This book has as subtitle Normal Forms and All That Jazz. Clearly some explanation is needed! First of all, of course, I’m talking about design theory, and everybody knows normal forms are a major component of that theory; hence the first part of my subtitle. But there’s more to the theory than just normal forms, and that fact accounts for that subtitle’s second part. Third, it’s unfortunately the case that—from the practitioner’s point of view, at any rate—design theory is riddled with terms and concepts that seem to be difficult to understand and don’t seem to have much to do with design as actually done in practice. That’s why I framed the latter part of my subtitle in colloquial (not to say slangy) terms; I wanted to convey the idea, or impression, that although we’d necessarily be dealing with “difficult” material on occasion, the treatment of that material would be as undaunting and unintimidating as I could make it. But whether I’ve succeeded in that aim is for you to judge, of course.
I’d also like to say a little more on the question of whether design theory has anything to do with design as done in practice. Let me be clear: Nobody could, or should, claim that designing databases is easy. But a sound knowledge of theory can only help. In fact, if you want to do design properly—if you want to build databases that are as robust, flexible, and accurate as they’re supposed to be—then you simply have to come to grips with design theory. There’s just no alternative: at least, not if you want to claim to be a professional. Design theory is the scientific foundation for database design, just as the relational model is the scientific foundation for database technology in general. And just as anyone professionally involved in database technology in general needs to be familiar with the relational model, so anyone involved in database design in particular needs to be familiar with design theory. Proper design is so important! After all, the database lies at the heart of so much of what we do in the computing world; so if it’s badly designed, the negative impacts can be extraordinarily widespread.
Since we’re going to be talking quite a lot about normal forms, I thought it might be—well, not enlightening, perhaps, but entertaining (?)—to begin with a few quotes from the literature. The starting point for the whole concept of normal forms is, of course, first normal form (1NF), and so an obvious question is: Do you know what 1NF is? As the following quotes demonstrate (sources omitted to protect the guilty), a lot of people don’t:
To achieve first normal form, each field in a table must convey unique information.
An entity is said to be in the first normal form (1NF) when all attributes are single valued.
A relation is in 1NF if and only if all underlying domains contain atomic values only.
If there are no repeating groups of attributes, then [the table] is in 1NF.
Now, it might be argued that some if not all of these quotes are at least vaguely correct—but they’re all hopelessly sloppy, even when they’re generally on the right lines. (In case you’re wondering, I’ll be giving a precise and accurate definition of 1NF in Chapter 4.)
Let’s take a closer look at what’s going on here. Here again is the first of the foregoing quotes, now given in full:
To achieve first normal form, each field in a table must convey unique information. For example, if you had a Customer table with two columns for the telephone number, your design would violate first normal form. First normal form is fairly easy to achieve, since few folks would see a need for duplicate information in a table.
OK, so apparently we’re talking about a design that looks something like this:
Now, I can’t say whether this is a good design or not, but it certainly doesn’t violate 1NF. (I can’t say whether it’s a good design because I don’t know exactly what “two columns for the telephone number” means. The phrase “duplicate information in a table” suggests we’re recording the same phone number twice, but such an interpretation is absurd on its face. But even if that interpretation is correct, it still wouldn’t constitute a violation of 1NF as such.)
Here’s another one:
First Normal Form ... means the table should have no “repeating groups” of fields ... A repeating group is when you repeat the same basic attribute (field) over and over again. A good example of this is when you wish to store the items you buy at a grocery store ... [and the writer goes on to give an example, presumably meant to illustrate the concept of a repeating group, of a table called Item Table with columns called Customer, Item1, Item2, Item3, and Item4]:
Well, this design is almost certainly bad—what happens if the customer doesn’t purchase exactly four items?—but the reason it’s bad isn’t that it violates 1NF; like the previous example, in fact, it’s a 1NF design. And while it’s true that 1NF does mean, loosely, “no repeating groups,” a repeating group is not “when you repeat the same basic attribute over and over again.” (What it really is I’ll explain in Chapter 4, when I explain what 1NF really is.)
