Chapter 7. Transactions
Some authors have claimed that general two-phase commit is too expensive to support, because of the performance or availability problems that it brings. We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
James Corbett et al., Spanner: Google’s Globally-Distributed Database (2012)
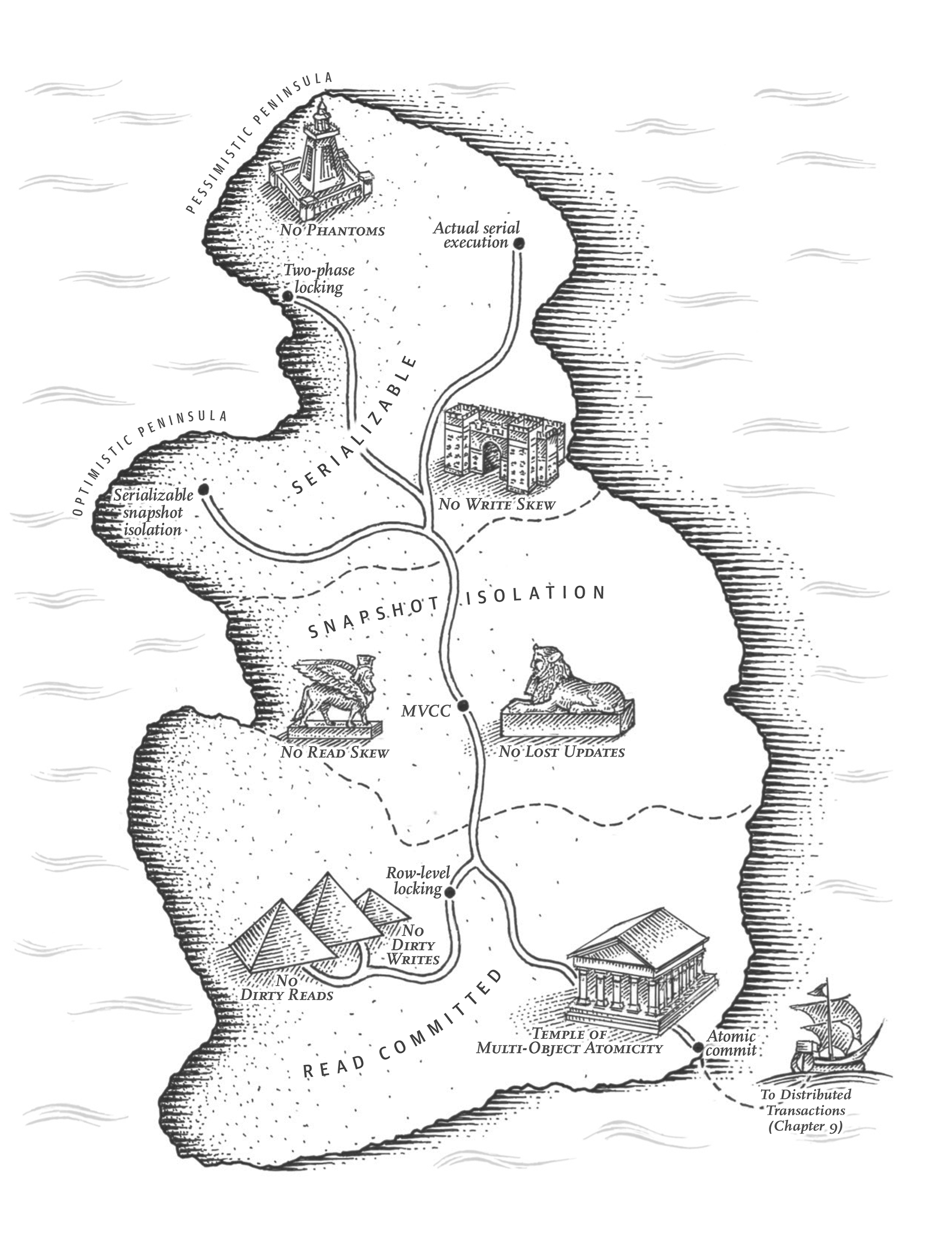
In the harsh reality of data systems, many things can go wrong:
-
The database software or hardware may fail at any time (including in the middle of a write operation).
-
The application may crash at any time (including halfway through a series of operations).
-
Interruptions in the network can unexpectedly cut off the application from the database, or one database node from another.
-
Several clients may write to the database at the same time, overwriting each other’s changes.
-
A client may read data that doesn’t make sense because it has only partially been updated.
-
Race conditions between clients can cause surprising bugs.
In order to be reliable, a system has to deal with these faults and ensure that they don’t cause catastrophic failure of the entire system. However, implementing fault-tolerance mechanisms is a lot of work. It requires a lot of careful thinking about all the things that can go wrong, and a lot of testing ...
Get Designing Data-Intensive Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

