point.
If your system does not have barge-in enabled, do not force the user to listen to long lists or long menus. Instead, break things into more steps and rely on visual lists to reduce cognitive load. For example, if the user must choose from a list of seven video clip titles, it’s not a good idea to say them all out loud. Instead, you can use visually displayed information, as demonstrated here and in Figure 4-1:
USER
Show me the funniest clips with orangutans.
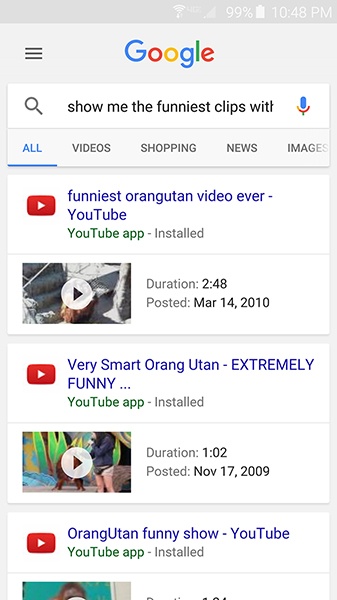
Imagine having the phone read out all those titles. Unless there is a reason the user cannot look at the screen (such as being visually impaired), it’s much smoother to display them graphically.
As a final note on barge-in, it is possible to fine-tune its sensitivity with some ASR tools. Essentially, you can make it more or less sensitive (the less sensitive it is, the more difficult it is for users to barge in).
Timeouts
In addition to paying attention to when the user is speaking, it’s important for a VUI system to know when the user stops speaking. Being able to detect when someone has finished their question or response is essential to a good VUI experience. Without this, the user is not sure whether the system heard them. In addition to losing faith in the system, the conversation becomes more difficult as the user and the system engage in an awkward dance of starting and stopping to speak. Have you ever been on a video chat in which there is a slight lag? It seems so minor, but when you don’t know when the other person has finished speaking, authentic conversation is difficult and painful.
End-of-speech timeout
As mentioned earlier, one of the most important things for a good VUI experience is good endpoint detection, which means, knowing when the user has finished talking (in other words, finished their turn in the conversation).
Some speech recognition engines allow you to configure endpoint detection by setting what is sometimes referred to as the end-of-speech timeout. This refers to the length of the pause in what the user is saying before the system decides that the user is finished speaking.
Not all speech recognition engines allow you to set the end-of-speech timeout, but it is useful to know what their defaults are. A pause of 1.5 seconds is a good rule of thumb for most types of VUI responses. Make it too short and you’ll cut off the user before they’ve finished speaking; make it too long and the user will wonder if the system heard them.
There are instances for which you will want to adjust this timeout if you’re able. The most well-designed VUI systems are flexible enough to have different timeout values at different states. For example, a user-initiated interaction (such as saying, “Ok Google,” or pressing the Apple home button to activate Siri) needs a shorter timeout than the response to “How are you doing today?” In the first case, because the user initiated the event and not the system, it is likely that the user knows exactly what they’re going to say and will not need a long pause. In the second case, the user might stop and start a bit; for example, “I’m feeling...well, earlier I was OK, but now I...my head is hurting.” In this case, if the timeout is too short, the user will be cut off before they’ve finished, which is very rude in conversations.
Another common case for which a longer end-of-speech timeout is needed is when people read a number that’s naturally grouped, such as a credit card. People naturally pause between groups, and you don’t want to cut them off.
The best way to know how to adjust it is to use data. By looking at transcriptions of what people actually said, you can find places in which users are often cut off mid-sentence. In this case, you will want to experiment with extending the end-of-speech timeout.
One area where extending the length of the timeout is helpful is when you expect the user to speak a lot or to hesitate. For example, asking the user to recount the details of a car accident for an insurance app. The user will likely say multiple sentences, pausing occasionally while gathering their thoughts.
In certain cases, it’s also a good idea to shorten the end-of-speech timeout. When users are merely saying “yes” or “no,” a shorter timeout can lead to a snappier, more responsive dialog.