How about this one (a cry for help found on the Internet)? I’m quoting it absolutely verbatim, except that I’ve added some boldface:
I have been trying to find the correct way of normalizing tables in Access. From what I understand, it goes from the 1st normal form to 2nd, then 3rd. Usually, that’s as far as it goes, but sometimes to the 5th and 6th. Then, there’s also the Cobb 3rd. This all makes sense to me. I am supposed to teach a class in this starting next week, and I just got the textbook. It says something entirely different. It says 2nd normal form is only for tables with a multiple-field primary key, 3rd normal form is only for tables with a single-field key. 4th normal form can go from 1st to 4th, where there are no independent one-to-many relationships between primary key and non-key fields. Can someone clear this up for me please?
And one more (this time with a “helpful” response):
> It’s not clear to me what “normalized” means. Can you be specific about what normalization rules you are
> referring to? In what way is my schema not normalized?
Normalization: The process of replacing duplicate things with a reference to the original thing.
For example, given “john is-a person” and “john obeys army,” one observes that the “john” in the second sentence is a duplicate of “john” in the first sentence. Using the means provided by your system, the second sentence should be stored as “–>john obeys army.”
As I’m sure you noticed, the quotes in the previous section were expressed for the most part in the familiar “user friendly” terminology of tables, rows, and columns (or fields). In this book, by contrast, I’ll tend to favor the more formal terms relation, tuple (usually pronounced to rhyme with couple), and attribute. I apologize if this decision on my part makes the text a little harder to follow, but I do have my reasons. As I said in SQL and Relational Theory:[3]
I’m generally sympathetic to the idea of using more user friendly terms, if they can help make the ideas more palatable. In the case at hand, however, it seems to me that, regrettably, they don’t make the ideas more palatable; instead, they distort them, and in fact do the cause of genuine understanding a grave disservice. The truth is, a relation is not a table, a tuple is not a row, and an attribute is not a column. And while it might be acceptable to pretend otherwise in informal contexts—indeed, I often do exactly that myself—I would argue that it’s acceptable only if we all understand that the more user friendly terms are just an approximation to the truth and fail overall to capture the essence of what’s really going on. To put it another way, if you do understand the true state of affairs, then judicious use of the user friendly terms can be a good idea; but in order to learn and appreciate that true state of affairs in the first place, you really do need to come to grips with the formal terms.
To the foregoing, let me add that (as I said in the preface) I do assume you know exactly what relations, attributes, and tuples are!—though in fact formal definitions of these constructs can be found in Chapter 5.
There’s another terminological matter I need to get out of the way, too. The relational model is, of course, a data model. Unfortunately, however, this latter term has two quite distinct meanings in the database world.[4] The first and more fundamental one is this:
This is the meaning we have in mind when we talk about the relational model in particular: The data structures in the relational model are relations, of course, and the data operators are the relational operators projection, join, and the rest. (As for that “and so forth” in the definition, it covers such matters as keys, foreign keys, and various related concepts.)
The second meaning of the term data model is as follows:
In other words, a data model in the second sense is just a (logical, and possibly somewhat abstract) database design. For example, we might speak of the data model for some bank, or some hospital, or some government department.
Having explained these two different meanings, I’d like to draw your attention to an analogy that I think nicely illuminates the relationship between them:
A data model in the first sense is like a programming language, whose constructs can be used to solve many specific problems but in and of themselves have no direct connection with any such specific problem.
A data model in the second sense is like a specific program written in that language—it uses the facilities provided by the model, in the first sense of that term, to solve some specific problem.
It follows from all of the above that if we’re talking about data models in the second sense, then we might reasonably speak of “relational models” in the plural, or “a” relational model (with an indefinite article). But if we’re talking about data models in the first sense, then there’s only one relational model, and it’s the relational model (with the definite article).
