Array-Speicherung: Probleme
Bei der Array-Speicherung treten einige Probleme auf, die man beachten muss.
Die Zahl der Plattenzugriffe kann bei einer ungünstigen Linearisierungsrei-
henfolge stark wachsen. Array-Speicherung verhält sich nicht symmetrisch be-
züglich der Reihenfolge der Dimensionen! Bei der Definition des Würfels muss
also die Dimensionsreihenfolge basierend auf den erwarteten Analyseprofilen
gewählt werden.
Da der gesamte Würfel ein Array bildet, müssen geeignete Caching-
Strategien gefunden werden, die es erlauben, Teile des Würfels im Cache zu
halten.
Ein weiteres Problem ist die Speicherung dünn besetzter Würfel, bei de-
nen also viele Zellen nicht mit einem Wert ungleich 0 belegt sind. Hier helfen
Komprimierungsverfahren (allerdings möglicherweise auf Kosten des effizien-
ten Direktzugriffs im Array).
6.1.3 Vergleich ROLAP und MOLAP-Speicherung
Wir haben nun schon mehrmals betont, dass sich Array- und relationale Spei-
cherung im Speicherverbrauch unterscheiden. Die relationale Speicherung be-
nötigt mehr Speicher, um eine Zelle zu speichern, da für jede gespeicherte Zel-
le ein Tupel mit Fremdschlüsseln in der Faktentabelle angelegt werden muss.
Im Gegenzug werden nicht belegte Zellen nicht gespeichert – wohl aber in der
Array-Speicherung, die ansonsten naturgemäß weniger Platz für die Speiche-
rung einer Zelle benötigt. Doch wie genau machen sich diese gegenläufigen Ef-
fekte bemerkbar?
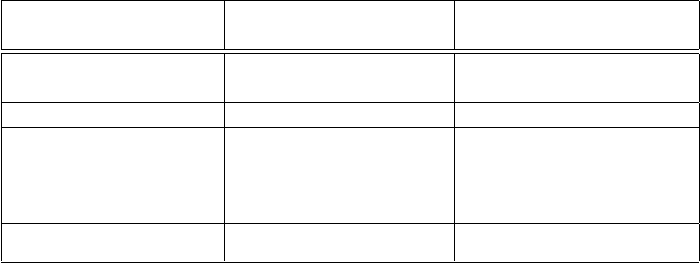
Array Relational
(Star-Schema)
Speicherung der Implizit Explizit
Koordinaten (Linearisierung) (redundant)
Leere Zellen . . . belegen Platz . . . belegen keinen Platz
Neue Klassifikations- Komplette Neue Zeile
knoten Reorganisation in Dimensionstabelle
Starkes Wachstum im Kaum Wachstum im
Speicherverbrauch Speicherverbrauch
Speicherverbrauch b ·
Q
n
i=1
d
i
b · M · (n + 1)
Tabelle 6.1: Vergleich Speicherverbrauch Array versus relational
Die Tabelle 6.1 gibt einen Überblick über die diesbezüglichen Eigenschaf-
ten der beiden Varianten. Interessant ist hierbei die vereinfachte Rechnung
160 6 Speicherung
des Speicherverbrauchs in der letzten Zeile. Die Konstante b bezeichnet den
Speicherbedarf eines Wertes, hier genutzt für den Bedarf der Speicherung des
Zelleninhalts und für die Größe der Fremdschlüssel in der Faktentabelle. d
i
be-
zeichnet die Anzahl der Dimensionselemente der Dimension i, und n die Anzahl
der Dimensionen.
Der Wert M ist die Anzahl der tatsächlich zu speichernden Fakten für
einen Füllgrad δ:
M = δ ·
n
Y
i=1
d
i
Ein Füllgrad δ = 0.1 bedeutet, dass neun von zehn Zellen mit einem Nullwert
(oder dem Wert 0, je nach Modellierung) belegt sind. Die Formeln begründen
sich wie folgt:
• In einem Array werden die reinen Zelldaten linearisiert gespeichert, so-
dass die Anzahl Zellen mal dem Speicherbedarf einer Zelle den Speicher-
verbrauch festlegt:
b ·
n
Y
i=1
d
i
In der Praxis kann dieser Wert durch eine komprimierte Speicherung noch
gesenkt werden.