No speech timeout
Another important timeout is for no speech detected (NSP). This should be treated as a separate timeout from end-of-speech for several reasons:
The NSP timeout is longer than the end-of-speech timeout (usually around 10 seconds).
NSP timeouts result in different actions by the VUI system.
It’s helpful for system analysis to determine where there are problems.
In IVR systems, an NSP timeout occurs when the recognizer begins listening for a user response and does not detect any speech for a certain length of time. It’s then up to the VUI designer to decide what to do in this case. With IVR systems, the user is commonly given an error message, such as, “Sorry, I didn’t hear that. What day are you traveling?” and waits for the user to speak.
Some systems do nothing when the NSP timeout is triggered. For example, if you say, “Alexa,” to activate the Amazon Echo and then don’t say anything else, after about eight seconds the blue light at the top of the device will turn off and Alexa will remain silent.
Ok Google (Figure 4-2) waits about five seconds, and if nothing is said, it pops up a screen with examples of what you can say, such as “Call Pizza Hut” and “Show me pictures of cats” (the most common use of the Internet). Siri and Cortana also provide examples after a timeout (Figure 4-3 and Figure 4-4).
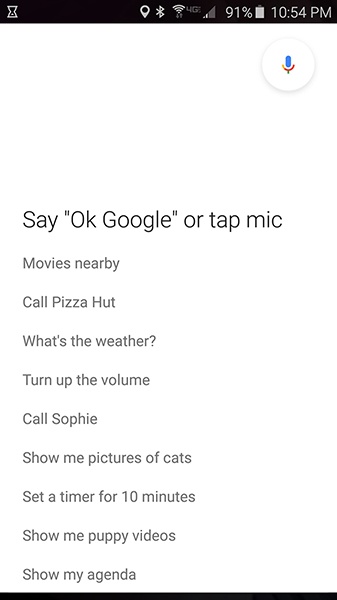
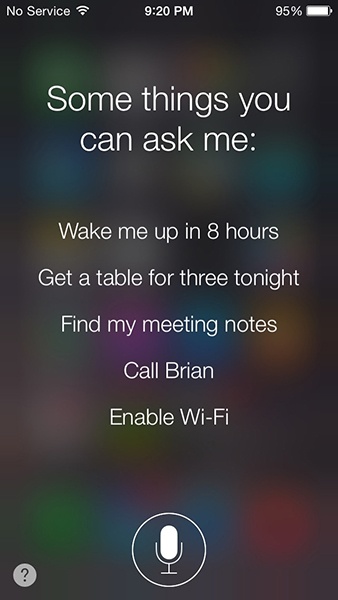
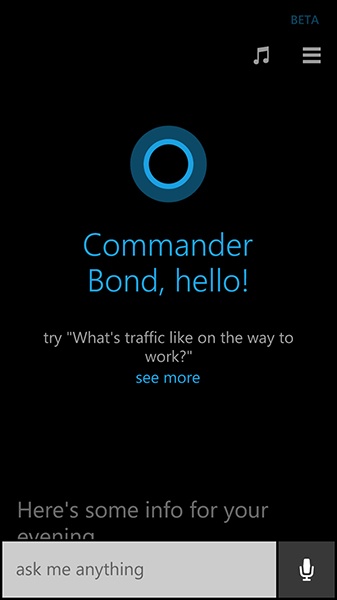
As mentioned in Chapter 2, doing nothing is sometimes a fine design choice. In these cases, it’s clear to users that they were not heard, and they’ll generally try again.
These examples—wherein the system does not explicitly prompt the user on an NSP timeout—illustrate the different modes of VUIs that are common today. Many of these virtual assistants are still in “one-off” mode: they expect the user to say something, and respond to it, and generally the conversation is over, until the user initiates a new request. In the IVR world, the user is in the middle of a dialog, and would not be able to advance without getting more input, so prompting the user on an NSP timeout makes more sense.
