Datenqualität spielt einen stetig wachsenden Anspruch in den Entschei-
dungsprozessen aber auch im operativen Betrieb. Viele Probleme können durch
technische Maßnahmen bereits vorab verhindert werden. Jedoch müssen hier-
zu Anwender und Systembetreiber ihre Anforderungen in einem kontinuier-
lichen Prozess überprüfen und anpassen. Heterogene Quellen erfordern jedoch
auch weiterhin eine Überwachung und Sicherstellung der Datenqualität im Da-
ta Warehouse. Das wachsende Datenvolumen und neue Quellen erfordern eine
konsequente und effiziente Nutzung von Ressourcen. Neue Techniken und Al-
gorithmen müssen daher für die Datenbereitstellung genutzt werden.
4.2 Der ETL-Prozess
Der Extraktions-, Transformations- und Ladeprozess (ETL-Prozess) dient dazu,
Daten aus der heterogenen Quelllandschaft (z.B. aus operativen Datenbanken,
Anwendungsdateien oder dem Internet) im Data Warehouse bereitzustellen.
Prinzipiell kann dieser komplexe Prozess in zwei Schritte unterteilt werden. Im
ersten Schritt werden die Daten aus den Quellen in den Datenbeschaffungsbe-
reich geladen. Hierbei erfolgt eine Extraktion der Daten aus den Quellen, das
Erkennen und Erstellen von differenziellen Updates und das Erstellen von La-
dedateien. Im zweiten Schritt werden die Daten aus dem Datenbeschaffungs-
bereich in die Basisdatenbank überführt. Dies beinhaltet die Datenbereinigung
(Data Cleaning) und auch das Tagging der Daten. Tagging bedeutet in diesem
Zusammenhang die Anreicherung der Daten um Metadaten bzw. beschreibende
Informationen. Dieser Schritt garantiert die Erstellung eines integrierten Da-
tenbestandes. Der ETL-Prozess ist dafür verantwortlich, dass das Data Ware-
house kontinuierlich mit Daten versorgt wird. Es ergeben sich hier zwei un-
terschiedliche Stufen für den Prozess: die Initialbefüllung des Data Warehouse
und die kontinuierliche Datenversorgung. In beiden Stufen muss eine Siche-
rung der DWH-Konsistenz bezüglich der Datenquellen erfolgen. Prinzipiell ste-
hen sich zwei wichtige Anforderungen im ETL-Prozess gegenüber: Sperrzeiten
müssen minimiert werden, um eine hohe Verfügbarkeit des Data Warehouse
in den Analyseprozessen zu gewährleisten; eine hohe Datenqualität im Data
Warehouse muss sichergestellt sein, damit die Analysen auch zu tragfähigen
Entscheidungen führen können. Somit sind effiziente Methoden wie auch rigo-
rose Prüfungen der Daten essenziell.
Der ETL-Prozess ist im Data Warehouse häufig der aufwendigste Teil. Dies
liegt in der Vielzahl der Quellen begründet, die innerhalb eines Unternehmens,
aber auch über die Unternehmensgrenzen hinaus für das Data Warehouse ge-
nutzt werden. Zugleich weisen die Quellen eine große Heterogenität sowohl hin-
sichtlich ihrer Anbindung an das Data Warehouse als auch für die Datendar-
stellung auf. Ebenso steigt das Datenvolumen kontinuierlich an, das durch den
ETL-Prozess verwaltet werden muss. Nicht nur operative Datenquellen liefern
4.2 Der ETL-Prozess 97
stetig neue Daten, sondern auch die Verwendung von Sensoren oder die Einbe-
ziehung des Internet sind Treiber für das massive Datenwachstum. All dies hat
Auswirkungen auf die Transformationen der Daten. Die Transformation stellt
somit einen hochgradig komplexen Vorgang dar, sowohl für die Schema- und In-
stanzintegration als auch für die Bereinigung und Zusammenführung der Da-
ten. Aufgrund der Heterogenität und Komplexität existiert kaum eine durch-
gängige Methoden- und Systemunterstützung, jedoch gibt es auf dem Markt
eine Vielzahl von ETL-Werkzeugen.
Im Folgenden werden wir auf die drei Hauptphasen Extraktion, Transfor-
mation und Laden genauer eingehen. Die Extraktionsphase stellt dabei die Se-
lektion eines Ausschnitts der Daten aus den Quellen und die Bereitstellung
dieser Daten für die Transformationsphase dar. In der Transformationsphase
werden Anpassungen der Quelldaten an die im Data Warehouse vorgegebenen
Schema- und Datenqualitätsanforderungen durchgeführt. In der Ladephase er-
folgt das physische Einbringen der Daten aus dem Datenbeschaffungsbereich
in das Data Warehouse. Hier können ebenfalls notwendige Aggregationen für
das Befüllen des Datenwürfels integriert sein.
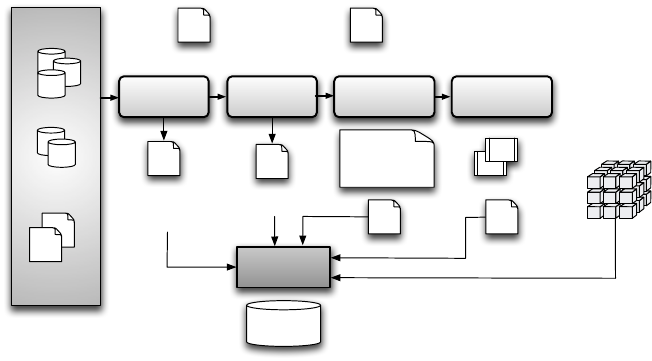
Quelldaten-
analyse
Metadaten-
Management
Repository
OLTP
Legacy
Externe
Quellen
Auswahl der
Objekte
Erstellen der
Transformation
Erstellen der
ETL-Routinen
Analyse-
bedarf
Datenmodell und
Konventionen
Dokumentation,
operativer
Datenkatalog
Regelwerk für
Datenqualität
Transfor-
mations-
regeln
Erfolgskriterien
für Laderoutinen
ETL-Jobs
Abbildung
Schlüsseltransf.
Normalisierung
DWH
Datenquellen
Abbildung 4.8: ETL-Prozess und Komponenten
Abbildung 4.8 stellt den ETL-Prozess schematisch dar. Ausgangspunkt
für die Data-Warehouse-Daten sind externe Quellen, wie OLTP-Datenbanken
oder Legacy-Systeme. Diese Daten müssen in einem ersten Schritt analysiert
werden. Anschließend werden die für die Arbeiten im Data Warehouse rele-
vanten Daten ausgewählt. An dieser Stelle wird gleichzeitig festgelegt, wel-
che Anforderungen hinsichtlich der Datenqualität existieren. Dann können die
Transformationsaufgaben definiert werden. Eine Aufteilung der in einzelnen
ETL-Routinen ermöglicht eine weitgehend automatisierte Beladung des Data
98 4 Extraktions-, Transformations- und Ladeprozess
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

