Magdeburg
Ilmenau
Ilmenau
Magdeburg
Ort
2010
2010
2010
2010
Jahr
2341
4944
5543
4325
Umsatz
Guinness
Pinot Noir
Merlot
Merlot
Produkt
Abbildung 6.17: Spaltenorientierte Speicherung
deutlicht eine derartige spaltenorientierte Speicherung. Die Daten jedes einzel-
nen Attributs werden tupelübergreifend zusammen gespeichert. Von der spal-
tenorientierten Speicherung erhofft man sich folgende Vorteile:
• Eine typische Analyseanfrage in einem DW-System besteht aus einer Be-
reichsselektion sowie einer Aggregation von Kennzahlen über viele Tupel.
Derartige Anfragen können durch eine spaltenorientierte Speicherung sehr
gut unterstützt werden.
• Spaltenorientierte Speicherung erkauft die Beschleunigung bei Zugriffen
durch höhere Kosten beim Einfügen von Tupeln und dem Zugriff auf ein-
zelne Tupel. Beides ist in DW-Systemen nicht relevant.
• Spaltenorientierte Speicherung ermöglicht eine bessere Komprimierbar-
keit, da die Spalten homogenere Daten als Tupeldaten haben (sowohl be-
treffend der Datentypen als auch der Werte).
• Durch die sequentielle Speicherung der Spalten sind Scans besonders effi-
zient auszuführen. Einige Systeme verzichten sogar ganz auf Indexstruk-
turen zugunsten schneller Scans.
Eine spaltenorientierte Speicherung muss die Rekonstruierbarkeit der Tupel
sicherstellen, entweder durch eine feste Tupelreihenfolge oder durch ein Iden-
tifikationsattribut, das eine Rekonstruktion mit einem Verbund gewährleis-
tet [Lüb10]. Abbildung 6.18 verdeutlicht noch einmal grafisch die Konzepte der
zeilenorientierten gegenüber der spaltenorientierten Speicherung.
6.3.2 Operationen und Anfragen in spaltenorientierter Daten-
haltung
Einige der aus klassischen relationalen Datenbanken bekannten Operationen
auf Tabellen müssen für eine spaltenorientierte Datenhaltung überdacht bzw.
neu konzipiert werden, vergleiche z.B. die Arbeiten von Lübcke et al. [Lüb10,
LKS11b, LKS11a].
6.3 Spaltenorientierte Datenhaltung 177
3 10 13,00 K1
4 33
72,30 K16 5 14 19,75
K25
20
K5
25,002
33
K16
72,304
10
K1
13,003
12
K9
15,501
Anzahl KundeKostenID
14
K25
19,755
30
K33
55,507
13
K32
14,006
3
10
4 5
33 14 K1 K16
K25
Zeilenorientiert Spaltenorientiert
17
K30
34,409
29
K19
57,008
1 12 15,50 K9
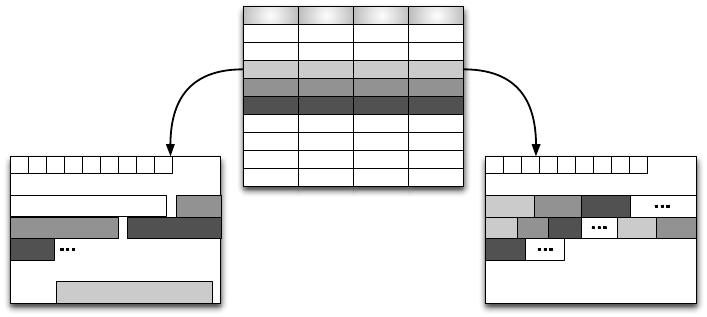
Abbildung 6.18: Zeilen- versus spaltenorientierte Speicherung
Tupel-Rekonstruktion
Eine neu hinzukommende Basisoperation in der spaltenorientierten Speiche-
rung ist die Tupelrekonstruktion. Jedes Tupel ist nun aufgeteilt in die Attribut-
werte, die separat gespeichert sind und im Bedarfsfall wieder zusammengesetzt
werden.
Abbildung 6.19 verdeutlicht die Aufgabe der Tupelrekonstruktion im Ver-
gleich zwischen einer zeilen- und einer spaltenorientierten Speicherung.
Anfragebearbeitung
Um den Unterschied in der Anfrageverarbeitung zu verdeutlichen, betrachten
wir eine einfache Anfrage, bei der eine Selektion über Dimensionsattribute mit
einer Aggregation gekoppelt wird.
Die Abbildung 6.20 verdeutlicht den typischen Ablauf bei der klassischen
zeilenorientierten Speicherung. In einem ersten Schritt werden die Tupel aus-
gewählt, die für die Anfrage benötigt werden. Dies kann mit einem Scan oder
durch Nutzung von Indexen erfolgen. Es folgt die Projektion auf die für das Er-
gebnis benötigten Attribute, gegebenenfalls eine Sortierung und die abschlie-
ßende Aggregation.
Abbildung 6.21 zeigt einen möglichen Ablauf bei der spaltenorientierten
Speicherung. Die direkte Variante – also erst Rekonstruktion aller Tupel und
anschließende Verarbeitung wie oben beschrieben – ist sicher nicht effizient.
Stattdessen wird wie folgt vorgegangen:
1. Die Selektionsbedingungen auf einzelnen Spalten werden genutzt, um je-
weils einen Bitvektor zu erzeugen, der die selektierten Tupel kennzeich-
net. Bei mehreren Selektionsbedingungen werden diese Vektoren analog
zu Bitmap-Indexen logisch kombiniert.
178 6 Speicherung
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