Now, as you probably know, most writings on database design, especially if their focus is on pragma rather than the underlying theory, use the term “model,” or “data model,” exclusively in the second sense. But—please note carefully!—I don’t follow this practice in the present book; in fact, I don’t use the term “model” at all, except occasionally to refer to the relational model as such.
Now let me introduce the example I’ll be using as a basis for most of the discussions in the rest of the book: the familiar—not to say hackneyed—suppliers-and-parts database. (I apologize for dragging out this old warhorse yet one more time, but I believe that using essentially the same example in a variety of different books and publications can help, not hinder, learning.) Sample values are shown in Figure 1-1.[5] To elaborate:
Suppliers: Relvar S denotes suppliers.[6] Each supplier has one supplier number (SNO), unique to that supplier; one name (SNAME), not necessarily unique (though the SNAME values in Figure 1-1 do happen to be unique); one status value (STATUS), representing some kind of ranking or preference level among suppliers; and one location (CITY).
Parts: Relvar P denotes parts (more accurately, kinds of parts). Each kind of part has one part number (PNO), which is unique; one name (PNAME), not necessarily unique; one color (COLOR); one weight (WEIGHT); and one location where parts of that kind are stored (CITY).
Shipments: Relvar SP denotes shipments (it shows which parts are supplied, or shipped, by which suppliers). Each shipment has one supplier number (SNO), one part number (PNO), and one quantity (QTY). Also, I assume for the sake of the example that there’s at most one shipment at any one time for a given supplier and a given part, and so each shipment has a supplier-number/part-number combination that’s unique.
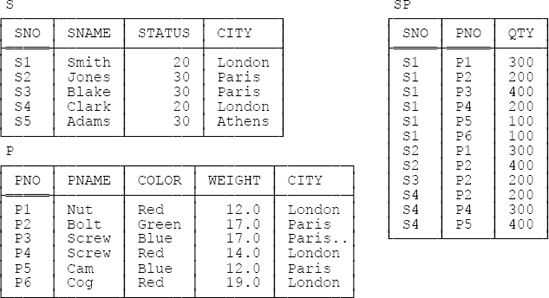
Before going any further, I need to review the familiar concept of keys, in the relational sense of that term. First of all, as I’m sure you know, every relvar has at least one candidate key. A candidate key is basically just a unique identifier; in other words, it’s a combination of attributes—often but not always a “combination” consisting of just a single attribute—such that every tuple in the relvar has a unique value for the combination in question. For example, with respect to the database of Figure 1-1:
Every supplier has a unique supplier number and every part has a unique part number, so {SNO} is a candidate key for S and {PNO} is a candidate key for P.
As for shipments, given the assumption that there’s at most one shipment at any one time for a given supplier and a given part, {SNO,PNO} is a candidate key for SP.
Note the braces, by the way; to repeat, candidate keys are always combinations, or sets, of attributes (even when the set in question contains just one attribute), and the conventional representation of a set on paper is as a commalist of elements enclosed in braces. Note: The useful term commalist can be defined as follows: Let xyz be some syntactic construct (for example, “attribute name”). Then the term xyz commalist denotes a sequence of zero or more xyz’s in which each pair of adjacent xyz’s is separated by a comma (as well as, optionally, one or more spaces before or after the comma or both).
Next, as I’m sure you also know, a primary key is a candidate key that’s been singled out in some way for some kind of special treatment. Now, if the relvar in question has just one candidate key, then it doesn’t make any real difference if we call that key primary. But if the relvar has two or more candidate keys, then it’s usual to choose one of them to be primary, meaning it’s somehow “more equal than the others.” Suppose, for example, that suppliers always have both a unique supplier number and a unique supplier name, so that {SNO} and {SNAME} are both candidate keys. Then we might choose {SNO}, say, to be the primary key.