Another case (as mentioned in Chapter 2 and Chapter 3) for which doing nothing is fine is when you have a video or avatar. If the system doesn’t hear you, it continues to look expectantly, which is a common cue in human conversation that the person you’re speaking to did not hear you.
Is it important, however, to do more for the NSP event when the user is stuck. If you’re in a conversational system with an avatar and multiple NSP timeouts have been triggered, give the user a way out. If the system already has a graphical user interface (GUI) displayed (such as buttons on the screen), that is sufficient. GUIs can wait until the user performs an action—think about a website; there is no timeout there (unless you’re buying concert tickets).
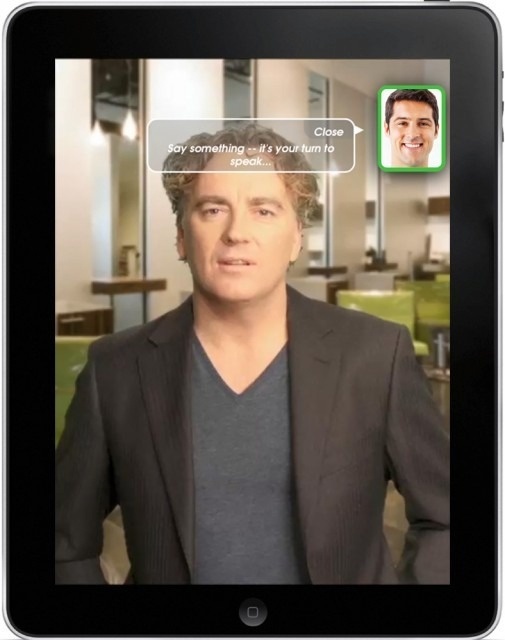
But in a voice-only system, employ “just in time” help. One example comes from a Volio-created iPad app that uses prerecorded video (http://bit.ly/2hcpvv4/). The app simulates a conversation with one of Esquire magazine’s columnists, Rodney Cutler, giving advice about hair products. During the conversation, the user’s face is shown in the picture-in-picture window in the upper-right corner. When it’s time for the user to speak, the box around their face lights up in green (Figure 4-5).
If no speech is detected, nothing happens—the actor continues to engage in “active listening,” nodding occasionally and looking at the user.
If multiple NSP timeouts have been detected in the first state, the app throws up a caption: “Say something—it’s your turn to speak!”
In another one of the Esquire conversations, users speak with columnist Nick Sullivan about what to wear on a date. This example shows what happens later on in the app, after multiple misrecognitions or NSP timeouts. First, the icon in the upper-right corner flashes gently. When the user taps it, a drop-down list of possible options appears, letting the user use touch to proceed (Figure 4-6). It then disappears.

While designing your system, spend some time thinking about why the NSP timeout might have been triggered. First, although the system thinks it did not hear any speech, it could be mistaken. It’s possible a user did speak, but it was not picked up by the recognizer.
Some designers create prompts that say things like “Speak louder” or “Get closer to the microphone.” But these can be very frustrating: if the user spoke too softly to be heard, telling them to speak louder only encourages them to over-articulate individual words, and this rarely solves the recognition problem. Instead, design around how to get the user to the next step. Often, this means letting users repeat themselves, or after multiple NSP timeouts, providing an alternative way to give input.
There are times, of course, when the user really did not say anything. Again, with your designer hat on, consider why this might be. If your data shows there is a particular place in your app in which users don’t speak, examine the interaction more closely. Here’s an example of an app that allows users to pay their Internet service provider (ISP) bills, with a question that leads to frequent NSP timeouts. The following example shows how to handle it poorly:
ISP VUI
What’s your account number?
USER
[silence]
ISP VUI
I’m sorry, I didn’t hear anything. Please say your account number.
USER
[silence]
ISP VUI
I still didn’t hear anything. Please say your account number.
As you can imagine, this does not lead to a successful outcome. The reason is because the user is given no help. The system simply repeats the question.
