20
K5
25,002
33
K16
72,304
10
K1
13,003
12
K9
15,501
Anzahl KundeKostenID
14
K25
19,755
30
K33
55,507
13
K32
14,006
17
K30
34,409
29
K19
57,008
Zeilenorientiert Spaltenorientiert
6 13 14,00
5 14 19,75 K25
3 10 13,
1 12 15,50 K9 2
K32
20 25,00 K5
00 K1
Seite 1
4 33 72,30 K16
Seite 2
53 41 2 6
12 20987
10 30 29131433
17
Seite 1
13,0025,0015,50 72,
30 14,0019,75 55,50
57,00 34,40
Seite 2
K32 K33 K19
K1
K25K16K9 K5
Seite 3
K30
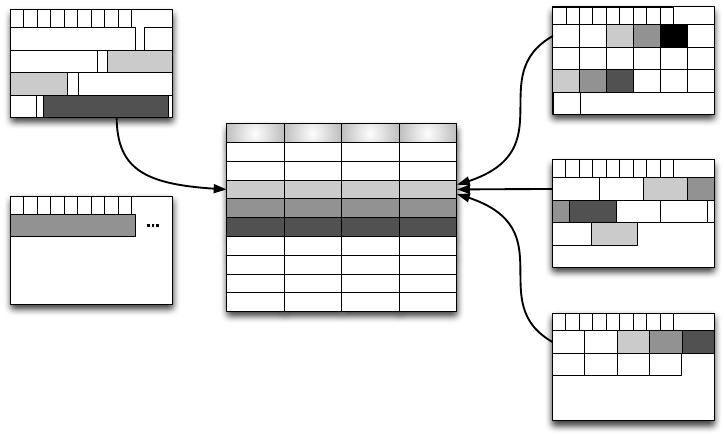
Abbildung 6.19: Konstruktion eines Tupels in der zeilenorientierten und in der spalten-
orientierten Speicherung
2. Der resultierende Vektor wird genutzt, um aus der zu aggregierenden Spal-
te die Werte herauszufiltern, die aggregiert werden.
Diese einfache Realisierung funktioniert natürlich nur, wenn genau ein aggre-
gierter Wert benötigt wird. Das folgende Beispiel verdeutlicht die Erweiterung
auf eine Gruppierung, kombiniert mit einer Aggregation.
Die Abbildungen 6.22 und 6.23 zeigen ein komplexeres Szenario, bei der ei-
ne Gruppierung mit einer Aggregation nach vorhergehender Selektion berech-
net wird. Bei der Abbildung 6.23 wird deutlich, dass bei der Rekonstruktion
eines Tupels eine Art positionaler Join benötigt wird, der Attributwerte aus
den einzelnen Spaltenvektoren über die Position kombiniert.
6.3.3 Speichervarianten in spaltenorientierter Datenhaltung
Konzeptionell ist die Speicherung von Spalten einer Tabelle einfach vorstellbar.
Intern gibt es natürlich mehrere Variationen der Speicherung.
6.3 Spaltenorientierte Datenhaltung 179
...
EF
EF
MD
MD
Ort
...
5
4
7
1
Umsatz
...
SELECT SUM (Umsatz)
FROM Filiale
WHERE Ort = 'MD'
σ
Ort = 'MD'
...
MD
MD
Ort
...
7
1
Umsatz
...
π
Umsatz
7
1
Umsatz
SUM
8
SUM(Umsatz)
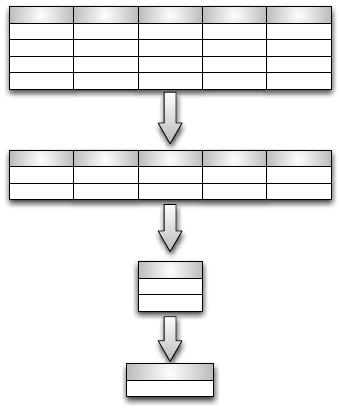
Abbildung 6.20: Anfragebearbeitung bei zeilenorientierter Speicherung
Speicherung als vertikale Partitionen
Eine direkte Umsetzung der spaltenorientierten Speicherung, die auch mit
klassischen relationalen Datenbanksystemen möglich ist, basiert auf einer ver-
tikalen Partitionierung mithilfe eines künstlichen Surrogatschlüssel (oder der
internen TID). Jede Attributspalte Att
_
i einer Tabelle Rel wird dann zu einer
binären Relation, die in SQL wie folgt definiert wäre:
CREATE TABLE PartitionAtt
_
i (
RelSurrogate Surrogattyp PRIMARY KEY,
Att
_
i Attributtyp
)
Zuerst muss dafür die Originaltabelle mit einem Surrogatschlüssel angerei-
chert werden. Die Attributtabellen werden dann mit dem Projektionsoperator
erzeugt. Die Originalrelation kann mit dem natürlichen Verbund rekonstruiert
werden.
