Chapter 4. Examples of Approaches to Date
Gestures, in love, are incomparably more attractive, effective, and valuable than words.
Francois Rabelais
Not All Gestures Are Created Equal
The gestures we are using here are a bit more primitive, less culturally loaded, and easy to master. But first, a brief history of using gestures in human-computer-interface design.
In the 1980s, NASA was working on virtual reality (VR), and came up with the dataglove—a pair of physically-wired up gloves that allowed for direct translation of gestures in the real world, to virtual hands shown in the virtual world. This was a core theme that continues in VR to this day.
In 2007 with the launch of Apple’s iPhone, gesture-based interaction had a renaissance moment with the introduction of the now ubiquitous “pinch-to-zoom” gesture. This has continued to be extended using more fingers to mean more types of actions.
In 2012, Leap Motion introduced a small USB-connected device that allows a user’s hands to be tracked and mapped to desktop interactions. This device later became popular with the launch of Oculus’ Rift DK1, with developers duct-taping the Leap to the front of the device in order to get their hands into VR. This became officially supported with the DK2.
In 2014 Google launched Project Tango, its own device that combines a smartphone with a 3-D depth camera to explore new ways of understanding the environment, and gesture-based interaction.
In 2015, Microsoft announced the Hololens, the company’s first mixed reality (MR) device, and showed how you could interact with the device (which uses Kinect technology for tracking the environment) by using gaze, voice, and gestures. Leap Motion announced a new software release that further enhanced the granularity and detection of gestures with its Leap Motion USB device. This allowed developers to really explore and fine-tune their gestures, and increased the robustness of the recognition software.
In 2016, Meta announced the Meta 2 headset at TED, which showcases its own approach to gesture recognition. The Meta headset utilizes a depth camera to recognize a simple “grab” gesture that allows the user to move objects in the environment, and a “tap” gesture that triggers an action (which is visually mapped as a virtual button push).
From these high-profile technological announcements, one thing is clear: gesture recognition will play an increasingly important part in the future of MR, and the research and development of technologies that enable ever more accurate interpretations of human motion will continue to be heavily explored. For the future MR designer, one of the more interesting areas of research might be the effect of gesture interactions on physical fatigue—everything from RSI that can be generated from small, repetitive micro interactions, all the way to the classic “gorilla arm” (waving our limbs around continuously), even though having no tangible physical resistance when we press virtual buttons—will generate muscular pain over time. As human beings, our limbs and muscular structure is not really optimized for long periods of holding our arms out in front of our bodies. After a short period of time, they begin to ache and fatigue sets in. Thus, other methods of implementing gesture interactions should be explored if we are to adopt this as a potential primary input. We have excellent proprioception; that is, we know where our limbs are in relation to our body without visual identification, and we know how to make contact with that part of our body, without the need for visual guidance. Our sense of touch is acute, and might offer a way to provide a more natural physical resistance to interactions that map to our own bodies. Treating our own bodies as a canvas to which to map gestures is a way to combat the aforementioned fatigue effects because it provides physical resistance, and through touch, gives us tactile feedback of when a gesture is used.
Eye Tracking: A Tricky Approach to the Inference of Gaze-Detection
An eye for an eye.
One of the most important sensory inputs for human beings is our eyes. They allow us to determine things like color, size, and distance so that we can understand the world around us. There is a lot of physical variance between different people’s eyes, and this creates a challenge for any kind of MR designer—how to interface their specific optical display with our eyeballs successfully.
One of the biggest challenges for MR is matching our natural ability to visually traverse a scene, where our eyes automatically calculate the depth of field, and correctly focus on any objects at a wide range of distances in our FoV (Figure 4-1). Trying to match this mechanical feat of human engineering is incredibly difficult when we talk about display technologies. Most of the displays we have had around us for the past 50 years or so have been flat. Cinema, television, computers, laptops, smartphones, tablets; we view them all at a given distance from our eyes, with 2-D user interfaces. Aside from the much older CRT display tech, LCD screens have dominated the computing experience for the past 10 to 15 years. And this has been working pretty well with our eyes—until the arrival of MR.
