Chapter 6. Sharded Services
In the previous chapter, we saw the value of replicating stateless services for reliability, redundancy, and scaling. This chapter considers sharded services. With the replicated services that we introduced in the preceding chapter, each replica was entirely homogeneous and capable of serving every request. In contrast to replicated services, with sharded services, each replica, or shard, is only capable of serving a subset of all requests. A load-balancing node, or root, is responsible for examining each request and distributing each request to the appropriate shard or shards for processing. The contrast between replicated and sharded services is represented in Figure 6-1.
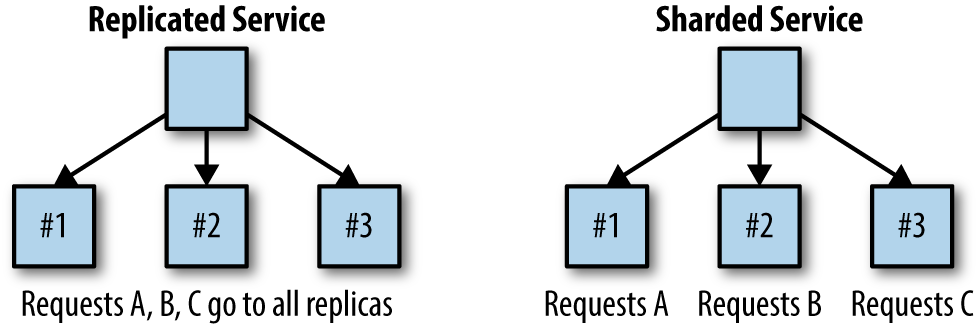
Figure 6-1. Replicated service versus sharded service
Replicated services are generally used for building stateless services, whereas sharded services are generally used for building stateful services. The primary reason for sharding the data is because the size of the state is too large to be served by a single machine. Sharding enables you to scale a service in response to the size of the state that needs to be served.
Sharded Caching
To completely illustrate the design of a sharded system, this section provides a deep dive into the design of a sharded caching system. A sharded cache is a cache that sits between the user requests and the actually frontend implementation. A high-level ...
Get Designing Distributed Systems now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