Die SQL-Anweisungen sind hier nur zur Verdeutlichung angegeben. Die
Umsetzung in eine derartige Tabellendefinition erfolgt intern im System und
erfordert keine explizite SQL-Deklaration der Spaltentabellen durch den Be-
nutzer.
JBeispiel 6-8IFür eine konkretes Attribut Ort einer Tabelle Umsatz könnte
eine derartige Tabelle dann wie folgt aussehen:
CREATE TABLE PartitionUmsatzOrt (
180 6 Speicherung
EF
EF
MD
MD
Ort
2009
2010
2011
2010
Jahr
5
4
7
1
Umsatz
σ
Ort = 'MD'
1
0
1
0
Merge
7
1
Umsatz
SUM
8
Sum(Umsatz)
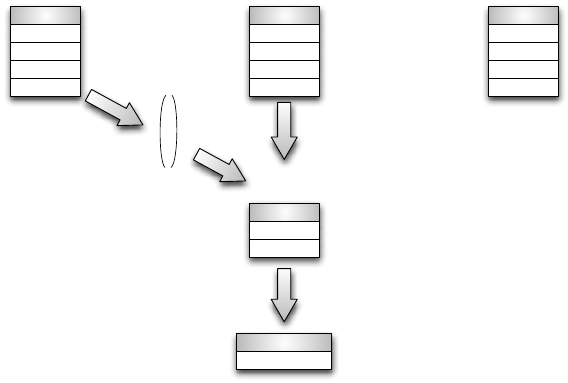
Abbildung 6.21: Anfragebearbeitung bei spaltenorientierter Speicherung
UnsatzSurrogate Surrogattyp PRIMARY KEY,
Ort VARCHAR(10)
)
Der Surrogattyp müsste dabei noch festgelegt werden. 2
Diese Art der Dekomposition entspricht dem DSM-Modell (Decomposed
Storage Model) aus [CK85]. Abbildung 6.24 zeigt eine DSM-Zerlegung.
Die DSM-Zerlegung ermöglicht die volle Nutzung der relationalen Techno-
logie. Ohne weitere Anpassung können Indexe definiert bzw. Optimierungen,
die auf TID-Listen basieren, genutzt werden.
Die Abbildung 6.25 zeigt die physische Speicherung unserer Produkttabelle
im DSM-Modell. Das Attribut SAdr bezeichnet hierbei den Surrogatschlüssel.
Speicherung ohne Surrogatschlüssel
Im Sinne der Speicherplatzoptimierung ist die DSM-Zerlegung nicht optimal,
da für jedes Attribut einmal die komplette Liste der Surrogatschlüssel gespei-
chert wird. Eine Speicherung der Listen von Werten ohne derartige Surro-
gatschlüssel benötigt deutlich weniger Speicherplatz.
Die Voraussetzung für eine derartige platzsparende Speicherung ist dabei,
dass in allen Attributlisten dieselbe Reihenfolge genutzt werden kann. Man
benötigt also beispielsweise eine stabile TID-Liste als Referenz für alle Attri-
butlisten.
Abbildung 6.26 verdeutlicht die physische Speicherung von Attributlisten.
6.3 Spaltenorientierte Datenhaltung 181

...
EF
EF
MD
MD
Ort ...
5
4
7
1
Umsatz...
2009
2010
2011
2010
Jahr
SELECT Ort, AVG (Umsatz)
FROM Filiale
WHERE
Jahr ≥ 2010
GROUP BY
Ort
σ
Jahr ≥ 2010
EF
MD
4
7
2010
2011
...