Observe now that I said it’s usual to choose a primary key. Indeed it is usual—but it’s not 100 percent necessary. If there’s just one candidate key, then there’s no choice and no problem; but if there are two or more, then having to choose one and make it primary smacks a little bit of arbitrariness, at least to me. (Certainly there are situations where there don’t seem to be any good reasons for making such a choice. There might even be good reasons for not doing so. Appendix A elaborates on such matters.) For reasons of familiarity, I’ll usually follow the primary key discipline myself in this book—and in pictures like Figure 1-1 I’ll indicate primary key attributes by double underlining—but I want to stress the fact that it’s really candidate keys, not primary keys, that are significant from a relational point of view, and indeed from a design theory point of view as well. Partly for such reasons, from this point forward I’ll use the term key, unqualified, to mean any candidate key, regardless of whether the candidate key in question has additionally been designated as primary. (In case you were wondering, the special treatment enjoyed by primary keys over other candidate keys is mainly syntactic in nature, anyway; it isn’t fundamental, and it isn’t very important.)
More terminology: First, a key involving two or more attributes is said to be composite (and a noncomposite key is sometimes said to be simple). Second, if a given relvar has two or more keys and one is chosen as primary, then the others are sometimes said to be alternate keys (see Appendix A). Third, a foreign key is a combination, or set, of attributes FK in some relvar R2 such that each FK value is required to be equal to some value of some key K in some relvar R1 (R1and R2 not necessarily distinct).[7] With reference to Figure 1-1, for example, {SNO} and {PNO} are both foreign keys in relvar SP, corresponding to keys {SNO} and {PNO} in relvars S and P, respectively.
To repeat something I said in the preface, by the term design I mean logical design, not physical design. Logical design is concerned with what the database looks like to the user (which means, loosely, what relvars exist and what constraints apply to those relvars); physical design, by contrast, is concerned with how a given logical design maps to physical storage.[8] And the term design theory refers specifically to logical design, not physical design—the point being that physical design is necessarily dependent on aspects (performance aspects in particular) of the target DBMS, whereas logical design is, or should be, DBMS independent. Throughout this book, then, the unqualified term design should be understood to mean logical design specifically, barring explicit statements to the contrary.
Now, design theory as such isn’t part of the relational model; rather, it’s a separate theory that builds on top of that model. (It’s appropriate to think of it as part of relational theory in general, but it’s not, to repeat, part of the relational model per se.) Thus, design concepts such as further normalization are themselves based on more fundamental notions—e.g., the projection and join operators of the relational algebra—that are part of the relational model. (All of that being said, it could certainly be argued that design theory is a logical consequence of the relational model, at least in part. In other words, it would be inconsistent to agree with the relational model in general but not to agree with the design theory that’s based on it.)
The overall objective of logical design is to achieve a design that’s (a) hardware independent, for obvious reasons; (b) operating system and DBMS independent, again for obvious reasons; and finally, and perhaps a little controversially, (c) application independent (in other words, we’re concerned primarily with what the data is, rather than with how it’s going to be used). Application independence in this sense is desirable for the very good reason that it’s normally—perhaps always—the case that not all uses to which the data will be put are known at design time; thus, we want a design that’ll be robust, in the sense that it won’t be invalidated by the advent of application requirements that weren’t foreseen at the time of the original design. Observe that one important consequence of this state of affairs is that we aren’t (or at least shouldn’t be) interested in making design compromises for physical performance reasons. Design theory should never be driven by performance considerations.
Back to design theory as such. As we’ll see, that theory includes a number of formal theorems, theorems that provide practical guidelines for designers to follow. So if you’re a designer, you need to be familiar with those theorems. Let me quickly add that I don’t mean you have to know how to prove those theorems (though in fact the proofs are often quite simple); what I mean is, you have to know what the theorems say—i.e., you have to know the results—and you have to be prepared to apply those results. That’s the nice thing about theorems: Once somebody’s proved them, their results become available for anybody to use whenever they need to.