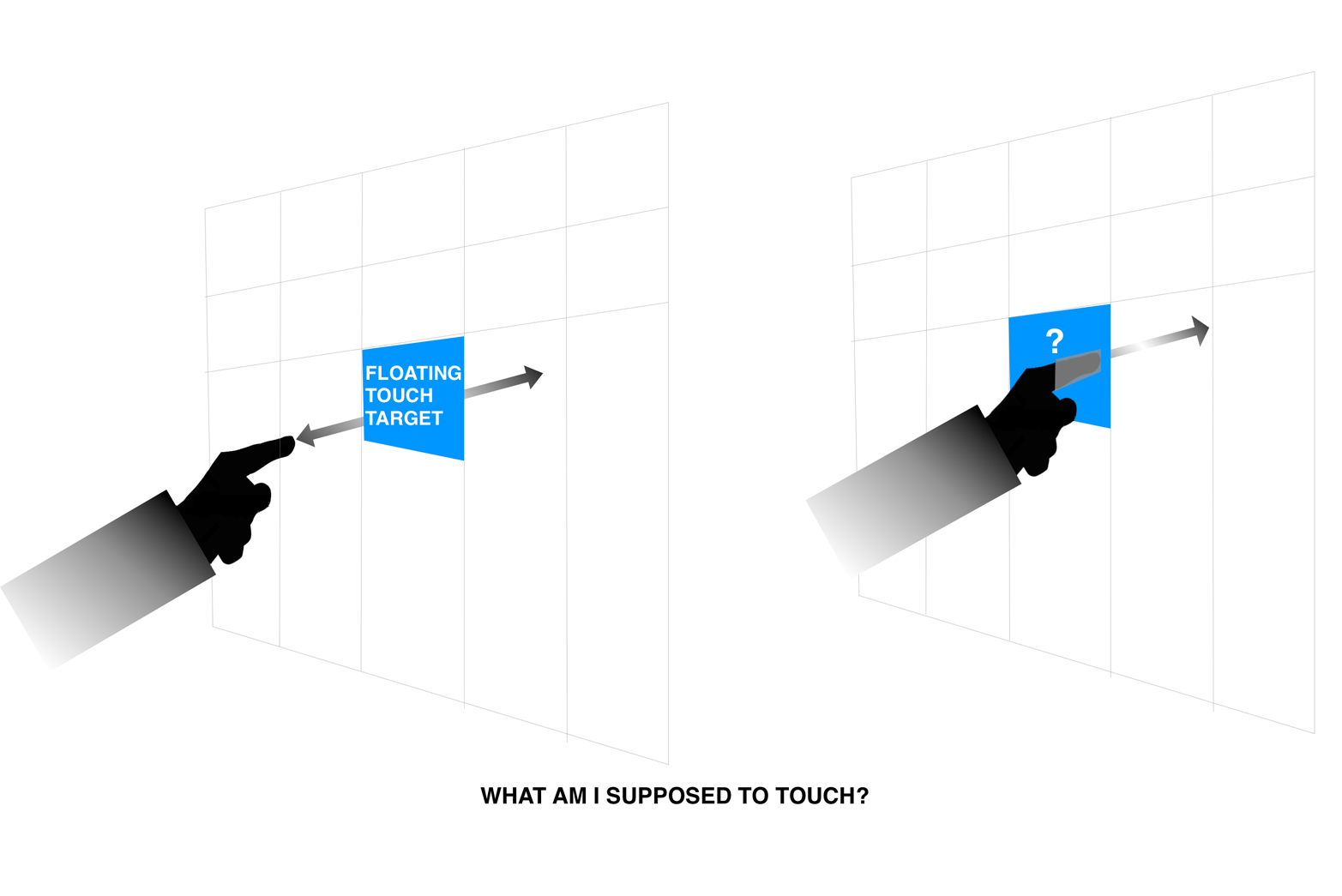
Figure 4-1. This diagram proves unequivocally that we’re just not designed for this
When the Oculus Rift VR headset launched on Kickstarter, it was heralded as a technological breakthrough. At $350, it was orders-of-magnitude cheaper than the insanely expensive VR headsets of yore. One of the reasons for this was the smartphone war dividends: access to cheap LCD panels that were originally created for use in smartphones. This allowed the Rift to have (at the time) a really good display. The screen was mounted inside the headset, close to the eyes, which viewed the screen through a pair of lenses in order to change the focal distance of the physical display so that your eyes could focus on it correctly.
One of the side effects of this approach is that even though a simulated 3-D scene can be shown on the screen, our eyes actually don’t change focus and, instead, are locked to a single near-focus. Over time this creates eye strain, which is commonly referred to as vergence-accommodation conflict (see Figure 4-2).