MD
Ort ...
1
Umsatz...
2010
Jahr
π
Ort,Umsatz
4
7
1
Umsatz
EF
MD
MD
Ort
Group By Ort
Avg
(Umsatz)
4EF
4
Umsatz
MD
Ort
Abbildung 6.22: Komplexere Anfrage bei zeilenorientierter Speicherung
Beim Vorliegen einer festen Reihenfolge ist eine weitere Optimierung mög-
lich. Gerade in DW-Systemen gibt es Spalten mit vielen Nullwerten. Hier kann
man ein Bit-Array als Kodierung der Null-Werte einsetzen. Die einzelnen At-
tributlisten beinhalten dann nur noch die Not-Null-Attributwerte.
Komprimierung
Sowohl das DSM-Modell als auch insbesondere die Speicherung als Attribut-
listen sind besonders gut geeignet, um Komprimierung einzusetzen. Grund für
eine bessere Kompressionsrate ist, dass im Gegensatz zu heterogenen Tupel-
feldern die Daten eines Attributs homogen sind. Sie haben nicht nur im Gegen-
satz zu beliebigen Tupelfeldern denselben Datentyp, sondern sind auch seman-
tisch derselben Eigenschaft zugeordnet, sodass in der Regel mehr Duplikate
auftreten als bei zufälligen Daten. Ein Beispiel sind Jahresangaben, die sich
naturgemäß auf wenige Jahre beschränken, auch wenn der genutzte Datentyp
wesentlich mehr Zahlen erlauben würde. Im Abschnitt 6.4.3 werden wir auf ei-
nige Komprimierungsverfahren eingehen, dort im Kontext von Hauptspeicher-
datenbanken.
Stonebraker et al. berichten in [SBÇ
+
07], dass bei zeilenorientierter Spei-
cherung typischerweise eine Kompressionsrate von 1:3 zu erreichen ist, wäh-
rend sich bei der spaltenorientierten Speicherung sich 1:10 erreichen lassen.
182 6 Speicherung

EF
EF
MD
MD
Ort
2009
2010
2011
2010
Jahr
5
4
7
1
Umsatz
1
0
1
1
Merge
4
7
1
Umsatz
EF
MD
MD
Ort
σ
Jahr ≥ 2010
GROUP BY Ort
AVG
(Umsatz)
4EF
4
Umsatz
MD
Ort
Abbildung 6.23: Komplexere Anfrage bei spaltenorientierter Speicherung
9,95
Preis
10,95
11, 9 5
9,90
8,55
ProdNr
1001
1002
1003
1005
1004
Dornfelder
Bezeichnung
Müller-Thurgau
Merlot
Pinot Noir
Riesling
SAdr
0x00
0x01
0x02
0x04
0x03
ProdNr
1001
1002
1003
1005
1004
SAdr
0x00
0x01
0x02
0x04
0x03
Dornfelder
Bezeichnung
Müller-Thurgau
Merlot
Pinot Noir
Riesling
SAdr
0x00
0x01
0x02
0x04
0x03
9,95
Preis
10,95
11, 9 5
9,90
8,55
Abbildung 6.24: DSM-Zerlegung
Das PAX-Modell als Kompromiss
Die DSM-Speicherung bietet sehr gute Performanz beim Auslesen einer Spalte
und bei der Nutzung von Komprimierung, ist aber potenziell sehr aufwendig
beim Lesen und Schreiben einzelner Tupel – die physische Clusterung erfolgt
ja gerade eben nicht nach den Tupeln.
Das PAX-Modell versucht einen Kompromiss, bei dem die Spalten gut kom-
primierbar zusammen gespeichert werden, und trotzdem eine physische Clus-
terung ganzer Tupel erfolgt. Als Motivation betrachten wir erneut die in Abbil-
dung 6.25 skizzierte physische Speicherung im DSM-Modell. Die Spaltenwerte
einer Spalte sind auf Seiten geclustert, aber jedes Tupel mit k Attributen ist
auf k Seiten verteilt.
6.3 Spaltenorientierte Datenhaltung 183
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

