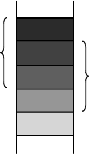
3. Wähle sequenziell aus der Liste das Vergleichselement.
4. Führe den Vergleich des selektierten Elements mit allen Elementen des
Fensters w durch.
w
w
Abbildung 4.6: Sortierte Nachbarschaft mit Fenster w
Dies führt zu einem Gesamtaufwand O(n · log(n)) und O(n · w), der sich
wie folgt zusammensetzt: Schlüsselerzeugung: O(n), Sortieren: O(n·log(n)) und
Vergleichen: O((n/w) · (w
2
)) = O(n · w).
Dieser Gewinn in der Reduktion des Aufwands gegenüber dem naiven An-
satz ist jedoch mit einer Verringerung in der Genauigkeit der Objektidentifika-
tion verbunden. Dies liegt darin begründet, dass das Sortierkriterium stets ein
Attribut aus der Gesamteigenschaft der Attribute der Objekte bevorzugt. Hier
müssen somit wieder domänenspezifische Fragen geklärt werden, ob z.B. die
ersten Buchstaben wichtiger für die Identität sind als die letzten, ebenso lässt
sich die Frage stellen, ob der Nachname „genauer“ ist als die Hausnummer.
Diese Vergleichsfragen lassen sich beliebig fortsetzen.
Die Genauigkeit kann durch die Vergrößerung des Fensters zwar erhöht
werden, jedoch geht dies einher mit der Erhöhung des Vergleichsaufwands. Zu-
sätzlich bleibt die Dominanz eines Attributes erhalten.
Multi-Pass-Techniken
Bei der Multi-Pass-Technik wird nicht nur ein Schlüssel genutzt, sondern meh-
rere unterschiedliche Schlüssel. Die transitive Hülle der Matches ergibt die
Vergleichsmenge für jeden einzelnen Wert, wobei eine maximale Größe der Ver-
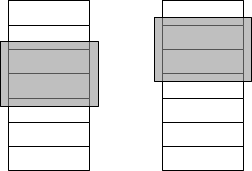
gleichsmenge häufig festgelegt wird. Die in Abbildung 4.7 dargestellte Transi-
tivität bedeutet: Ergibt ein Vergleich von A und B ein Match und ebenso ein
Match von B und C, erfolgt auch eine Annahme, dass A mit C gematcht ist.
4.1.3 Vergleichsfunktionen
Neben der Reduktion des Suchraumes haben für die effiziente Identifikati-
on von Duplikaten auch die Vergleichsfunktionen eine hohe Bedeutung. Häu-
fig werden Vergleichsfunktionen in der Praxis für metrische Daten durch
90 4 Extraktions-, Transformations- und Ladeprozess
A
B
C
B
C
A
Abbildung 4.7: Multi-Pass-Technik: 1. Lauf A matcht B, 2. Lauf B matcht C
die Euklidische Distanz oder aus der Minkowski-Familie herangezogen. Für
eine detaillierte Übersicht siehe z.B. aus dem Bereich der Multimedia-
Datenbanken [Sch05].
Für Zeichenketten existieren ebenfalls eine Vielzahl von Vergleichsfunk-
tionen. Typische Vertreter sind:
• Edit-Distanz
• q-Gramme
• Soundex und Kölner Phonetik
• Jaro- und Jaro-Winkler-Distanz
Wir werden im Folgenden diese Vertreter genauer betrachten.
Edit-Distanz
Die Edit-Distanz [Dam64], auch Levensthein-Distanz genannt (vgl. [Lev66]),
ermittelt die Operationen, die notwendig sind, um eine Zeichenkette A in die
Zeichenkette B zu überführen. Die Operationen sind Einfügen, Löschen und
Ändern einzelner Buchstaben, und alle Operationen sind gleich gewichtet.
JBeispiel 4-3I So beträgt die Edit-Distanz zwischen Qualität und Quantität
zwei:
edit_distance(„Qualität“, „Quantität“) = 2
→ update(3,“n“)
→ insert(4,“t“)
2
Um ein Matching der zu vergleichenden Objekte zu ermitteln, kann bei-
spielsweise das folgende SQL-Statement genutzt werden:
SELECT P1.Bezeichnung, P2.Bezeichnung
FROM Produkt P1, Produkt P2
WHERE edit
_
distance(P1.Name, P2.Name) <= 2
4.1 Qualitätsaspekte 91
Die Funktion edit
_
distance(String
1
, String
2
) kann dabei durch eine vom
Nutzer definierte Funktion beschrieben werden, wie sie in Algorithmus 4.1 be-
schrieben ist. Für eine Java-Implementierung der Levensthein-Distanz siehe
auch [SS14].
Input : Zeichenkette
1
String
1
der Länge m, Zeichenkette
2
String
2
der
Länge n,
Result : Distanzmass d[String
1
, String
2
]
/
*
∀i, j d[i, j] hat die Levensthein-Distanz für die ersten i Zeichen
von String
1
und die ersten j Zeichen von String
2
*
/
1 Initialisiere d[0 . . . m, 0 . . . n]
2 for i ← 0 to m do
3 d[i, 0] ← i /
*
Entfernung jeder erster Zeichenkette von String
1
zu einer leeren Zeichenkette
*
/
4 end
5 for j ← 0 to n do
6 d[0, j] ← j /
*
Entfernung jeder erster Zeichenkette von String
2
zu einer leeren Zeichenkette
*
/
7 end
8 for j ← 1 to n do
9 for i ← 1 to m do
10 if String
1
[i] = String
2
[j] then
11 d[i, j] ← d[i − 1, j −1] // Keine Operation notwendig
12 else
13 d[i, j] ← minimum (d[i − 1, j] + 1, // Löschoperation
14 d[i, j − 1] + 1 // Einfügeoperation
15 d[i − 1, j − 1] + 1) // Ersetzung
16 end
17 end
18 end
19 end
20 return d[String
1
, String
2
];
Algorithmus 4.1: Berechnung der Levensthein-Distanz
q-Gramme
Ein q-Gramm ist die Menge aller Zeichenketten der Länge q einer gegebenen
Zeichenkette. In der Literatur findet sich häufig auch der Begriff n-Gramm,
siehe hierzu u.a. [SS14]. Hierbei muss gelten, dass die Länge der zu untersu-
92 4 Extraktions-, Transformations- und Ladeprozess
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