Why do you think this particular question led to a lot of NSP timeouts? Imagine the user is trying to pay their balance, but they don’t know their account number. What can they do? Here’s an example that lets them keep going:
ISP VUI
What’s your account number?
USER
[silence]
ISP VUI
Sorry, I didn’t get that. Your account number can be found at the top of your statement. Please say or type it in, or say, “I don’t know it.”
USER
I don’t know it.
ISP VUI
No problem. We can look it up with your phone number and address instead...
What was better about this example? First, it lets the user know where they can find their account number, if they have their statement. Second, it lets the user continue another way, if they don’t know or can’t find their account number.
Too much speech
Another timeout (used less frequently) is too-much-speech (TMS). This is triggered in the case of a user talking for a very long time, with no pauses that would have normally triggered the end-of-speech timeout. For most systems, it’s not generally necessary to handle this instance, because the user will need to take a breath at some point. It’s a good idea to still be on the lookout for these events in deployed applications because it might indicate that the recognizer is triggering on nonsalient speech, and you need to determine why.
However, if you find yourself designing a system that encourages users to speak for lengthy segments, and the length of utterances goes on too long, you can institute a TMS timeout and cut off the user in order to move on in the conversation. It’s best to look at data to determine your TMS timeout, but you can begin with something that’s not too short (and would cut users off too easily), such as 7 to 10 seconds.
N-Best Lists
Moving on from types of timeouts, let’s look more closely at what the system returns when it does recognize something.
A recognition engine does not typically return just one result for what it thinks the user said. Instead, it returns what’s referred to as an N-best list, which is a list of what the user might have said, ordered by likelihood (usually the top 5 or 10 possibilities), as well as the confidence score. Suppose that you’re designing a fun VUI app that lets people talk about their favorite animal:
MY FAVORITE ANIMAL VUI
So, I really want to know more about what animals you love. What’s your favorite?
USER
Well, I think at the moment my favorite’s gotta be...kitty cats!
OK, let’s take a peek behind the scenes now. At this point, the ASR tool will be returning a list of what it actually recognized, and the app must decide what to do next. Let’s look at the N-best list, which begins with the utterance about which it is the most confident. Note that speech recognition engines do not always return capitalization or punctuation:
WELL I THINK AT THE MOMENT MY FAVORITES GOT TO BE FIT AND FAT
WELL I THINK AT THE MOMENT BY FAVORITES GOTTA BE KITTY CATS
WELL I HAVE AT THE MOMENT MY FAN IS OF THE KITTY
WELL I HAVE AT THE MOMENT MY FAN IS OF THE KITTY BAT
WELL THAT THE MOMENT MY FAVORITE IS GOT TO BE KIT AND CAT
You’ve designed your system to look for animal names, and have an entire list of valid examples, including “cat,” “dog,” “horse,” “penguin,” “caracal,” and so on. If your VUI looked only at the first item in the N-best list, it would fail to make a match, and return a “no match” to the system, leading to prompt the user with something such as, “I’m sorry, I didn’t get that...what’s your favorite animal?”
Instead, what if we take advantage of our N-best list? When the first one results in no match, move on to the next—and there we find “cat.” Success!
Another way the N-best list is useful is when users are correcting information. Without the N-best list, you might continue suggesting the same incorrect option, over and over:
As you might imagine, that becomes annoying fast. If your VUI takes advantage of the N-Best list, however, you can put rejects on a skip list; thus, if Austin is the number one item the next time, move to the next one on the list.
The Challenges of Speech Recognition
We’ve talked about the ways you can harness the best features of speech recognition engines. Now, we need to talk about the places where the technology is not quite there yet.
Although some statistics show ASR has greater than 90 percent accuracy, keep in mind this is under ideal conditions. Ideal conditions typically mean an adult male in a quiet room with a good microphone.
Then we have the real world...
This section covers some of the challenges you’ll face that are unique to designing VUIs. Many of these are, as a VUI designer, out of your control. Besides waiting for the technology to improve, your job is to know these things exist and do your best to design around them.