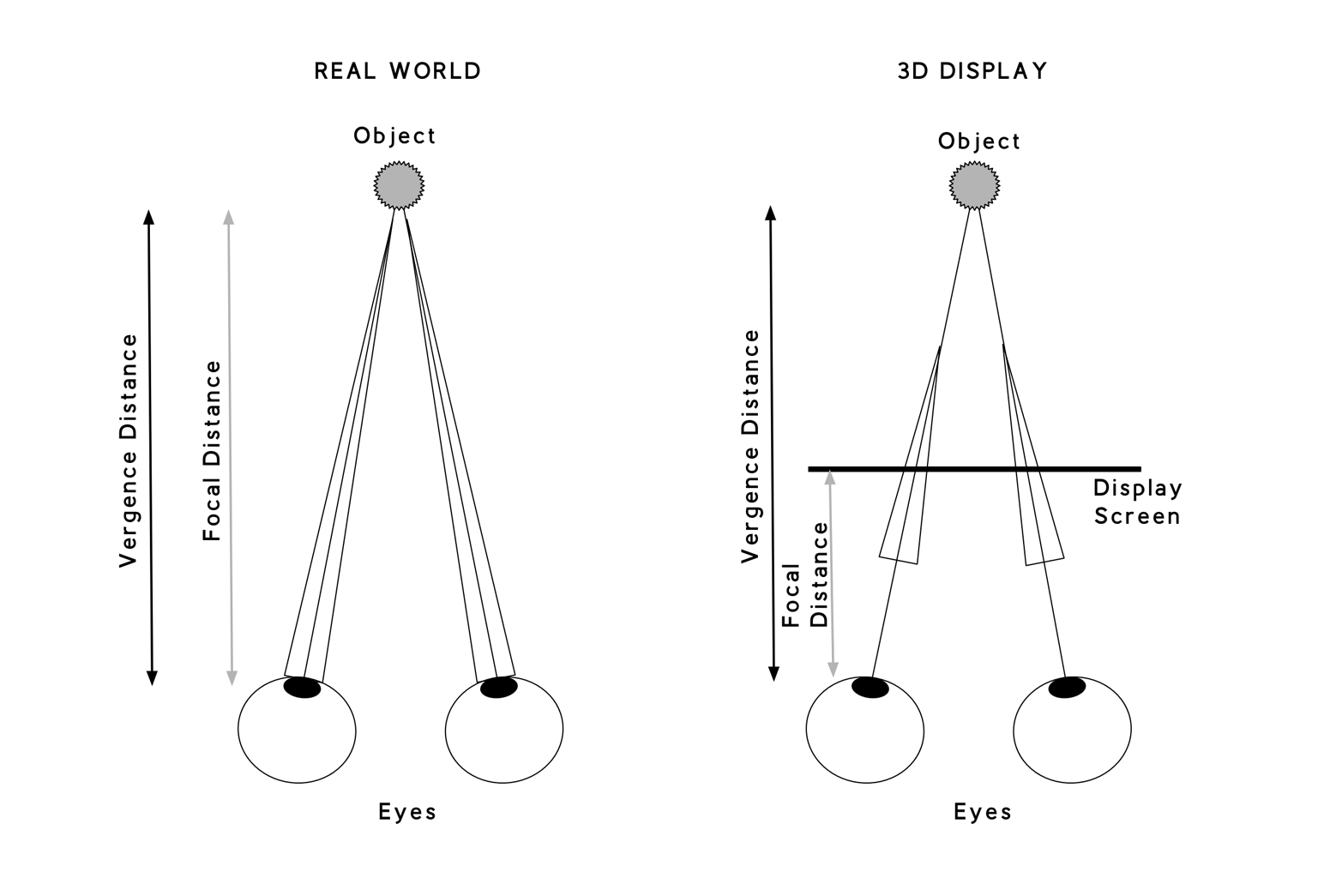
Figure 4-2. Vergence-accomodation conflict
In the real world, we constantly shift focus. Things that are not in focus appear to us as out of focus. These temporal cues help us understand and perceive depth. In the virtual world, everything is in focus all the time. There are no out-of-focus parts of a 3-D scene. In VR headsets, you are looking at a flat LCD display, so everything is perfectly in focus all the time. But in MR, a different challenge is found—how do you view a virtual object in context and placement in the physical world? Where does the virtual object “sit” in the FoV? This is a challenge more for the technologies surrounding optical displays, and in many ways, the only way to overcome this is by using a more advanced approach to optics
Enter the light field!
Of Light Fields and Prismatics
Most conventional displays utilize a single field of light; that is, all light arrives at the same time, spread across the same plane. But light field technology changes that, and it could potentially eliminate the issue of vergence-accommodation conflict and depth-of-field issues. One particular company is attempting to fix this problem, and it has the deep pockets needed to do so. Developing new kinds of optical technologies is neither cheap nor easy, so Magic Leap has decided to build its own optical system from scratch in an effort to make the most advanced display technology the world has ever seen. What little we do know about Magic Leap’s particular approach is that it utilizes a light field that is refracted at differing wavelengths through the use of a prismatic lens array. Rony Abovitz, the CEO of Magic Leap, often enthuses about a new “cinematic reality” coming with their technology.
