Imagine that we have some function, Q, that can estimate the reward for taking an action:
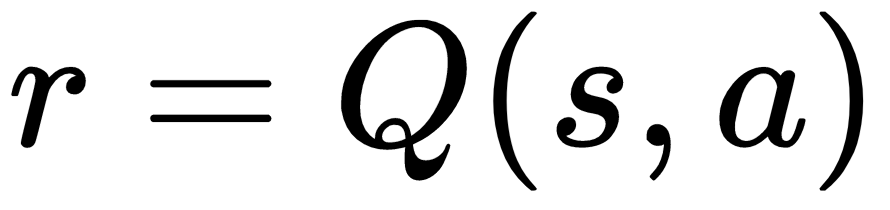
For some state s, and action a, it generates a reward for that action given the state. If we knew all the rewards for our environment, we could just loop through Q and pick the action that gives us the biggest reward. But, as we mentioned in the previous section, our agent can't know all the reward states and state probabilities. So, then our Q function needs to attempt to approximate the reward.
We can approximate this ideal Q function with a recursively defined Q function called the Bellman Equation:
In this case, r0 is the reward for the ...

