Hierbei werden nur drei Joins benötigt, wobei die Anzahl auch unabhängig von
der Länge der Aggregationspfade ist.
Insgesamt lassen sich folgende Vorteile des Star-Schemas identifizieren:
• einfache Struktur und damit vereinfachte Anfrageformulierung,
• einfache und flexible Darstellung von Klassifikationshierarchien als Spal-
ten in Dimensionstabellen,
• effiziente Anfrageverarbeitung innerhalb einer Dimension, da keine Join-
Operation notwendig sind.
Allerdings trifft dies nur zu, wenn die Dimension tatsächlich vergleichsweise
wenige Daten enthalten und selten geändert werden. Umfasst eine Dimension
dagegen viele Ebenen und wird oft geändert (wie z.B. eine Kundendimension),
so ist ein Snowflake-Schema eventuell besser geeignet.
Natürlich lassen sich Star- und Snowflake-Schema auch problemlos in ei-
ner Mischform kombinieren, indem einzelne Dimensionen entweder normali-
siert oder denormalisiert wird. Entscheidungskriterien sind hierbei:
• Änderungshäufigkeit der Dimensionen: Durch Normalisierung im Snow-
flake-Schema kann der Pflegeaufwand reduziert werden.
• Anzahl der Klassifikationsstufen einer Dimension: Mehr Klassifikations-
stufen führen im Star-Schema zu größeren Redundanzen.
• Anzahl der Dimensionselemente: Bei vielen Elementen einer Dimension
auf niedrigster Klassifikationsstufe kann durch Normalisierung Speicher-
platz gespart werden.
3.3.5 Fact-Constellation-Schema und Galaxie-Schema
Neben den Basiskennzahlen lassen sich auch vorberechnete Aggregate in der
Faktentabelle als Kennzahlen abspeichern, die dann nur abgefragt und nicht
jedes Mal neu berechnet werden müssen. Ein Beispiel hierfür ist die aggregier-
te Anzahl an Verkäufen für jeden Tag und jede Filiale pro Produktgruppe bzw.
Produktkategorie. Dieses Aggregat kann als Tupel in der Faktentabelle Verkauf
abgespeichert werden, muss dazu jedoch auf geeignete Dimensionswerte ver-
weisen.
Im Fall eines Star-Schemas wird dazu in jeder Dimensionstabelle ein spe-
zielles Attribut Stufe eingeführt, über das die Aggregations- bzw. Hierarchie-
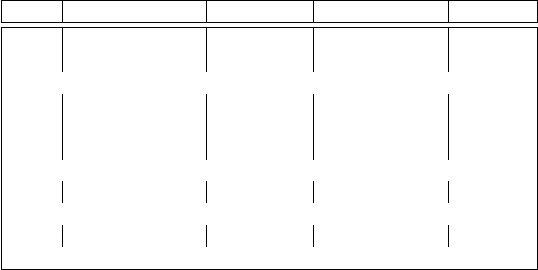
ebene identifiziert werden kann. In Abbildung 3.14 ist dies für die Dimension
Produkt unseres Beispiels illustriert: Stufe = 0 bezeichnet die Detaildaten, Stu-
fe = 1 die Produktgruppen sowie Stufe = 2 die Produktkategorien.
3.3 Relationale Umsetzung 61
P
_
ID P
_
Bezeichnung P
_
PGruppe P
_
PKategorie P
_
Stufe
142 Merlot Wein Getränke 0
143 Chardonnay Wein Getränke 0
. . .
100 NULL Wein Getränke 1
271 Guinness Bier Getränke 0
281 Radler Bier Getränke 0
. . .
200 NULL Bier Getränke 1
. . .
900 NULL NULL Getränke 2
. . .
Abbildung 3.14: Dimensionstabelle Produkt für Summentabellen
Die Stufe-Attribute dienen aber nicht nur der Kennzeichnung der Ebene,
sondern müssen auch bei Anfragen verwendet werden, um Mehrfachzählung