• Bei der relationalen Speicherung kostet die Speicherung eines Tupels der
Faktentabelle b·(n+1). Gespeichert werden nur die belegten Zellen, sodass
der Füllgrad als Faktor hinzukommt:
b · (n + 1) · δ ·
n
Y
i=1
d
i
In realen DBMS kommt noch der Overhead der Speicherung des Tupels
hinzu, etwa die Speicherung eines TID-Wertes oder Verwaltungsinforma-
tionen für die Sperr- und Rechteverwaltung, sowie ein Zeitstempel, sodass
statt (n + 1) ein (n + 1 + v) stehen müsste, wobei v · b den Speicherbedarf
dieser Verwaltungsinformation pro Tupel bezeichnet.
Bei mehreren Kennzahlen k käme der Wert k bei der Array-Speicherung als
Faktor hinzu, während bei der relationalen Speicherung die Summe (n + 1) zu
(n + k) würde.
Aus den Formeln und Beispielrechnungen kann man ableiten, dass nur bei
sehr geringen Füllgraden die Array-Speicherung mehr Speicher benötigt als die
relationale Speicherung – insbesondere wenn man die Daten noch komprimie-
ren kann. Die tatsächliche Performance eines Data-Warehouse-Systems hängt
allerdings von vielen Faktoren ab, nicht nur vom Speicherbedarf. So muss be-
achtet werden, dass eine Indexierung für Bereichsanfragen in den unterschied-
lichen Varianten mit unterschiedlichem Aufwand zu realisieren ist. Auch kann
6.1 Speicherung des Datenwürfels: Array vs. Relationen 161
der Aufwand für das sequenzielle Lesen eines Teilwürfels sehr unterschiedlich
sein.
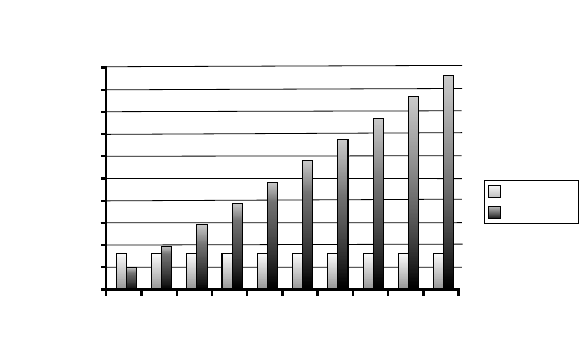
JBeispiel 6-3I Abbildung 6.4 zeigt einige Beispielwerte für den Vergleich des
Speicherbedarfs. Gezeigt wird der Bedarf für einen Datenwürfel mit fünf Di-
mensionen. Aufgrund der Berechnungen des Speicherbedarfs schneiden sich
die Kurven bei einem Füllgrad von einem Sechstel.
0
50.000.000
100.000.000
150.000.000
200.000.000
250.000.000
300.000.000
350.000.000
400.000.000
450.000.000
500.000.000
10 20 30 40 50 60 70 80 90 100
Füllgrad in %
Speicherplatz nach Füllgrad, b=8, k=100, n=5
Array
Relational
Abbildung 6.4: Speicherbedarf für einen Würfel mit fünf Dimensionen
2
JBeispiel 6-4I In Abbildung 6.5 werden dieselben Angaben für einen Daten-
würfel mit nur drei Dimensionen grafisch dargestellt. Wie erwartet verschiebt
sich der Schnittpunkt weiter nach rechts, da weniger Dimensionen auch weni-
ger Speicherbedarf bei der Speicherung einzelner Fakten in der Faktentabelle
bedeuten.
2
Grenzen der multidimensionalen Speicherung
Die multidimensionale Speicherung in einem Array scheint auf den ersten Blick
die naheliegende Speicherung von Datenwürfeln zu sein. Trotzdem ist die rela-
tionale Speicherung weit verbreitet. Die Hauptargumente gegen eine multidi-
mensionale Speicherung sind die folgenden:
• Gerade bei hohen Dimensionszahlen treten aufgrund der dann oft dünn
besetzten Datenräume Skalierbarkeitsprobleme auf.
162 6 Speicherung
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