Noise
One of the most difficult challenges for ASR tools is handling noise. This includes constant noise, such as that heard while driving on the freeway, or sitting in a busy restaurant or near a water fountain. It can also include noise that occurred just when the user spoke, such as the bark of a dog or vegetables hitting a hot frying pan while cooking in the kitchen.
Other challenges include side speech (when the user talks to a friend or coworker as an aside, while the app is listening), a television on in the background, or multiple people speaking at the same time.
As I mentioned just a moment ago, there is not a lot you can do about these challenges as the VUI designer, so the best thing to do is remember your user will have times when, for whatever reason, the system did not understand her—all you can do is follow the techniques described in this book to help alleviate this as much as possible. Occasionally apps try to guess what the issue is and instruct the user to move to a less noisy environment, get closer to the mic, and so on, but there is too much danger in guessing wrong and annoying your user with these suggestions. Instead, focus on providing help via escalating error behavior and offering other ways than voice for the user to continue.
The technology continues to improve remarkably. I have been in crowded, noisy restaurants with a band playing, and the ASR in my phone app still managed to understand a search query. Improved microphone direction on mobile phones is getting better, as well, which helps a lot.
Multiple Speakers
A poster named danieltobey on the website Reddit explained why he disabled allowing his phone to be woken up by saying “Ok Google”:
I work in a small office with a few other people, each of whom own Android smartphones. One day we realized that all of us had the “Ok Google” phrase enabled on our phones. Every time any of us said “OK Google” louder than a whisper (quiet office), all of our phones would wake up and start listening.
Needless to say, shortly thereafter all of us disabled this feature on our phones. Although it was nice to be able to say, “Ok Google, remind me to bring my lunchbag home later today,” it wasn’t as nice to have everyone else be reminded to bring my lunchbag home, as well.
Although new technology is evolving that will allow users to train their device to only respond to their own voice (as of this writing, Google has a primitive version of this running), discerning who is speaking is still a challenge for VUIs. If the user is in the middle of a query (“Hey, Siri, can you please tell me the top-rated restaurants in Walnut Creek, California”) and your coworker starts talking, how does the computer know who to listen to?
Additionally, as Karen Kaushansky pointed out in her 2016 talk at the O’Reilly Design Conference, there is a corollary issue: which device should respond when I make a request? Imagine you have an Apple Watch, an iPhone, and your car responds to voice commands, too. If you’re driving and you say, “Tell me the score of last night’s game,” which device (or vehicle) should respond (Figure 4-7)?

The answer is simple: whichever one is appropriate. I cover this topic in more detail in Chapter 8.
Children
At this time, children (especially very young children) are much more difficult for ASR tools to recognize accurately. Part of that is because children have shorter vocal tracts, and thus higher pitched-voices, and there is much less data for that type of speech (although that is changing). Another reason is because young children are more likely to meander, stutter, have long pauses, and repeat themselves.
If you’re designing an app specifically for kids, keep this in mind. Two common design practices are useful here:
When designing games or other conversational apps, allow interactions in which it’s not vital to understand 100 percent perfectly to move on. For example, Mattel and ToyTalk’s Hello Barbie (Figure 4-8) asks “What would you like to be when you grow up?” In addition to having responses for things it recognizes confidently, such as “veterinarian” and “CEO of a tech startup,” it could have a general response for when there is a no match, such as having Barbie say, “Sounds good. I want to be a space horticulturalist!” The conversation moves naturally along, even if a specific response was not provided.
For cases in which the information is needed, offer graphical alternatives. For example, a pain management app might ask kids where it hurts; offer a graphic of the human body for kids to identify where the pain is felt as well.
These strategies apply to adults for users of all ages but can be particularly helpful for kids.

Names, Spelling, and Alphanumeric
Some specific types of responses are more difficult for ASR tools than others. Very short phrases such as “yes” and “no” are much more difficult to recognize than longer ones, such as “Yes, I will” and “No, thank you.” Shorter utterances simply have less data for the tool to process. Encouraging your user to speak naturally rather than robotically can often result in higher recognition accuracy.