zu vermeiden. Die folgende Anfrage demonstriert dies anhand der Ermittlung
der Verkaufszahlen der Produktgruppe Wein:
SELECT O
_
Filiale, YEAR(Z
_
Datum), SUM(V
_
Anzahl)
FROM Verkauf, Ort, Produkt, Zeit
WHERE V
_
Produkt
_
ID = P
_
ID AND V
_
Zeit
_
ID = Z
_
ID AND
V
_
Ort
_
ID = O
_
ID AND
P
_
Produktgruppe = ’Wein’ AND P
_
Stufe = 1
GROUP BY O
_
Filiale, YEAR(Z
_
Datum)
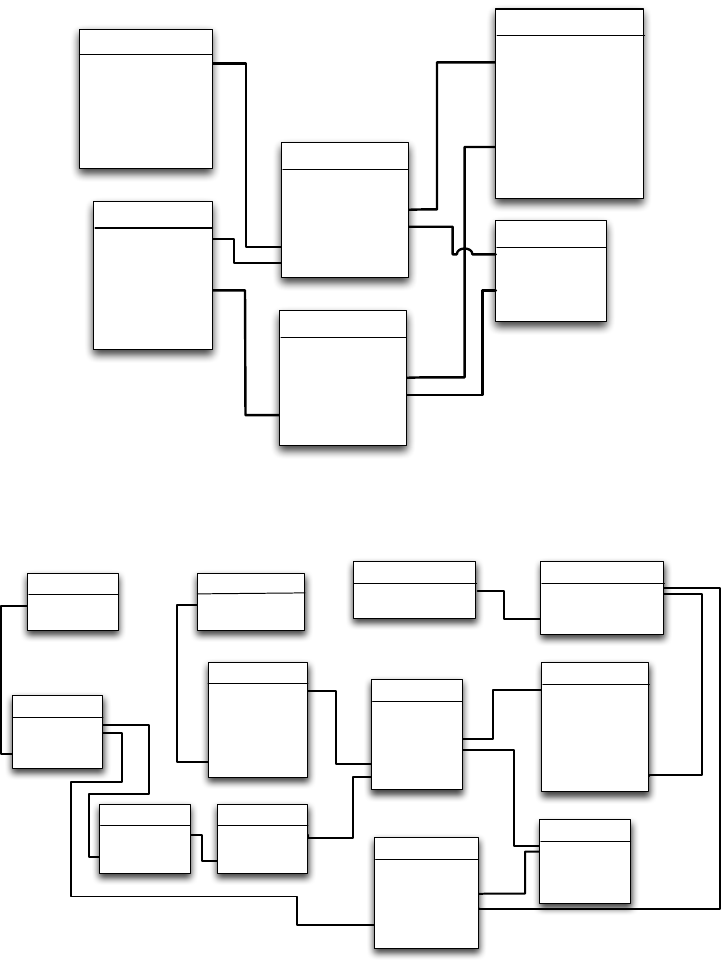
Ein alternativer Ansatz ist das Fact-Constellation-Schema. Hierbei werden
die Aggregate in eine oder mehrere separate Faktentabellen (sogenannte Sum-
mentabellen) ausgelagert. In der Summentabelle wird dazu als Fremdschlüssel
direkt auf die Attribute der jeweiligen Hierarchieebene in der Dimensiontabel-
le verwiesen – sinnvollerweise führt man dafür eindeutige Schlüssel ein, wie
dies in Abbildung 3.15 für die Dimensionen Ort, Produkt und Zeit dargestellt
ist, um eine Summentabelle Summe
_
Verkauf verwalten zu können. Auf die Stufe-
Attribute kann dabei verzichtet werden.
Ein ähnlicher Ansatz kann auch im Snowflake-Schema eingesetzt werden.
Da hier die Dimensionstabellen normalisiert vorliegen, kann von Summenta-
bellen direkt auf die Tabelle mit der benötigten Hierarchieebene verwiesen wer-
den. Es ist dabei nicht einmal notwendig, dass alle Fakten- bzw. Summentabel-
len mit den gleichen Dimensionstabellen verknüpft werden (Abbildung 3.16).
Diese Art eines Schemas wird auch Galaxie-Schema oder Multi-Faktentabellen-
Schema genannt.
62 3 Modellierung von Data Warehouses
Zeit
Z_ID
Z_Datum
Z_Monat_ID
Z_Monat
1
*
1
1
1
*
*
*
Produkt
P_ID
P_Bezeichnung
P_Verkaufspreis
P_Einkaufspreis
P_Rabatt
P_Steuern
P_PGruppe_ID
P_Produktgruppe
P_Produktkategorie
Verkauf
V_Anzahl
V_Kanal
V_Produkt_ID
V_Zeit_ID
V_Kunden_ID
V_Ort_ID
Kunde
K_ID
K_Name
K_Wohnort
K_Strasse
K_Geschlecht
K_Kundengruppe
Ort
O_ID
O_Filiale
O_Stadt
O_BLand_ID
O_Bundesland
O_Land
*
Summe_Verkauf
SV_Anzahl
SV_Kanal
SV_PGruppe_ID
SV_Monat_ID
SV_BLand_ID
1
1
1
*
*
Abbildung 3.15: Fact-Constellation-Schema
1
*
1
1
1
*
*
*
Produkt
P_ID
P_Bezeichnung
P_Verkaufspreis
P_Einkaufspreis
P_Rabatt
P_Steuern
P_PGruppe_ID
Verkauf
V_Anzahl
V_Kanal
V_Produkt_ID
V_Zeit_ID
V_Kunden_ID
V_Filial_ID
Kunde
K_ID
K_Name
K_Wohnort
K_Strasse
K_Geschlecht
K_KGruppe_ID
Filiale
F_ID
F_Filiale
F_Stadt_ID
Stadt
S_ID
S_Name
S_BLand_ID
Bundesland
B_ID
B_Name
B_Land_ID
Land
L_ID
L_Name
Kundengruppe
KG_ID
KG_Bezeichnung
Produktgruppe
PG_ID
PG_Bezeichnung
PG_PKategorie_ID
Produktkategorie
PK_ID
PK_Bezeichnung
1
1
*
*
*
*
*
*
1
1
1
1
*
Summe_Verkauf
SV_Anzahl
SV_Kanal
SV_Monat_ID
SV_PGruppe_ID
SV_BLand_ID
*
*
1
Zeit
Z_ID
Z_Datum
Z_Monat_ID
Z_Monat
1
1
Abbildung 3.16: Galaxie-Schema
3.3 Relationale Umsetzung 63
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