Now, it’s sometimes claimed, not entirely unreasonably, that all design theory really does is bolster up your intuition. What do I mean by this remark? Well, consider the suppliers-and-parts database. The obvious design for that database is the one illustrated in Figure 1-1; I mean, it’s “obvious” that three relvars are necessary, that attribute STATUS belongs in relvar S, that attribute COLOR belongs in relvar P, that attribute QTY belongs in relvar SP, and so on. But why exactly are these things obvious? Well, suppose we try a different design; suppose we move the STATUS attribute out of relvar S, for example, and into relvar SP (intuitively the wrong place for it, since status is a property of suppliers, not shipments). Figure 1-2 below shows a sample value for this revised shipments relvar, which I’ll call STP to avoid confusion:[9]
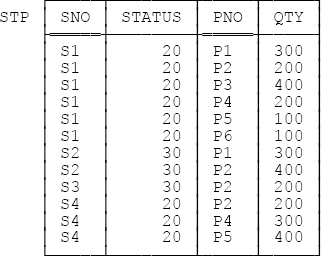
A glance at the figure is sufficient to show what’s wrong with this design: It’s redundant, in the sense that every tuple for supplier S1 tells us S1 has status 20, every tuple for supplier S2 tells us S2 has status 30, and so on.[10] And design theory tells us that not designing the database in the obvious way will lead to such redundancy, and tells us also (albeit implicitly) what the consequences of such redundancy will be. In other words, design theory is largely about reducing redundancy, as we’ll see. (As an aside, I remark that—partly for such reasons—the theory has been described, perhaps a little unkindly, as a good source of bad examples.)
Now, if design theory really does just bolster up your intuition, then it might be (and indeed has been) criticized on the grounds that it’s really all just common sense anyway. By way of example, consider relvar STP again. As I’ve said, that relvar is obviously badly designed; the redundancies are obvious, the consequences are obvious too, and any competent human designer would “naturally” avoid such a design, even if that designer had no explicit knowledge of design theory at all. But what does “naturally” mean here? What principles are being applied by that human designer in opting for a more “natural” (and better) design?
The answer is: They’re exactly the principles that design theory talks about (the principles of normalization, for example). In other words, competent designers already have those principles in their brain, as it were, even if they’ve never studied them formally and can’t put a name to them or articulate them precisely. So yes, the principles are common sense—but they’re formalized common sense. (Common sense might be common, but it’s not always easy to say exactly what it is!) What design theory does is state in a precise way what certain aspects of common sense consist of. In my opinion, that’s the real achievement—or one of the real achievements, anyway—of the theory: It formalizes certain commonsense principles, thereby opening the door to the possibility of mechanizing those principles (that is, incorporating them into computerized design tools). Critics of the theory often miss this point; they claim, quite rightly, that the ideas are mostly just common sense, but they don’t seem to realize it’s a significant achievement to state what common sense means in a precise and formal way.
As a kind of postscript to the foregoing, I note that common sense might not always be that common anyway. The following lightly edited extract from a paper by Robert R. Brown of Hughes Aircraft[11] illustrates the point. The author begins by giving “a simplified real example”—his words—involving an employee file (with fields for employee number, employee name, phone number, department number, and manager name) and a department file (with fields for department number, department name, manager name, and manager’s phone number), all with the intuitively obvious meanings. Then he continues:
The actual database on which this example is based had many more files and fields and much more redundancy. When the designer was asked his reasons for such a design, he cited performance and the difficulty of doing joins. Even though the redundancy should be clear to you in my example, it was not that evident in the design documentation. In large databases with many more files and fields, it is impossible to find the duplications without doing extensive information analysis and without having extended discussions with the experts in the user organizations.
Incidentally, there’s another quote I like a lot—in fact, I used it as an epigraph in SQL and Relational Theory—that supports my contention that practitioners really do need to know the theoretical foundations of their field. It’s from Leonardo da Vinci (and is thus some 500 years old!), and it goes like this (I’ve added the boldface):
Those who are enamored of practice without theory are like a pilot who goes into a ship without rudder or compass and never has any certainty where he is going. Practice should always be based upon a sound knowledge of theory.
