Datenbanksystemfunktionalitäten genutzt werden, um inkonsistente und ver-
altete Daten zu vermeiden. Hierzu zählt beispielsweise die Verwendung von
Sichten.
4.1.1 Der Datenbereinigungsprozess
Aufgrund unzureichender Informationen oder aufgrund von zeitlichen Restrik-
tionen wird in der Praxis häufig die vollständige Möglichkeit der Definition hin-
reichender Metadaten nicht genutzt. So fehlen diese Metadaten, z.B. Integri-
tätsbeziehungen in Datenbanksystemen. Aber auch Eingabefehler, z.B. durch
sprachliche Missverständnisse oder Unkenntnisse, erfolgen oftmals im hekti-
schen Alltagsgeschäft. Eine weitere Herausforderung stellt die Heterogenität
der Systemlandschaft und der damit verbundenen Daten dar. So sind aufgrund
gewachsener IT-Strukturen häufig Systeme unterschiedlicher Anbieter, aber
auch mit technisch bedingten Restriktionen, im Einsatz.
Das Data Warehouse soll diese heterogene Infrastrukturlandschaft zusam-
menführen und hinsichtlich der Daten den Single-Point-of-Truth darstellen.
Dies bedeutet, dass bei der Zusammenführung ein hoher Aufwand notwendig
ist, um sowohl die Schemata zusammenzuführen als auch die Daten in einen
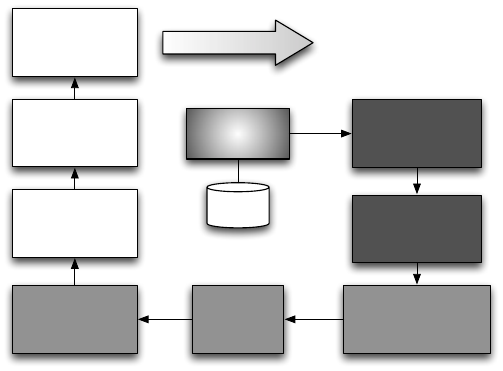
ganzheitlichen und konsistenten Zustand zu überführen. Wie in Abbildung 4.2
gezeigt, wird oftmals ein dreistufiger Prozess bestehend aus den Phasen Da-
ta Profiling, Data Cleaning und Transformation im Datenbereinigungsbereich
durchgeführt, um die Datenqualität zu erhöhen.
Sammlung/
Auswahl
DQ-Probleme
identifizieren/
quantifizieren
Fehlerarten/
-ursachen
erkennen
Standardisierung/
Normalisierung
Fehler-
korrektur
Duplikat-
erkennung und
Merging
Aggregation/
Feature-
Extraktion
Dimensions-
reduktion/
Sampling
Diskretisierung
Data Profiling
Data Cleaning
Transformation
Nutzung
Abbildung 4.2: Phasen der Datenbereinigung
84 4 Extraktions-, Transformations- und Ladeprozess
Das Data Profiling erfolgt überwiegend in der Konzeptionsphase des Data
Warehouses und der ETL-Prozesse. Es dient dazu, einen Überblick und Ver-
ständnis des Aufbaus der Datenquellen zu erlangen und inhärente potenzielle
Fehler zu erkennen. Aufgrund des erschwerten Zugriffs auf die Metadaten der
Quellen und ggf. von Fehlinterpretationen werden wir im Folgenden diese Me-
tadaten nicht für die Analyse heranziehen.
Die Phase des Data Profiling umfasst die Identifikation und Quantifizie-
rung von Datenqualitätsproblemen. Dafür werden der Datentyp und der Wer-
tebereich ermittelt, eine Varianzbestimmung und eine Überprüfung auf Null-
werte und die Eindeutigkeit der Wertausprägungen durchgeführt. Ebenfalls ist
eine Musteranalyse, z.B. auf das Datenformat, empfehlenswert, um Ähnlichkei-
ten und Regeln innerhalb der Daten zu identifizieren. Diese Analysen erfolgen
auf Inhalt und Struktur einzelner Attribute. Für die Abhängigkeit von Attribu-
ten wird zwischen Intra- und Inter-Relationsebene unterschieden. So können
innerhalb einer Relation „unscharfe Schlüssel“ identifiziert, funktionale Abhän-
gigkeiten, potenzielle Primärschlüssel, aber auch „unscharfe Abhängigkeiten“
aufgedeckt werden. Diese Analyse ist notwendig, wenn keine expliziten Integri-
tätsbeziehungen spezifiziert sind. Auf Inter-Relationenebene ist es erforderlich,
Redundanzen und Fremdschlüsselbeziehungen zu ermitteln.
Häufig werden Erwartungen an bestimmte Attribute gestellt, z.B. hat
die Geschlechtsausprägung die Kardinalität von zwei. Daher ist ein Soll-Ist-
Vergleich der Kardinalitäten hilfreich, um Transformationsregeln zu identifi-
zieren. Zusätzlich können Statistiken, wie Anzahl der NULL-Werte, Minimum,
Maximum und Standardabweichung hilfreiche Informationen über die Daten
liefern.