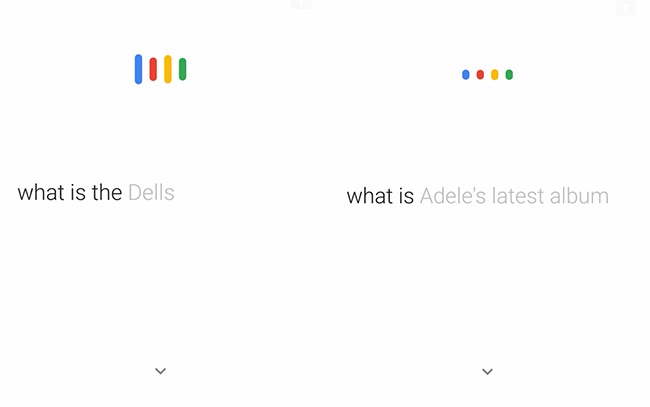
Nowadays, another reason is that the more context the ASR tool has, the better. ASR tools have learned a great deal about language and what people actually say, and they use this information to improve their models. As you speak, the tool is modifying its recognition result, as demonstrated in Figure 4-9.
Names, spelling, and alphanumeric strings are also tough. This is when having a GUI can be extremely valuable, because you can ask users to type these sorts of items, ensuring better accuracy. Names are tricky because there is such an enormous variety and many ways to spell the same name. Take “Cathy,” for example. If I say my name and the system recognized “Kathy,” and then tries to look up my reservation, it will fail. Even people have difficulty understanding names spelled one letter at a time; hence, the need for the “phonetic alphabet” that we often hear used by military and law enforcement personnel—alpha, bravo, Charlie, and so on.
If your user chooses to say those items—or if you have no GUI option available—your best bet is to take advantage of known data. Some examples of this include the following:
Credit card checksums (an algorithm to determine if a sequence of numbers is a valid credit card number)
List of registered user names
Postal code verification (e.g., in the United Kingdom, determining if a given postal code, such as NG9 5BL, follows a valid postcode format)
Cities closest to the current known location
By using these prepopulated lists and contexts, you can throw out the invalid results at runtime, and prioritize which ones are more likely.
Data Privacy
When users are finally trying out your app and you begin to collect data, it’s a very exciting time. You’ll be eager to see what people say to your system, and to use that information to improve it. But ensure that you have basic privacy checks in place. You might have the best of intentions, but that doesn’t make it OK.
Don’t store data that wasn’t meant for you. If you have a device that is constantly listening for a wake word, do not keep what the user says that doesn’t come before the wake word. Users expect and deserve privacy, and this data should not be preserved or stored, even anonymously. Given that more and more speech-activated devices are being used in homes, it’s important to put standards in place that prioritize privacy, and will reassure users.
The Amazon Echo is always listening for its wake word “Alexa,” but this speech recognition is performed locally, on the device. The audio is thrown away unless and until “Alexa” has been recognized, at which point the cloud-based recognition takes over. The Jibo family robot follows the same approach. It’s always listening, but until you say, “Hey, Jibo,” it won’t store your speech.
Mattel and ToyTalk’s interactive Hello Barbie only listens when her belt buckle is pushed on (push-to-talk), so it does not listen in on all the conversations the child might be having.
For data that does apply to your system—that is, the user is talking to your app/device—make sure it is stripped of all information that could tie it to the user. You can keep audio samples, but do not associate those with account numbers, birthdays, and so on. You should also consider stripping sensitive information from recognition results in application logs.
Conclusion
As a VUI designer, it’s important to understand the underpinnings of the technology for which you’re designing. Knowing the strengths and weaknesses of ASR tools can put your app ahead of the others in terms of performance. Having a system with good recognition accuracy is only part of the story; the design around what’s recognized plays a crucial part in a good user experience.
Understanding barge-in, timeouts, endpoint detection, and the challenges of different environments will help you to create the best VUI possible.
Get Designing Voice User Interfaces now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