If you’re like me, you’ll have encountered lots of design theory terms in the literature and live presentations and the like—terms such as projection-join normal form, the chase, join dependency, FD preservation, and many others—and I’m sure you’ve wondered from time to time exactly what they all mean. Thus, it’s one of my aims in this book to explain such terms: to define them carefully and accurately, to explain their relevance and applicability, and generally to remove any air of mystery that might seem to surround them. And if I’m successful in that aim, I’ll have gone a good way to explaining what design theory is and why it’s important (indeed, a possible alternative title for the book would be Database Design Theory: What It Is and Why You Should Care). Overall, it’s my goal to provide a painless introduction to design theory for database professionals. More specifically, what I want to do is:
Review, though from a possibly unfamiliar perspective, aspects of design you should already be familiar with
Explore in depth aspects you’re probably not already familiar with
Provide clear and accurate explanations and definitions (with plenty of examples) of all pertinent concepts
Not spend a lot of time on material that’s widely understood already, such as 2NF and 3NF[12]
All of that being said, I should say too that database design is not my favorite subject. The reason it’s not is that much of that subject is still somewhat ... well, subjective. As I said earlier, design theory is the scientific foundation for database design. Sadly, however, there are numerous design issues that the theory simply doesn’t address at all (yet). Thus, while the formal principles I’ll be describing in this book do represent the scientific part of design, there are other parts that, as I’ve put it elsewhere, are still more in the nature of an artistic endeavor. Indeed, one message of the book is precisely that we need more science in this field.
To put a more positive spin on matters, I’d like to draw your attention to the following. Design theory is (at least in part) about capturing the meaning of data, and as Codd himself once said in connection with that notion:[13]
[The] task of capturing (in a reasonably formal way) more of ... the meaning of data is a never-ending one ... The goal is nevertheless an extremely important one, because even small successes can bring understanding and order into the field of database design.
In fact, I’ll go further: If your design violates any of the known science, then, as I’ve written elsewhere (in a slightly different context), the one thing you can be sure of is that things will go wrong. And though it might be hard to say exactly what will go wrong, and it might be hard to say whether things will go wrong in a major or minor way, you know—it’s guaranteed—that they will go wrong. Theory is important.
This book grew in the writing; it turns out that, despite the slightly negative tone of some of the remarks in the previous section, there’s really quite a lot of good material to cover. What’s more, the material builds. Thus, while the first few chapters might seem to be going rather slowly, I think you’ll find the pace picks up later on. Part of the point is the number of terms and concepts that need to be introduced; the ideas aren’t really difficult, but they can seem a little overwhelming, at least until you’re comfortable with the terminology. For that reason, at least in some parts of the book, I’ll be presenting the material twice—first from an informal perspective, and then again from a more formal one. (As Bertrand Russell once memorably said: Writing can be either readable or precise, but not at the same time. I’m trying to have my cake and eat it too.)
It seems appropriate to close this chapter with another quote from Bertrand Russell:[14]
I have been accused of a habit of changing my opinions ... I am not myself in any degree ashamed of [that habit]. What physicist who was already active in 1900 would dream of boasting that his opinions had not changed during the last half century? ... The kind of philosophy that I value and have endeavoured to pursue is scientific, in the sense that there is some definite knowledge to be obtained and that new discoveries can make the admission of former error inevitable to any candid mind. For what I have said, whether early or late, I do not claim the kind of truth which theologians claim for their creeds. I claim only, at best, that the opinion expressed was a sensible one to hold at the time ... I should be much surprised if subsequent research did not show that it needed to be modified. [Such opinions were not] intended as pontifical pronouncements, but only as the best I could do at the time towards the promotion of clear and accurate thinking. Clarity, above all, has been my aim.