Eingabefehler sind hingegen schwerer zu ermitteln. Oft ist die manuelle
Überprüfung sortierter Daten die einzige Möglichkeit. Es lassen sich jedoch
auch Ähnlichkeitsmaße, vergleiche Abschnitt 4.1.3, nutzen. Mittels der Identi-
fikation von Mustern in den Daten, z.B. durch eine unterstützende Clusterana-
lyse, wird die Aufdeckung von Fehlern unterstützt. Die Erkennung von Dupli-
katen ist sowohl innerhalb einer Relation als auch über unterschiedliche Rela-
tionen oder Systeme notwendig. Wir gehen in Abschnitt 4.1.2 detaillierter auf
die Duplikaterkennung ein. Eine ausführliche Darstellung der Duplikaterken-
nung findet sich in [LN06] und [NH10].
Das Data Profiling dient dem Erkennen und gleichzeitig der Erstellung von
Regeln für das Beseitigen von Inkonsistenzen, Widersprüchen und Fehlern in
den Datenbeständen. Hiermit wird das Ziel der Qualitätsverbesserung verfolgt.
Ein mögliches Vorgehensmodell nach [BL08] ist in Abbildung 4.3 dargestellt.
Das Modell unterteilt das Data Profiling in die Überprüfung der Gültigkeit ein-
zelner und mehrerer Werte. Einzelne Werte können in der Überprüfung der
Spalten oder einer Abhängigkeitsanalyse zwischen Spaltenausprägungen er-
folgen.
4.1 Qualitätsaspekte 85
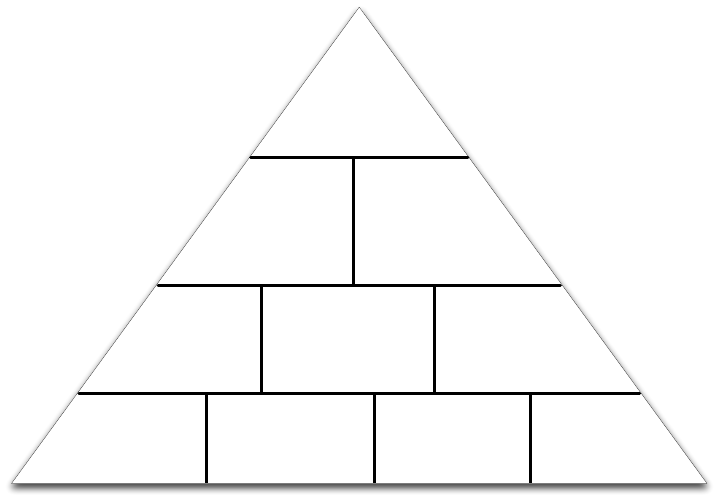
Regelbasierte Analyse
Beziehungsanalyse
Abhängigkeitsanalyse
Spaltenanalyse
Gültigkeit einzelner Werte
Gültigkeit mehrer Werte
Konsistenz
mittels regel-
basierter Analyse
Geschäfts- und
Datenregeln (Defekte)
Referenzielle
Integrität
Integritäts-
verletzungen,
Waisen (Orphans),
Kardinalitäten
Korrektheit
mittels statis-
tischer Kontrolle
Min, Max, Mittel,
Median, Standardab-
weichung, ...
Konsistenz
Datentyp-,
Feldlängen- und
Wertebereichs-
konsistenzen
Schlüssel-
eindeutigkeit
Eindeutigkeit der
Primär- bzw.
Kandidatenschlüssel
Redundanzfreiheit
Normalisierungsgrad
(1.,2. und 3. NF),
Duplikatprüfung
Eindeutigkeit
Analyse der Metadaten
Vollständigkeit
Füllgradanalyse der
Entitäten und Attribute
Genauigkeit
Analyse der Stelligkeiten
(Gesamt- und Nach-
kommastellen für
numerische Attribute)
Einheitlichkeit
Formatanalyse (für
numerische Attribute,
Zeiteinheiten und
Zeichenketten)
Abbildung 4.3: Datenqualität und Datenbereinigung nach [BL08]
Abbildung 4.3 stellt ein Vorgehen im Data Profiling dar, das in zwei we-
sentliche Teile untergliedert ist. Einerseits erfolgt die Überprüfung einzelner
Werte in einer Spalten- und Abhängigkeitsanalyse. Zur Spaltenanalyse gehö-
ren die Überprüfung der Metadaten auf Eindeutigkeit sowie die Genauigkeit
der jeweiligen Werte. Die Füllgradanalyse zählt Nullwerte und die Formatana-
lyse gibt Auskunft über die Einheitlichkeit der Zellwerte. In der Abhängigkeits-
analyse stehen Fragen der Konsistenz, z.B. hinsichtlich der Wertebereiche und
Feldlängen, Fragen der Schlüsseleindeutigkeit und eine Überprüfung auf Red-
undanzen, d.h. auch die Aufdeckung von Duplikaten. Der zweite Teil überprüft
die Datenqualität mehrerer Werte. Hierzu zählen in der Beziehungsanalyse,
d.h. der Überprüfung über mehrere Relationen hinweg, die referenzielle In-
tegrität und die Überprüfung der Daten auf Korrektheit mittels statistischer
Funktionen. Abschließend erfolgt eine regelbasierte Analyse, indem auf Defek-
te bezüglich von Geschäftsregeln getestet wird.
Nach der Identifikation von Datenfehlern und dem Ableiten notwendiger
Maßnahmen erfolgt die Phase des Data Cleaning. Diese wird in der Literatur
auch als Data Cleansing oder Data Scrubbing bezeichnet. Da die Datenqualität
einen hohen und unmittelbaren Einfluss auf die Entscheidungsqualität hat, ist
86 4 Extraktions-, Transformations- und Ladeprozess
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