Computer Vision: Using the Technologies That Can “Rank and File” an Environment
Seeing Spaces
Computer vision (CV) is an area of scientific research that, again, could take up an entire set of reports alone. CV is a technological method of understanding images and performing analysis to help software understand the real world and ultimately help make decisions. It is arguably the single most important and dependent technological aspect of MR to date. Without CV, MR is rendered effectively useless. With that in mind, there is no singular approach to solving the problem of “seeing spaces,” and there are many variants of what is known as simultaneous localization and mapping (SLAM) such as dense tracking and mapping (DTAM), parallel tracking and mapping (PTAM), and, the newest variant, semi-direct monocular visual odometry (SVO). As a designer, understanding the capabilities that each one of these approaches affords us, allows for better-designed experiences. For example, if I wanted to show to the wearer an augmentation or object at a given distance, I need to know what kind of CV library is used, because they are not all the same. Depth tracking CV libraries will only detect as far as 3 to 4 meters away from the wearer, whereas SVO will detect up to 300 meters. So knowing the technology you are working with is more important than ever. SVO is especially interesting because it was designed from the ground up as an incredibly CPU-light library that can run without issue on a mobile device (at up to 120 FPS!) to provide unmanned aerial vehicles (UAVs), or drones, with a photogrammetric way to navigate urban environments. This technology might enable long-throw CV in MR headsets; that is, the ability for the CV to recognize things at a distance, rather than the limiting few meters a typical depth camera can provide right now.
One user-experience side effect of short-throw or depth camera technology is that if the MR user is traversing the environment, the camera does not have a lot of time to recognize, query, and ultimately push contextual information back to the user. It all happens in a few seconds, which can have an uncalming effect on the user, being hit by rapid succession of information. Technologies like SVO might help to calm the inflow because the system can present information of a recognized target to the user in good time, well before the actual physical encounter takes place.
The All-Seeing Eye
When most people notice a camera lens pointing at them, something strange happens—it’s either interpreted as an opportunity to be seen, to perform, bringing out the inner narcissism that many enjoy flaunting and watching, or the reaction is adverse and something more akin to panic—an invasion of privacy, of being watched, observed, and monitored. Images of CCTV, Orwellian dystopias, and other terrifying futures spring to mind. Most of these reactions—both good and bad—are rooted in the idea of the self; of me, as being somewhat important. But what if those camera lenses didn’t care about you? What if cameras were just a way for computers to see? This is the deep-seated societal challenge that besets any adoption of CV as a technological enabler. How do we remove the social stigma around technology that can watch you? The computer is not interested in what you are doing for its own or anyone else’s amusement or exploitation, but to best work out how to help you do the things you want to do. If we allowed more CV into our lives, and allow the software to observe our behavior, and see where routine tasks occur, we might finally have technology that helps us—when it makes sense—to interject into a situation at the right time, and to augment our own abilities when it sees us struggling. A recent example of this is Tesla’s range of electric cars. The company uses CV and a plethora of sensors both inside and outside the vehicle to “watch” what is happening around the vehicle. Only recently, a Tesla vehicle drove its owner to a hospital after the driver suffered a medical emergency and engaged Autonomous Mode on the vehicle. This would not have been possible without the technology, and the human occupant trusting the technology.
Right now there is a lot of interest in Artificial Intelligence (AI) to automate tasks through the parsing and processing of natural language in an attempt to free us from the burden of continually interacting with these applications—namely, pressing buttons on a screen. All these recent developments are a great step forward, but right now it still requires the user to push requests to the AI or Bot. The Bot does not know much about where you are, what you are doing, who you are with, or how you are interacting with the environment. The Bot is essentially blind and requires the user to describe the things to it in order to provide any value.
MR allows Bots to see. With advanced CV and embedded camera sensors in a headset, AI would finally be able to watch and learn through natural human behaviors, as well as language, allowing computers to pull contextual information as necessary. The potential augmentation of our skills could revolutionize our levels of efficiency—freeing up our minds from pushing requests to systems and awaiting responses, to getting observational and contextual data as a way to help us make better informed decisions. Of course, none of this would be possible without the Internet, and, as was mentioned earlier in this report, the Internet will take center stage in helping couple the CV libraries that run on the headset with data APIs that can be queried in real time for information. The incoming data that flows back to the headset will need to be dealt with, and this is where good interface design matters—to handle the flow of information such that it stays relevant to the user’s context, and to purge information in a timely manner so as to not overwhelm the user. This is the real challenge that awaits the future MR designer: how to attune for temporality.
Get Designing for Mixed Reality now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