I’ve quoted this extract elsewhere: in the preface to my book An Introduction to Database Systems (8th edition, Addison-Wesley, 2004) in particular. The reason I mention this latter book is that it includes among other things a tutorial treatment of some of the material covered in more depth in the present book. But the world has moved on; my own understanding of the theory is, I hope, better than it was when I wrote that earlier book, and there are aspects of the treatment in that book that I would frankly now like to revise. One problem with that earlier treatment was that I attempted to make the material more palatable by adopting the fiction that any given relvar has just one key, which could then harmlessly be regarded as the primary key. But a consequence of that simplifying assumption was that several of the definitions I gave (e.g., of 2NF and 3NF) were less than fully accurate. This fact has led to a certain amount of confusion—partly my fault, I freely admit, but partly also the fault of people who took the definitions out of context.
The purpose of these exercises is to give some idea of the scope of the chapters to come, and also perhaps to test the extent of your existing knowledge. They can’t be answered from material in the present chapter alone.
1.1 Is it true that the relational model doesn’t require relvars to be in any particular normal form?
1.2 Should data redundancy always be eliminated? Can it be?
1.3 What’s the difference between 3NF and BCNF?
1.4 Is it true that every “all key” relvar is in BCNF?
1.5 Is it true that every binary relvar is in 4NF?
1.6 Is it true that every “all key” relvar is in 5NF?
1.7 Is it true that every binary relvar is in 5NF?
1.8 Is it true that if a relvar has just one key and just one other attribute, then it’s in 5NF?
1.9 Is it true that if a relvar is in BCNF but not 5NF, then it must be all key?
1.10 Can you give a precise definition of 5NF?
1.11 Is it true that if a relvar is in 5NF, then it’s redundancy free?
1.12 What precisely is denormalization?
1.13 What’s Heath’s Theorem, and why is it important?
1.14 What’s The Principle of Orthogonal Design?
1.15 What makes some JDs irreducible and others not?
1.16 What’s dependency preservation, and why is it important?
1.17 What’s the chase?
1.18 How many normal forms can you name?
[3] I remind you from the preface that throughout this book I use SQL and Relational Theory as an abbreviated form of reference to my book SQL and Relational Theory: How to Write Accurate SQL Code (2nd edition, O’Reilly, 2012).
[4] This observation is undeniably correct. However, one reviewer wanted me to add that the two meanings can be thought of as essentially the same concept at different levels of abstraction.
[5] For reasons that will become clear later, the values shown in Figure 1-1 differ in two small respects from those in other books of mine: The status for supplier S2 is shown as 30 instead of 10, and the city for part P3 is shown as Paris instead of Oslo.
[6] If you don’t know what a relvar is, for now you can just take it to be a table in the usual database sense. See Chapter 2 for further explanation.
[7] This definition is deliberately a little simplified (though it’s good enough for present purposes). A better one can be found in SQL and Relational Theory.
[8] Be warned, however, that other writers (a) use the terms logical design and physical design to mean something else and (b) use other terms to mean what I mean by them. Caveat lector.
[9] For obvious reasons I use T, not S, as an abbreviation for STATUS, here and throughout this book.
[10] You might notice another problem, too: The design can’t properly represent suppliers like supplier S5 who currently supply no parts at all. Such “update anomalies” are discussed in Chapter 3.
[11] Robert R. Brown: “Database Systems in Engineering: Key Problems, and Potential Solutions,” in the proceedings of a database symposium held in Sydney, Australia (November 15th-17th, 1984).
[12] However, I will at least give precise definitions of those familiar concepts for reasons of completeness. Since I’m sure they really are familiar, however, I’ll take the liberty of appealing to them from time to time even before we get to the definitions.
[13] The quote is from Codd’s paper “Extending the Database Relational Model to Capture More Meaning,” ACM TODS 4, No. 4, 1979 (the italics are mine). Ted Codd was, of course, the inventor of the relational model; he was also the person who first defined the concept of normalization in general, as well as the first three normal forms (1NF, 2NF, 3NF) in particular.
[14] The quote is from the preface to The Bertrand Russell Dictionary of Mind, Matter and Morals (ed., Lester E. Denonn; Citadel Press, 1993). I’ve edited it just slightly here.
Get Database Design and Relational Theory now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

